蝴蝶传媒网站推广大连seo顾问
1.DeepKE 是一个开源的知识图谱抽取与构建工具,支持cnSchema、低资源、长篇章、多模态的知识抽取工具,可以基于PyTorch实现命名实体识别、关系抽取和属性抽取功能。同时为初学者提供了文档,在线演示, 论文, 演示文稿和海报。
2.下载对应的demo代码
3.准备环境
conda create -n deepke-llm python=3.9
conda activate deepke-llmcd example/llm
pip install -r requirements.txtpip install ujson4.demo目录介绍

我们直接运行demo.py,就会出现三个选项,每个选项对应一个文件夹
NER(命名实体识别)- 选项1:
基础模型:bert-base-chinese
任务模型:需要从 DeepKE 下载预训练的 NER 模型
位置:neme_entity_recognition/checkpoints/
RE(关系抽取)- 选项2:
基础模型:bert-base-chinese(已有)
任务模型:需要从 DeepKE 下载预训练的 RE 模型
位置:relation_extraction/checkpoints/
AE(属性抽取)- 选项3:
基础模型:bert-base-chinese(已有)
任务模型:需要从 DeepKE 下载预训练的 AE 模型(lm_epoch1.pth)
位置:attributation_extraction/checkpoints/
5.我们先下载本地模型,我直接在本地下载模型
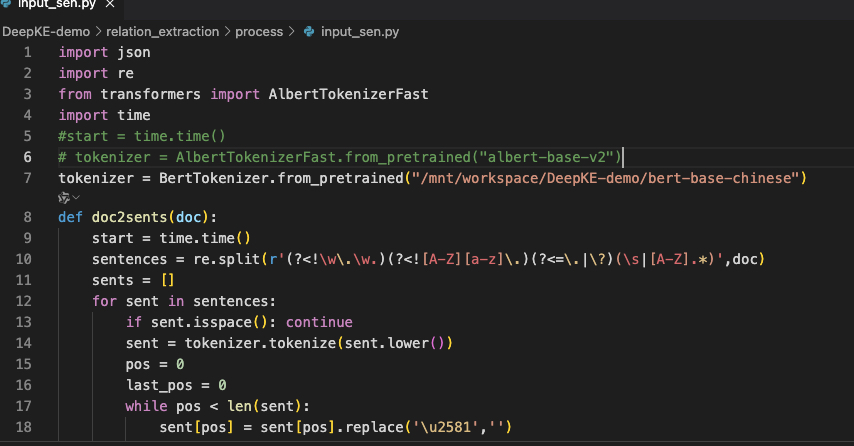
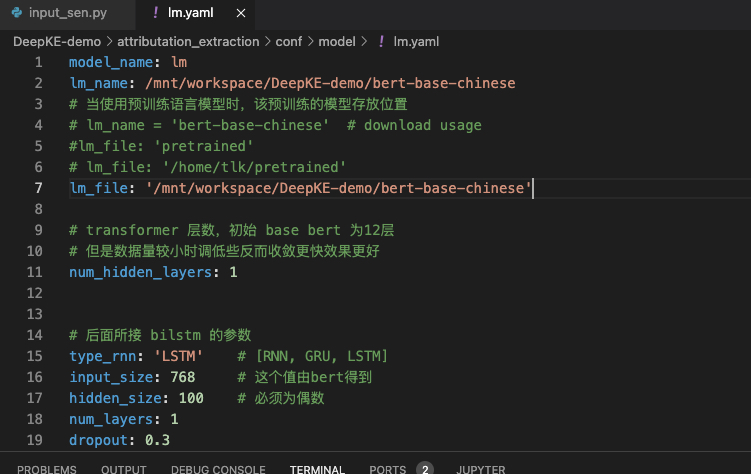
git clone https://www.modelscope.cn/tiansz/bert-base-chinese.git修改选项2和选项3中对应的模型的路径为本地路径
关系抽取的
属性抽取的
6.然后去官网下载预训练模型
我发现属性抽取没有提供预训练模型
但是其余两个有,下载地址如下https://drive.google.com/drive/folders/1wb_QIZduKDwrHeri0s5byibsSQrrJTEv
(https://github.com/zjunlp/DeepKE/blob/main/README_CNSCHEMA_CN.md)
7.将下载好的re和ner对应的文件放到对应的位置
1)re

修改relation_extraction中的demo.py的路径和tokenizer,完整代码如下
import os
import numpy as np
import torch
import random
import pickle
from tqdm import tqdm
import ujson as json
from torch.utils.data import DataLoader
from transformers import AutoConfig, AutoModel, AutoTokenizer
import time
from .process import *def to_official(preds, features):rel2id = json.load(open(f'relation_extraction/data/rel2id.json', 'r'))rel2info = json.load(open(f'relation_extraction/data/rel_info.json', 'r'))entity = json.load(open(f'relation_extraction/data/output.json', 'r'))id2rel = {value: key for key, value in rel2id.items()}h_idx, t_idx, title = [], [], []for f in features:hts = f["hts"]h_idx += [ht[0] for ht in hts]t_idx += [ht[1] for ht in hts]title += [f["title"] for ht in hts]res = []for i in range(preds.shape[0]):pred = preds[i]pred = np.nonzero(pred)[0].tolist()for p in pred:if p != 0:h_entity, t_entity = '', ''for en in entity[0]['vertexSet'][h_idx[i]]:if len(en['name']) > len(h_entity):h_entity = en['name']for en in entity[0]['vertexSet'][t_idx[i]]:if len(en['name']) > len(t_entity):t_entity = en['name']res.append({'h': h_entity,'t': t_entity,'r': rel2info[id2rel[p]],})return resclass ReadDataset:def __init__(self, tokenizer, max_seq_Length: int = 1024,transformers: str = 'bert') -> None:self.transformers = transformersself.tokenizer = tokenizerself.max_seq_Length = max_seq_Lengthdef read(self, file_in: str):save_file = file_in.split('.json')[0] + '_' + self.transformers + '.pkl'return read_docred(self.transformers, file_in, save_file, self.tokenizer, self.max_seq_Length)def