怎样做网站标题的图标高平网站优化公司
🌟引言:
上一篇:Python星球日记 - 第15天:综合复习(回顾前14天所学知识)
名人说:不要人夸颜色好,只留清气满乾坤(王冕《墨梅》)
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、爬虫的概念与原理
- 1. 什么是网络爬虫
- 2. 爬虫的工作原理
- 3. 爬虫的法律和道德考量⚠️
- 二、使用 requests 库获取网页数据
- 1. `requests`库介绍
- 2. 发送GET请求
- 3. 处理响应内容
- 4. 设置请求头和参数
- 三、使用 BeautifulSoup 解析HTML
- 1. BeautifulSoup简介
- 2. 安装和导入
- 3. 解析HTML文档
- 4. 选择和提取元素
- 四、实战练习:爬取网站标题列表
- 1. 目标分析
- 2. 编写爬虫代码
- 3. 运行和结果分析
- 4. 优化和扩展
- 五、练习(仅学习用途)
- 六、总结
- 参考资源
专栏介绍: Python星球日记专栏介绍(持续更新ing)
更多Python知识,请关注我、订阅专栏《 Python星球日记》,内容持续更新中…
欢迎来到Python星球🪐的第16天!
在学习完Python基础知识并进行了复习后,我们今天将探索一个非常实用的Python应用领域:网络爬虫。通过今天的学习,你将了解如何使用Python抓取互联网上的数据,这是数据分析、人工智能和自动化任务的重要基础。
一、爬虫的概念与原理
1. 什么是网络爬虫
网络爬虫(Web Crawler)是一种自动获取网页内容的程序。它可以访问互联网上的网页,获取其中的数据,并根据需要进行分析和存储。爬虫就像是我们派出去的"数字蜘蛛",它们在互联网的"网络"上爬行,收集我们需要的信息。
2. 爬虫的工作原理
爬虫的基本工作原理可以概括为以下几个步骤:
- 发送请求:爬虫向目标网站发送HTTP请求,就像我们在浏览器中输入网址一样。
- 获取响应:服务器返回响应,通常包含HTML、JSON或其他格式的数据。
- 解析数据:爬虫解析获取到的数据,提取出需要的信息。
- 数据处理:对提取的数据进行清洗、转换和存储。
- 应用数据:将处理后的数据用于分析、展示或其他用途。

3. 爬虫的法律和道德考量⚠️
在进行网络爬虫活动时,我们需要注意以下几点🌟:
- 尊重robots.txt:许多网站都有一个名为
robots.txt的文件,用于告诉爬虫哪些页面可以访问,哪些不能。 - 控制请求频率:过于频繁的请求可能会给服务器带来负担,甚至被误认为是DoS攻击(拒绝服务攻击)。
- 遵守法律法规:不要爬取受版权保护的内容或个人隐私数据。
- 注意使用条款:某些网站在使用条款中明确禁止爬虫活动。
二、使用 requests 库获取网页数据
1. requests库介绍
requests是Python中最受欢迎的 HTTP客户端库 ,它使得发送HTTP请求变得简单而直观。该库的设计理念是"为人类准备的HTTP库",因此使用起来非常友好。
首先,我们需要安装requests库:
pip install requests
2. 发送GET请求
使用requests库发送GET请求非常简单:
import requests# 发送GET请求
response = requests.get('https://www.example.com')# 检查请求是否成功
if response.status_code == 200:print('请求成功!')
else:print(f'请求失败,状态码: {response.status_code}')
例如,访问 www.baidu.com,向百度搜索主页发送GET请求
import requests# 发送GET请求
response = requests.get('https://www.baidu.com')# 检查请求是否成功
if response.status_code == 200:print('请求成功!')
else:print(f'请求失败,状态码: {response.status_code}')
可以看到,“请求成功!”,说明我们向百度搜索主页发送成功了请求。

3. 处理响应内容
成功发送请求后,我们可以通过多种方式访问响应内容:
import requestsresponse = requests.get('https://www.example.com')# 获取响应文本
html_content = response.text# 获取二进制内容(如图片)
binary_content = response.content# 如果响应是JSON格式,可以直接获取JSON数据
if 'application/json' in response.headers.get('Content-Type', ''):json_data = response.json()print(json_data)
例如,访问 www.baidu.com,向百度获取响应文本
import requestsresponse = requests.get('https://www.baidu.com')# 检查请求是否成功
if response.status_code == 200:print('请求成功!')
