漯河做网站zrgu郑州seo排名优化
一、引言
随着无人机技术的不断发展,其在城市环境中的应用越来越广泛,如物流配送、航拍测绘、交通监控等。然而,城市场景具有复杂的建筑布局、密集的障碍物以及多变的飞行环境,给无人机的路径规划带来了巨大的挑战。传统的路径规划算法在三维复杂空间中往往难以满足实时性和最优性的要求。因此,研究一种有效的无人机三维路径规划算法具有重要的现实意义。Q-learning 算法作为一种强化学习方法,能够通过与环境的交互学习最优策略,为解决城市场景下无人机路径规划问题提供了新的思路。
二、相关理论基础
(一)无人机三维路径规划问题描述
在城市场景中,无人机的飞行空间可以表示为一个三维坐标系。其路径规划的目标是从起始点 [S] 到目标点 [T],在满足飞行安全约束的条件下,寻找一条最优路径,使无人机能够避开建筑物、信号塔等障碍物,同时尽可能地减少飞行距离、时间或能量消耗等成本。
(二)Q-learning 算法原理
Q-learning 算法是一种基于价值的强化学习算法。其核心是学习一个 Q 表,该表表示在给定状态下采取某个动作所能获得的预期累积奖励。通过不断地与环境进行交互,智能体(无人机)根据当前状态选择动作,观察环境反馈的奖励以及下一个状态,然后更新 Q 表中的值。具体来说,Q-learning 的更新公式为:
Q(s,a) = Q(s,a) + α [r + γ max Q(s’,a’) - Q(s,a)]
其中,Q(s,a) 表示在状态 s 下采取动作 a 的 Q 值;α 是学习率,控制新旧信息的融合程度;r 是当前动作获得的即时奖励;γ 是折扣因子,用于衡量未来奖励的权重;max Q(s’,a’) 是下一个状态 s’ 下所有可能动作 a’ 中的最大 Q 值。