read_docred(transfermers, file_in, save_file, tokenizer, max_seq_length=1024):max_len = 0up512_num = 0i_line = 0pos_samples = 0neg_samples = 0features = []docred_rel2id = json.load(open(f'relation_extraction/data/rel2id.json', 'r'))if file_in == "":return Nonewith open(file_in, "r") as fh:data = json.load(fh)if transfermers == 'albert':entity_type = ["-", "ORG", "-", "LOC", "-", "TIME", "-", "PER", "-", "MISC", "-", "NUM"]for sample in data:sents = []sent_map = []entities = sample['vertexSet']entity_start, entity_end = [], []mention_types = []for entity in entities:for mention in entity:sent_id = mention["sent_id"]pos = mention["pos"]entity_start.append((sent_id, pos[0]))entity_end.append((sent_id, pos[1] - 1))mention_types.append(mention['type'])for i_s, sent in enumerate(sample['sents']):new_map = {}for i_t, token in enumerate(sent):tokens_wordpiece = tokenizer.tokenize(token)if (i_s, i_t) in entity_start:t = entity_start.index((i_s, i_t))if transfermers == 'albert':mention_type = mention_types[t]special_token_i = entity_type.index(mention_type)special_token = ['[unused' + str(special_token_i) + ']']else:special_token = ['*']tokens_wordpiece = special_token + tokens_wordpieceif (i_s, i_t) in entity_end:t = entity_end.index((i_s, i_t))if transfermers == 'albert':mention_type = mention_types[t]special_token_i = entity_type.index(mention_type) + 50special_token = ['[unused' + str(special_token_i) + ']']else:special_token = ['*']tokens_wordpiece = tokens_wordpiece + special_tokennew_map[i_t] = len(sents)sents.extend(tokens_wordpiece)new_map[i_t + 1] = len(sents)sent_map.append(new_map)if len(sents)>max_len:max_len=len(sents)if len(sents)>512:up512_num += 1train_triple = {}if "labels" in sample:for label in sample['labels']:evidence = label['evidence']r = int(docred_rel2id[label['r']])if (label['h'], label['t']) not in train_triple:train_triple[(label['h'], label['t'])] = [{'relation': r, 'evidence': evidence}]else:train_triple[(label['h'], label['t'])].append({'relation': r, 'evidence': evidence})entity_pos = []for e in entities:entity_pos.append([])mention_num = len(e)for m in e:start = sent_map[m["sent_id"]][m["pos"][0]]end = sent_map[m["sent_id"]][m["pos"][1]]entity_pos[-1].append((start, end,))relations, hts = [], []# Get positive samples from datasetfor h, t in train_triple.keys():relation = [0] * len(docred_rel2id)for mention in train_triple[h, t]:relation[mention["relation"]] = 1evidence = mention["evidence"]relations.append(relation)hts.append([h, t])pos_samples += 1# Get negative samples from datasetfor h in range(len(entities)):for t in range(len(entities)):if h != t and [h, t] not in hts:relation = [1] + [0] * (len(docred_rel2id) - 1)relations.append(relation)hts.append([h, t])neg_samples += 1assert len(relations) == len(entities) * (len(entities) - 1)if len(hts)==0:print(len(sent))sents = sents[:max_seq_length - 2]input_ids = tokenizer.convert_tokens_to_ids(sents)input_ids = tokenizer.build_inputs_with_special_tokens(input_ids)i_line += 1feature = {'input_ids': input_ids,'entity_pos': entity_pos,'labels': relations,'hts': hts,'title': sample['title'],}features.append(feature)with open(file=save_file, mode='wb') as fw:pickle.dump(features, fw)return featuresdef collate_fn(batch):max_len = max([len(f["input_ids"]) for f in batch])input_ids = [f["input_ids"] + [0] * (max_len - len(f["input_ids"])) for f in batch]input_mask = [[1.0] * len(f["input_ids"]) + [0.0] * (max_len - len(f["input_ids"])) for f in batch]input_ids = torch.tensor(input_ids, dtype=torch.long)input_mask = torch.tensor(input_mask, dtype=torch.float)entity_pos = [f["entity_pos"] for f in batch]labels = [f["labels"] for f in batch]hts = [f["hts"] for f in batch]output = (input_ids, input_mask, labels, entity_pos, hts )return outputdef report(args, model, features):device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")dataloader = DataLoader(features, batch_size=args.test_batch_size, shuffle=False, collate_fn=collate_fn, drop_last=False)preds = []for batch in dataloader:model.eval()inputs = {'input_ids': batch[0].to(device),'attention_mask': batch[1].to(device),'entity_pos': batch[3],'hts': batch[4],}with torch.no_grad():pred = model(**inputs)pred = pred.cpu().numpy()pred[np.isnan(pred)] = 0preds.append(pred)preds = np.concatenate(preds, axis=0).astype(np.float32)preds = to_official(preds, features)return predsclass Config(object):unet_in_dim=3unet_out_dim=256max_height=42down_dim=256channel_type='context-based'unet_out_dim=256test_batch_size=2cfg = Config()def color(text, color="\033[1;34m"): return color+text+"\033[0m"def doc_re():sentence = input(f"Enter the {color('sentence')}: ")input_file = 'relation_extraction/input.txt'with open(input_file , 'w') as f:f.write(sentence)txt2json(input_file, 'relation_extraction/data/output.json')device = torch.device("cpu")bert_path = '/mnt/workspace/DeepKE-demo/bert-base-chinese'config = AutoConfig.from_pretrained(bert_path, num_labels=97)tokenizer = AutoTokenizer.from_pretrained(bert_path)Dataset = ReadDataset(tokenizer, 1024, transformers='bert')test_file = 'relation_extraction/data/output.json'test_features = Dataset.read(test_file)model = AutoModel.from_pretrained(bert_path, from_tf=False, config=config)config.cls_token_id = tokenizer.cls_token_idconfig.sep_token_id = tokenizer.sep_token_idconfig.transformer_type = 'bert'seed = 111random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)model = DocREModel(config, cfg, model, num_labels=4)checkpoint_path = 'relation_extraction/checkpoints/re_bert.pth'if not os.path.exists(checkpoint_path):raise FileNotFoundError(f"预训练模型文件不存在:{checkpoint_path},请确保已下载模型文件并放置在正确位置。")