else:print(f'请求失败,状态码: {response.status_code}')# 获取响应文本
html_content = response.text# 获取二进制内容(如图片)
binary_content = response.content# 如果响应是JSON格式,可以直接获取JSON数据
if 'application/json' in response.headers.get('Content-Type', ''):json_data = response.json()print(json_data)
可以看到,“请求成功!”,说明我们向百度搜索主页发送成功了请求,但没有显示JSON数据,这说明中间存在某种机制在阻挡着。

这种机制是 反爬虫措施,会拒绝不像普通浏览器的请求。
那为什么会出现这个问题? 可能是因为:
- 缺少浏览器标识:网站可以检测到您的请求不是来自常规浏览器
- 反爬虫机制:大型网站如百度有复杂的反爬虫系统
- 重定向处理:网站可能将您重定向到其他页面而不直接返回内容
该怎么解决呢?我们可以设置一下请求头事实。
4. 设置请求头和参数
有时我们需要自定义请求头或传递参数:
import requests# 设置请求头,模拟真实浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Connection': 'keep-alive'
}try:# 发送带有浏览器标识的请求response = requests.get('https://www.baidu.com', headers=headers, timeout=10)# 检查请求是否成功print(f'状态码: {response.status_code}')# 查看请求是否被重定向if response.history:print(f'请求被重定向了 {len(response.history)} 次')print(f'最终URL: {response.url}')# 获取部分响应头信息print(f'内容类型: {response.headers.get("Content-Type", "未知")}')print(f'内容长度: {response.headers.get("Content-Length", "未知")}')# 检查内容if response.text:print(f'响应长度: {len(response.text)} 字符')print('前100个字符预览:')print(response.text[:100])else:print('没有获取到文本内容')# 检查是否有内容编码可能影响解析if response.encoding:print(f'内容编码: {response.encoding}')# 显示所有cookiesprint('Cookies:')for cookie in response.cookies:print(f' {cookie.name}: {cookie.value}')except requests.exceptions.RequestException as e:print(f'请求异常: {e}')