三、基于 Q-learning 的无人机三维路径规划算法设计
(一)状态空间定义
在城市场景下,无人机的状态可以由其在三维空间中的位置坐标(x,y,z)以及周围的环境信息(如附近障碍物的距离、方向等)来综合表示。为了简化问题,可以将飞行空间划分为网格,每个网格点对应一个状态。同时,结合无人机的传感器数据,提取障碍物相关信息作为状态的一部分,以增强无人机对周围环境的感知能力。
(二)动作空间确定
无人机的动作主要包括沿不同方向的飞行,如向上、向下、向前、向后、向左、向右以及对角线方向的移动等。在三维空间中,这些动作可以表示为从当前位置到相邻网格点的位移向量。为了保证飞行的连续性和稳定性,需要对动作的幅度进行限制,并且确保每次移动后的位置仍在安全的飞行区域内。
(三)奖励函数设计
奖励函数是引导无人机学习最优路径的关键。在设计奖励函数时,需要综合考虑以下几个方面:
- 目标奖励 :当无人机成功到达目标点时,给予较大的正奖励,以鼓励其尽快完成任务。
- 碰撞惩罚 :如果无人机与障碍物发生碰撞,则给予较大的负奖励,强制其避免危险动作。
- 距离奖励 :根据无人机当前位置与目标点的距离变化给予奖励或惩罚。当距离减小时,给予一定的正奖励;反之,给予负奖励,促使无人机朝着目标方向移动。
- 飞行成本奖励 :考虑到无人机的飞行成本(如能量消耗等),对于较长的飞行距离或复杂的飞行动作,给予适当的负奖励,使其在规划路径时尽量选择成本较低的路线。
(四)算法实现步骤
-
初始化 Q 表,将所有 Q 值设为 0。
-
确定无人机的初始状态 [S]。
-
重复以下步骤直到满足终止条件(如达到最大迭代次数或成功到达目标点多次):
- 根据当前状态,选择一个动作。可以选择贪婪策略(ε-greedy),即以概率 ε 随机选择动作,以概率 1 - ε 选择 Q 值最大的动作,以平衡探索与利用的关系。