# 加载预训练权重# model.load_state_dict(torch.load(checkpoint_path, map_location='cpu'))# 加载预训练权重并处理键名不匹配state_dict = torch.load(checkpoint_path, map_location='cpu')new_state_dict = {}for k, v in state_dict.items():if k.startswith('bert.'):new_k = 'bert_model.' + k[5:] # 将 'bert.' 替换为 'bert_model.'new_state_dict[new_k] = velse:new_state_dict[k] = v# 加载可以加载的权重model_dict = model.state_dict()pretrained_dict = {k: v for k, v in new_state_dict.items() if k in model_dict}model_dict.update(pretrained_dict)model.load_state_dict(model_dict, strict=False)model.to(device)pred = report(cfg, model, test_features)with open(input_file.split('.txt')[0]+'.json', "w") as fh:json.dump(pred, fh)print()print(f"The {color('triplets')} are as follow:")print()for i in pred:print(i)print()if __name__ == "__main__":doc_re()同时修改/mnt/workspace/DeepKE-demo/relation_extraction/process/model.py
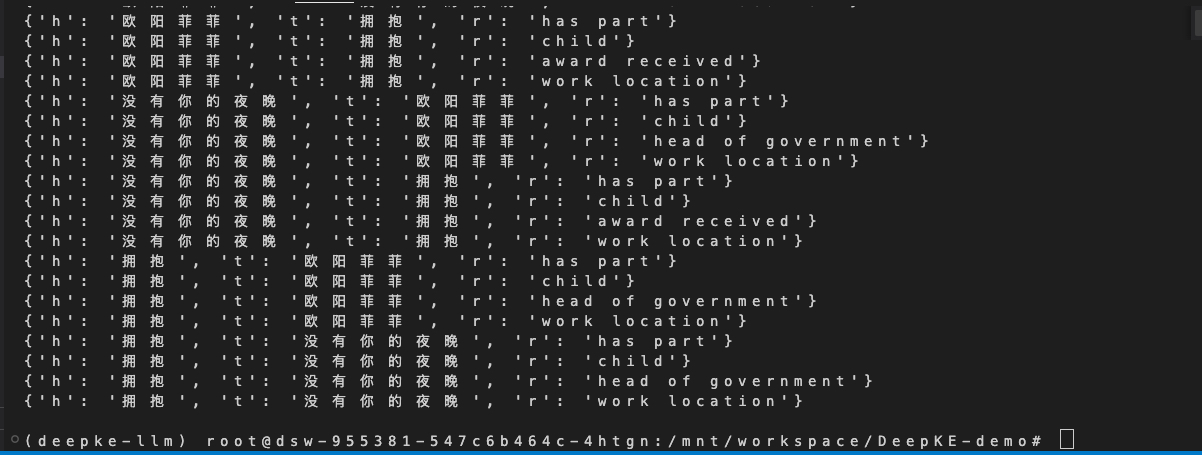
def encode(self, input_ids, attention_mask,entity_pos):config = self.configif config.transformer_type == "albert":start_tokens = [config.cls_token_id]end_tokens = [config.sep_token_id]elif config.transformer_type == "bert":start_tokens = [config.cls_token_id]end_tokens = [config.sep_token_id]elif config.transformer_type == "roberta":start_tokens = [config.cls_token_id]end_tokens = [config.sep_token_id, config.sep_token_id]sequence_output, attention = process_long_input(self.bert_model, input_ids, attention_mask, start_tokens, end_tokens)return sequence_output, attention测试句子有格式要求:{[0][PER]欧阳菲菲}演唱的{[1][SONG]没有你的夜晚},出自专辑{[2][ALBUM]拥抱}
最后结果
2)ner
将下载好的checkpoint_bert.zip移动到ner文件夹下并解压缩,然后运行,记得重命名为checkpointints
运行报错,标签老是对不上,重新训练
/mnt/workspace/DeepKE/example/ner/standard路径下
下载数据集
wget 120.27.214.45/Data/ner/standard/data.tar.gztar -xzvf data.tar.gz然后修改配置,改为自己的路径名
/mnt/workspace/DeepKE/example/ner/standard/conf/hydra/model/bert.yaml

安装环境依赖(重新建一个conda环境吧,训练不等同于推理)conda create -n deepke python=3.8conda activate deepkepip install pip==24.0
在DeepKE源码根目录下(git clone https://github.com/zjunlp/DeepKE.git)
pip install --use-pep517 seqeval
pip install -r requirements.txtpython setup.py installpython setup.py develop
pip install safetensors
/mnt/workspace/DeepKE/example/ner/standard路径下
运行python run_bert.py
如果用gpu训练的话,需要
pip uninstall torch torchvision torchaudio -ypip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
24g显存,使用率是70%,训练了两个小时左右
but,效果并不好