之后我们就能看到获取到的响应内容了。

三、使用 BeautifulSoup 解析HTML
1. BeautifulSoup简介
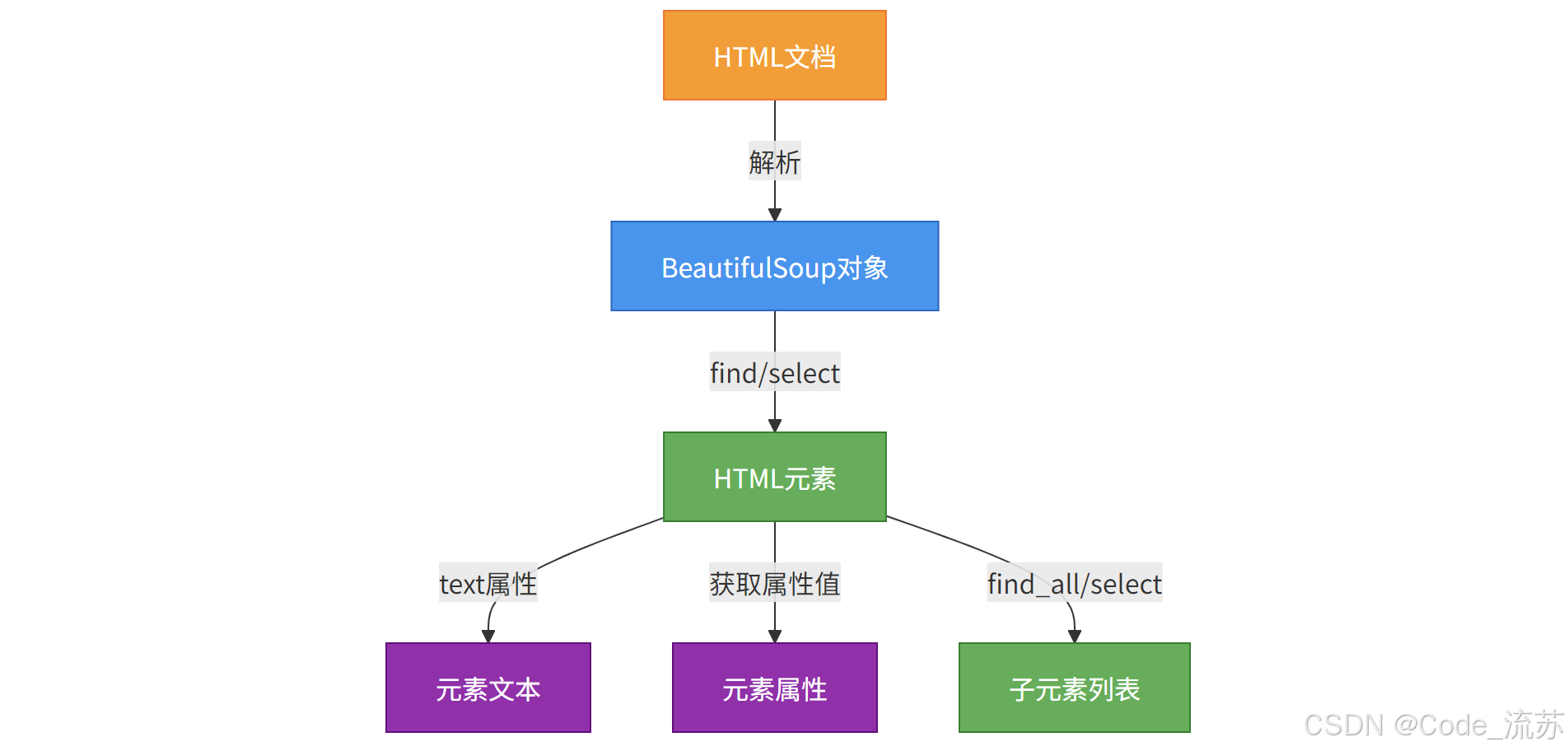
BeautifulSoup是一个强大的 HTML和XML解析库,它可以将HTML文档转换成树形结构,方便我们提取需要的信息。
2. 安装和导入
首先,我们需要安装 BeautifulSoup 库和一个解析器(这里使用lxml):
pip install beautifulsoup4 lxml
然后在代码中导入:
import requests
from bs4 import BeautifulSoup
3. 解析HTML文档
获取网页内容后,我们可以使用 BeautifulSoup 进行解析:
import requests
from bs4 import BeautifulSoup# 获取网页内容
response = requests.get('https://www.example.com')
html_content = response.text# 创建BeautifulSoup对象
soup = BeautifulSoup(html_content, 'html.parser')# 打印格式化后的HTML
print(soup.prettify())
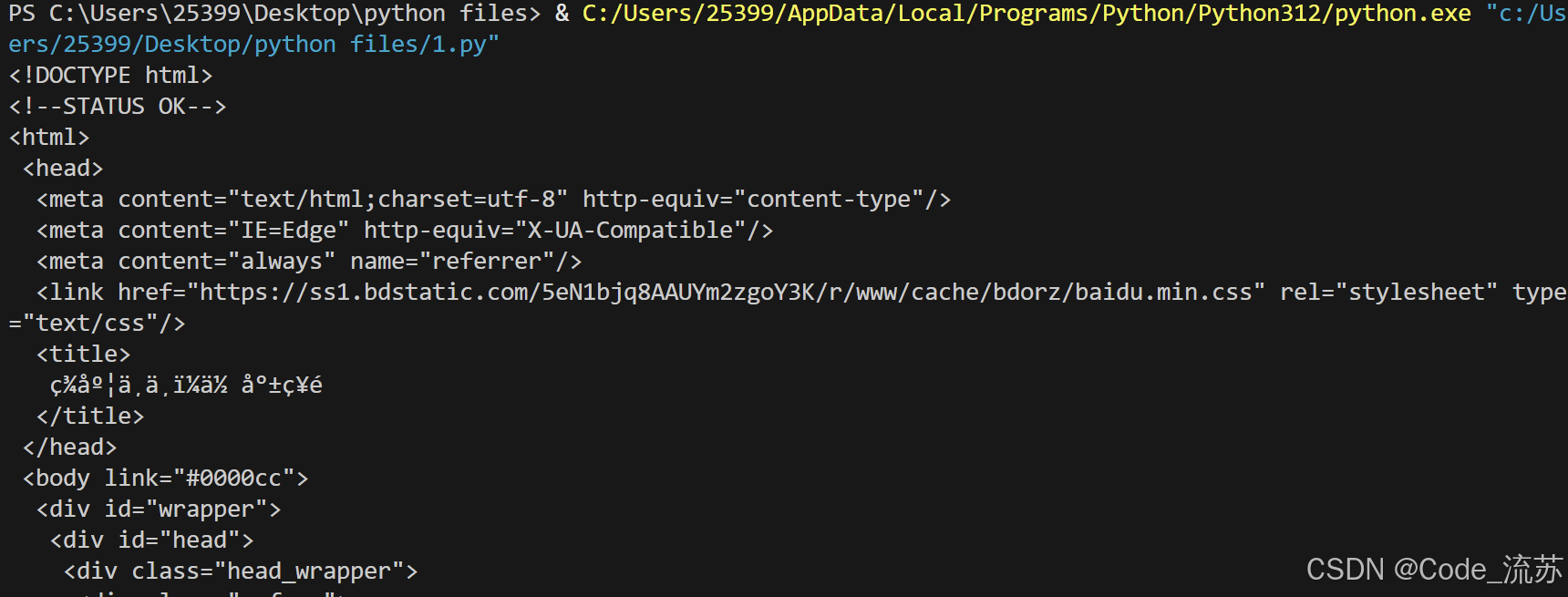
同样地,访问 www.baidu.com,我们借助 BeautifulSoup 来解析HTML文档
import requests
from bs4 import BeautifulSoup# 获取网页内容
response = requests.get('https://www.baidu.com')
html_content = response.text# 使用内置的 html.parser
soup = BeautifulSoup(html_content, 'html.parser')# 打印格式化后的HTML
print(soup.prettify())
可以看到,终端处已经出现了格式化后的HTML:
补充一点:解析器选择建议
对于网络爬虫和大多数 Web 开发工作:
- 如果性能和准确性是优先事项,安装并使用 lxml
- 如果只是简单脚本或不想有外部依赖,使用内置的 html.parser
- 如果需要处理非常复杂或格式不规范的 HTML,考虑安装 html5lib
4. 选择和提取元素
BeautifulSoup提供了多种方法来选择和提取HTML元素:
import requests
from bs4 import BeautifulSoup# 设置请求头,模拟浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