- 执行所选动作,观察环境反馈的奖励 r 以及下一个状态 s’。
- 根据 Q-learning 更新公式,更新当前状态和动作对应的 Q 值。
- 将状态更新为下一个状态 s’。
-
输出学习到的 Q 表,根据 Q 表确定最优路径。
四、实验与结果分析
(一)实验环境设置
为了验证基于 Q-learning 的无人机三维路径规划算法的有效性,构建了一个城市场景仿真模型。该模型包括不同高度、形状和分布密度的建筑物,模拟真实的飞行环境。无人机的起始点和目标点随机设置在场景中,并且在飞行过程中需要避开各种障碍物。
部分MATLAB代码如下:
% Q-learning算法主循环
% 这一部分设置集的数量,并将代理的状态初始化为1。
for episode = 1:num_episodes state = 1; % 初始状态done = false;while ~done % 在这里,智能体使用epsilon-greedy策略选择一个动作。% 对于exploration_rate,它选择随机行动;否则,选择当前状态下q值最高的动作。if rand() < exploration_rateaction = randi(num_actions); % 随机选择动作else[~, action] = max(Q(state, :)); % 选择最优动作end% 执行动作并观察反馈% 代理采取行动,转移到下一个状态(next_state),并根据环境接收奖励。next_state = takeAction(state, action, size(environment));reward = getReward(next_state, environment);% 更新Q值,使用Q-learning更新规则,更新当前状态-动作对的q值。