无锡网络公司无锡网站设计aso优化贴吧
1 ShardingJDBC介绍
1.1 常见概念术语
① 数据节点Node:数据分片的最小单元,由数据源名称和数据表组成
如:ds0.product_order_0
② 真实表:再分片的数据库中真实存在的物理表
如:product_order_0
③ 逻辑表:相同逻辑和数据结构表的总称
如:product_order
④ 绑定规则:指分片规则一致的主表和子表
如:order表和order_item表,都是按照order_id分片
绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率提升
1.2 常见分片算法
分片键:用于分片的数据库字段,是将数据库(表)水平拆分的关键字段
ShardingJDBC既支持单分片键,也支持多个字段进行分片
分片策略
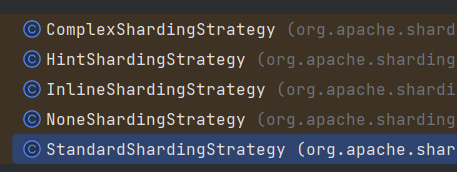
① 行表达式分片:InlineShardingStrategy
只支持单分片键
使用groovy表达式,提供对SQL语言的 = 和 IN 的分片操作支持
如:product_order_$->{user_id % 2} => product_order_0 和 product_order_1
② 标准分片:StandardShardingStrategy
只支持单分片键
PreciseShardingAlgorithm:精准分片,处理 = 和 IN 的分片操作
RangeShardingAlgorithm:范围分片,处理 BETWEEN AND 的分片操作
③ 复合分片:ComplexShardingStrategy
支持多分片键
提供 = 、 IN 和 BETWEEN AND 的分片操作
④ Hint分片:HintShardingStrategy
无需配置分片键,外部手动指定分片键
⑤ 不分片:NoneShardingStrategy
2 快速入门
SpringBoot整合ShardingJDBC
(1)导入依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.5.5</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>2.5.5</version></dependency> </dependencies>(2)编写启动类
@SpringBootApplication @EnableTransactionManagement @MapperScan("com.pandy.mapper") public class OrderApplication {public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);} }(3)创建数据库、表(2个库,4个表)
CREATE TABLE `product_order_0` (`id` bigint NOT NULL AUTO_INCREMENT,`out_trade_no` varchar(64) DEFAULT NULL COMMENT '订单唯一标识',`state` varchar(11) DEFAULT NULL COMMENT 'NEW 未支付订单,PAY已经支付订单,CANCEL超时取消订单',`create_time` datetime DEFAULT NULL COMMENT '订单生成时间',`pay_amount` decimal(16,2) DEFAULT NULL COMMENT '订单实际支付价格',`nickname` varchar(64) DEFAULT NULL COMMENT '昵称',`user_id` bigint DEFAULT NULL COMMENT '用户id',PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
(4)编写实体类
@Data @TableName("product_order") @EqualsAndHashCode(callSuper = false) public class ProductOrderDO {@TableId(value = "id",type = IdType.AUTO)private Long id;private String outTradeNo;private String state;private Date createTime;private Double payAmount;private String nickname;private Long userId; }(5)编写配置信息-分库分表(这里以分表为例,以user_id为分片键)