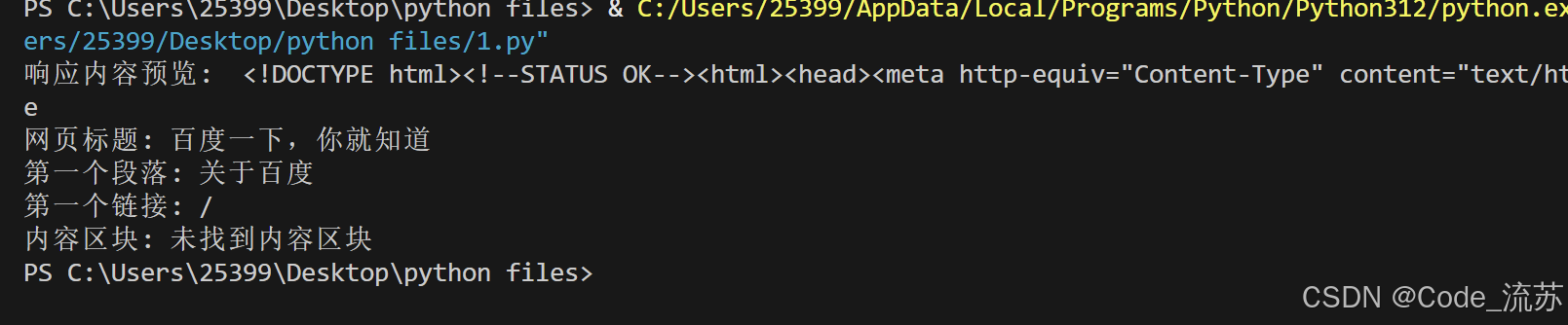
}try:# 发送请求获取网页内容response = requests.get('https://www.baidu.com', headers=headers)# 检查请求是否成功if response.status_code == 200:# 打印响应内容的前100个字符,帮助诊断print("响应内容预览: ", response.text[:100])# 解析HTMLsoup = BeautifulSoup(response.text, 'lxml')# 安全地获取元素 - 方法一:使用条件判断if soup.title:title_text = soup.title.textprint(f"网页标题: {title_text}")else:print("网页中没有找到<title>标签")# 安全地获取元素 - 方法二:使用.get()方法获取属性first_paragraph = soup.find('p')if first_paragraph:paragraph_text = first_paragraph.textprint(f"第一个段落: {paragraph_text}")else:print("网页中没有找到<p>标签")# 安全地获取元素 - 方法三:使用try-except捕获可能的错误try:first_link = soup.find('a')if first_link:link_href = first_link.get('href', '无链接') # 使用get方法提供默认值print(f"第一个链接: {link_href}")else:print("网页中没有找到<a>标签")except Exception as e:print(f"处理链接时出错: {e}")# 方法四:链式调用与默认值结合content_div_text = soup.select_one('div.content').text if soup.select_one('div.content') else "未找到内容区块"print(f"内容区块: {content_div_text}")else:print(f"请求失败,状态码: {response.status_code}")except Exception as e:print(f"程序执行出错: {e}")
访问 www.baidu.com,我们来选择和提取元素,可以看到,我们已经提取到了我们要找的元素。
四、实战练习:爬取网站标题列表
现在,让我们将学到的知识应用到实际案例中:爬取CSDN首页的文章标题列表。
1. 目标分析
我们的目标是爬取百度新闻首页(https://news.baidu.com/)的文章标题。在开始编写代码前,我们可以通过浏览器的开发者工具检查页面结构,找出包含标题的HTML元素。