Q(state, action) = Q(state, action) + learning_rate * (reward + discount_factor * max(Q(next_state, :)) - Q(state, action));% 更新状态 state = next_state;% 代理更新其当前状态并检查它是否已达到目标状态(num_states)if state == num_statesdone = true;endend
end(二)实验结果与分析
自定义不同大小的地图:
1010的地图:
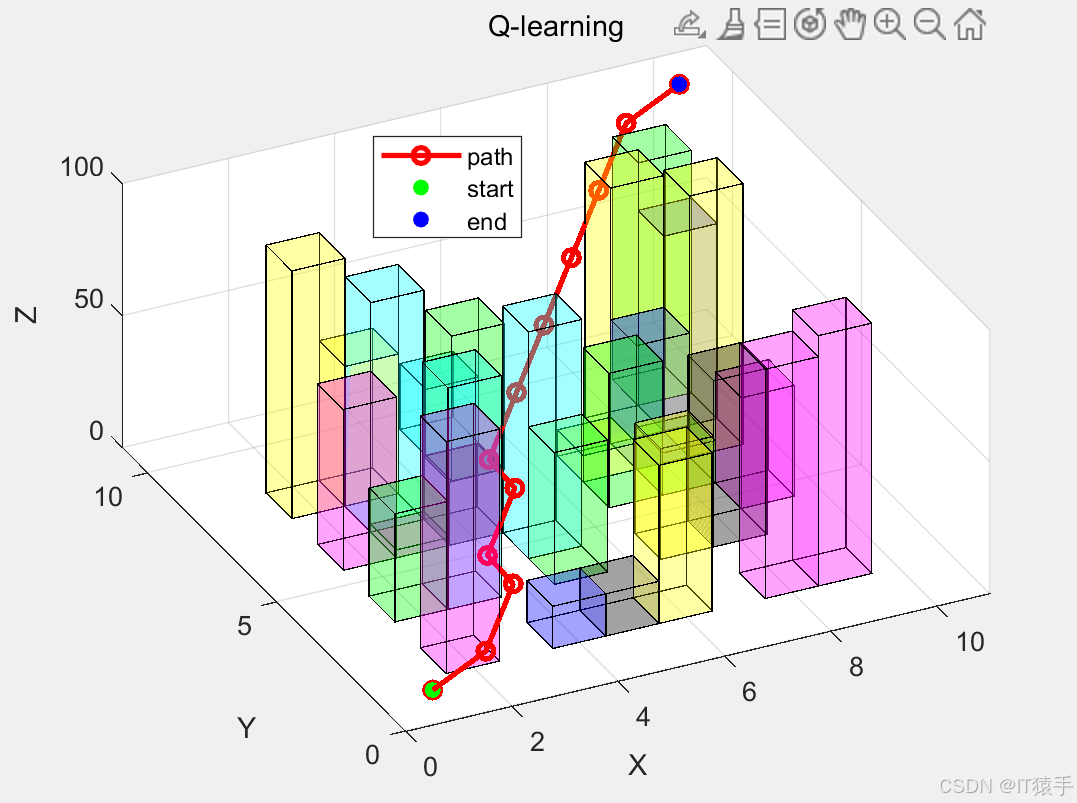
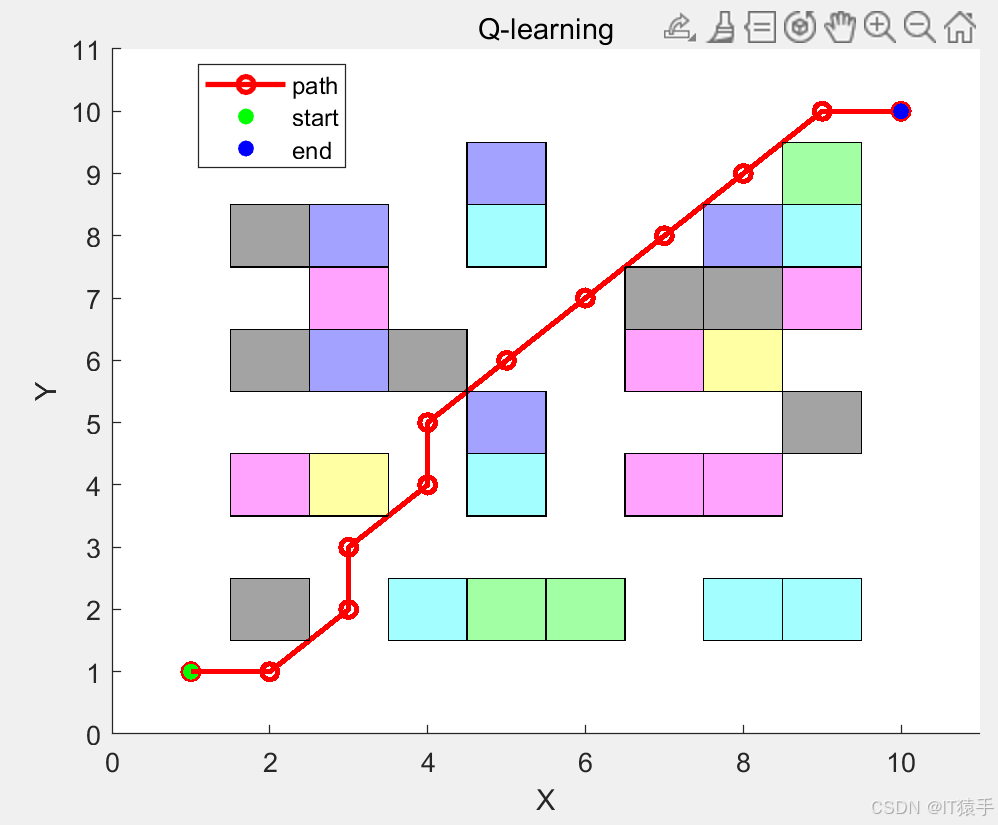
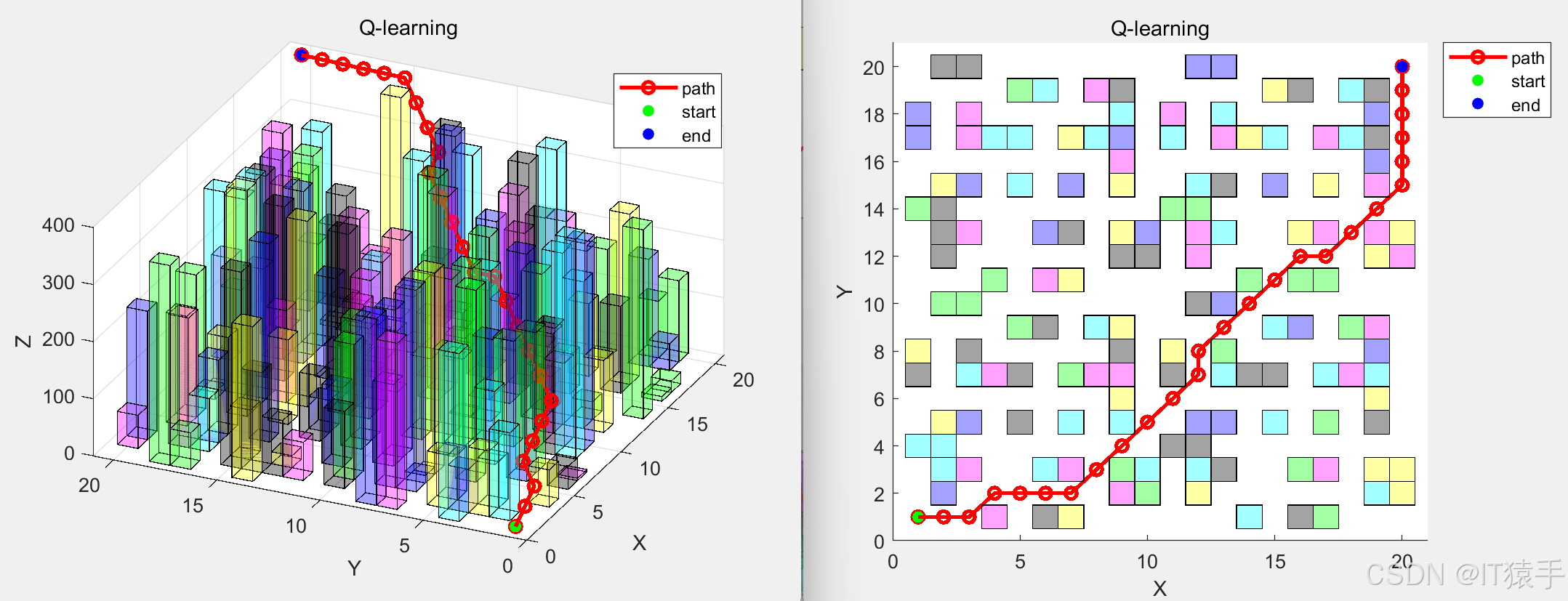
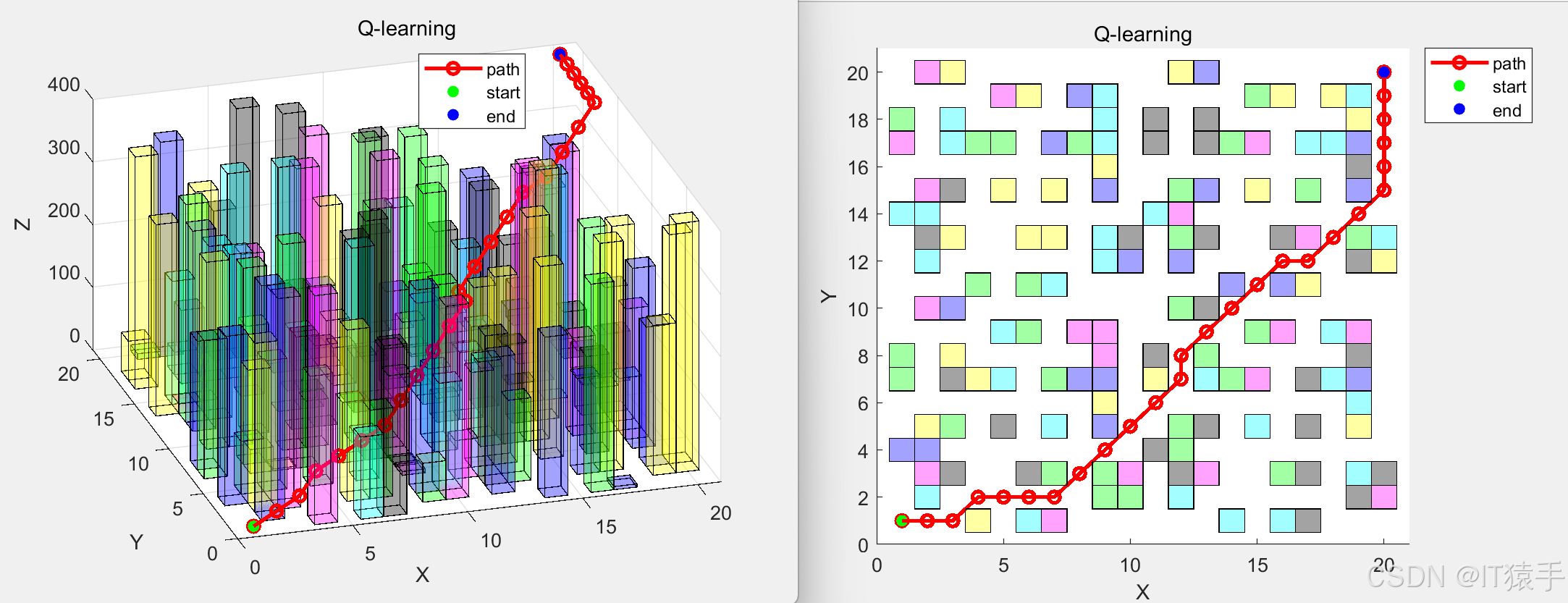
2020地图:
通过多次实验,记录无人机在不同场景下的飞行路径、到达目标点的成功率、飞行距离以及算法的收敛速度等指标。实验结果显示,基于 Q-learning 的算法能够有效地规划出从起始点到目标点的可行路径,并且随着训练的进行,路径的最优性逐渐提高,成功到达目标点的概率也显著增加。此外,与一些传统路径规划算法相比,该算法在面对复杂多变的城市场景时具有更好的适应性和灵活性。然而,该算法也存在一定的局限性,例如在大规模场景中,状态空间和动作空间的维度较高,导致 Q 表的存储和更新较为复杂,可能会影响算法的实时性。因此,在实际应用中,需要根据具体情况进行优化和改进,如对状态空间进行降维处理或采用函数近似的方法来替代 Q 表。