2. 编写爬虫代码
import requests
from bs4 import BeautifulSoup
import time# 设置请求头,模拟浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}# 发送请求获取百度新闻页面的内容
url = 'https://news.baidu.com/'
response = requests.get(url, headers=headers)# 检查请求是否成功
if response.status_code == 200:# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(response.text, 'lxml')# 查找所有文章标题元素# 注意:以下选择器可能需要根据实际网页结构调整title_elements = soup.select('a.title')# 提取并打印标题print(f"共找到 {len(title_elements)} 篇文章")for i, title in enumerate(title_elements, 1):print(f"{i}. {title.text.strip()}")# 适当延时,避免请求过快if i % 5 == 0 and i < len(title_elements):time.sleep(0.5)
else:print(f"请求失败,状态码: {response.status_code}")
我们可以看到,并没有获取到百度新闻的文章列表,此时我们需要考虑其它方案来解决。

3. 运行和结果分析
运行上面的代码,你应该能看到百度新闻页面的文章标题列表。如果遇到问题,可能是因为网站结构发生了变化,需要调整选择器。
4. 优化和扩展
我们可以对代码进行一些优化和扩展:
import requests
from bs4 import BeautifulSoup
import csvdef crawl_with_requests():headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9'}try:# 尝试访问本地或国内网站,可能更容易成功url = 'https://news.baidu.com/' # 例如使用百度新闻response = requests.get(url, headers=headers, timeout=20)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')# 获取新闻标题articles = []news_links = soup.select('.hotnews a, .ulist a')for link in news_links:title = link.text.strip()href = link.get('href', '')if title and href and len(title) > 5:articles.append({'title': title,'link': href})# 保存结果with open('news_titles.csv', 'w', encoding='utf-8', newline='') as f:writer = csv.DictWriter(f, fieldnames=['title', 'link'])writer.writeheader()writer.writerows(articles)print(f"成功爬取 {len(articles)} 条新闻标题,已保存到 news_titles.csv")except Exception as e:print(f"发生错误: {e}")import tracebacktraceback.print_exc()if __name__ == "__main__":crawl_with_requests()

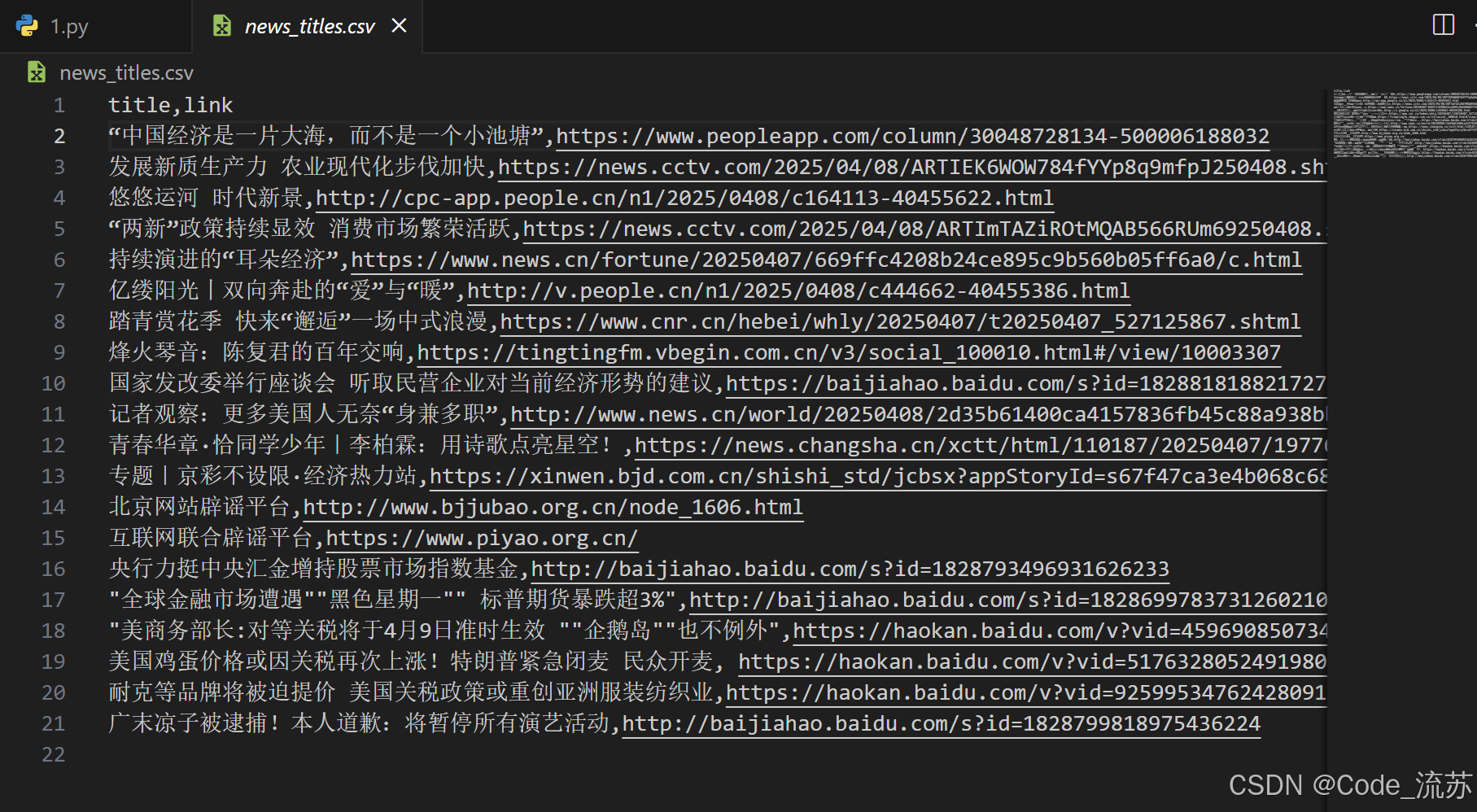
这个优化版本增加了:
- 异常处理:捕获各种可能的异常
- 超时设置:防止请求长时间等待
- 数据存储:将结果保存为CSV文件
- 功能封装:将爬虫代码封装为函数
五、练习(仅学习用途)
- 修改本文提供的代码,爬取你喜欢的技术博客网站的文章标题和发布日期。
- 尝试使用
requests和BeautifulSoup爬取一个简单的图片网站,并将图片保存到本地。 - 研究CSDN的
robots.txt文件,了解该网站对爬虫的规定。 - 思考:如何爬取需要登录才能访问的网页内容?
六、总结
今天,我们学习了网络爬虫的基本概念和原理,掌握了使用requests库获取网页数据和BeautifulSoup解析HTML的方法。通过实战练习,我们成功爬取了百度新闻的文章标题列表。
爬虫的知识还有很多,本篇仅入门了解,详细地大家可以查看官方文档使用,谢谢理解。
网络爬虫是一个强大的工具,它可以帮助我们自动化数据收集过程,为数据分析和机器学习提供原材料。然而,我们也要记住,务必注意!!!使用爬虫时需要遵守法律法规和网站的使用条款,尊重数据提供者的权益!
在接下来的学习中,我们将深入探索更多方向的基础知识,敬请期待《Python星球日记》的后续内容!
参考资源
- requests官方文档:https://requests.readthedocs.io/
- BeautifulSoup官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- 《Python网络数据采集》—— Ryan Mitchell 著
- 网络爬虫与信息提取:https://www.icourse163.org/course/BIT-1001870001
祝你在Python爬虫的旅程中收获满满!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!