# 打印执行的数据库以及语句 spring.shardingsphere.props.sql.show=true# 数据源 db0 spring.shardingsphere.datasource.names=ds0,ds1# 第一个数据库 spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.5.135:3306/sharding_db_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true spring.shardingsphere.datasource.ds0.username=root spring.shardingsphere.datasource.ds0.password=root# 第二个数据库 spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.5.135:3306/sharding_db_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true spring.shardingsphere.datasource.ds1.username=root spring.shardingsphere.datasource.ds1.password=root# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...}, # 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...} spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】 spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=user_id spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{user_id % 2}(6)单元测试
@Test public void testInsertProductOrder() {for(int i=0; i<10; i++) {ProductOrderDO orderDO = new ProductOrderDO();orderDO.setOutTradeNo(UUID.randomUUID().toString().replaceAll("-",""));orderDO.setCreateTime(new Date());orderDO.setPayAmount(100d);orderDO.setState("NEW");orderDO.setNickname("pandy-" + i);orderDO.setUserId(Long.parseLong(i + ""));productOrderMapper.insert(orderDO);} }分库分表执行逻辑
(7)主键重复问题
使用自增主键,出现主键ID重复问题
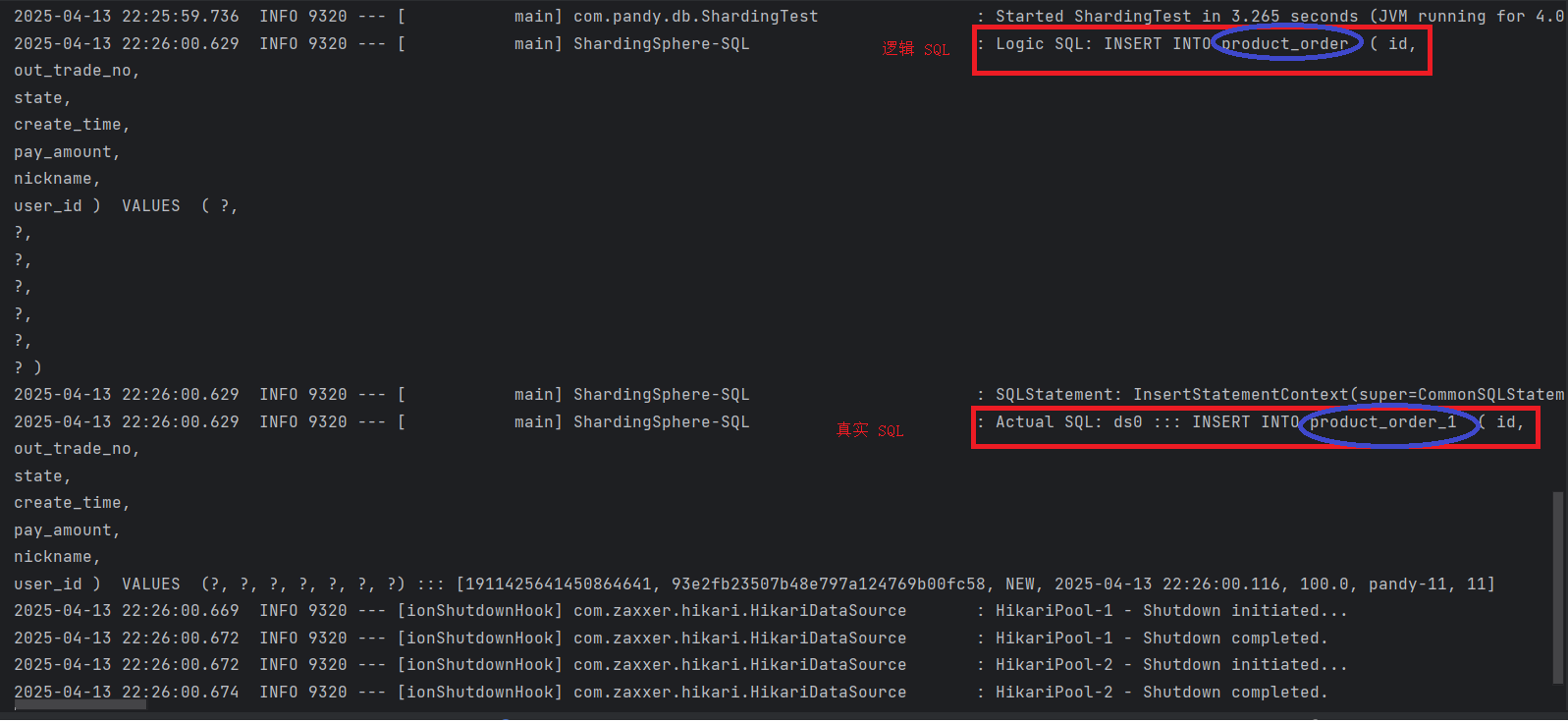
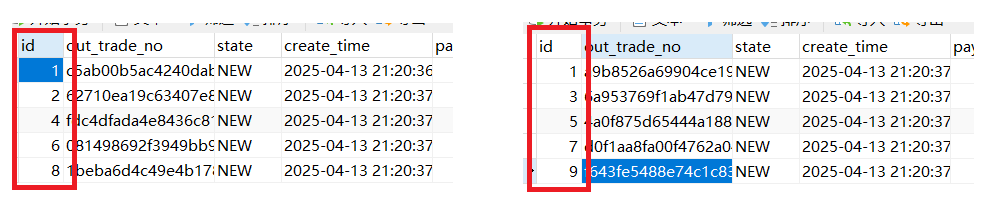
3 分库分表常见主键ID生成策略
需求:
① 性能强劲
② 全局唯一
③ 防止恶意用户根据ID规则来猜测和获取数据
3.1 业界常见解决方案
(1)自增ID,设置不同的自增步长
缺点:① 未来扩容比较麻烦
② 主从切换时不一致可能会导致重复ID
③ 性能瓶颈
(2)UUID
UUID.randomUUID().toString().replaceAll("-","");优点:性能非常高,没有网络消耗
缺点:① 无序的字符串,不具备趋势自增特性
② UUID太长,不易于存储,浪费存储空间
(3)Redis发号器
利用Redis的incr 或incrby 来实现,原子操作,线程安全
缺点:① 需要占用网络资源,增加系统复杂性
(4)snowflake雪花算法
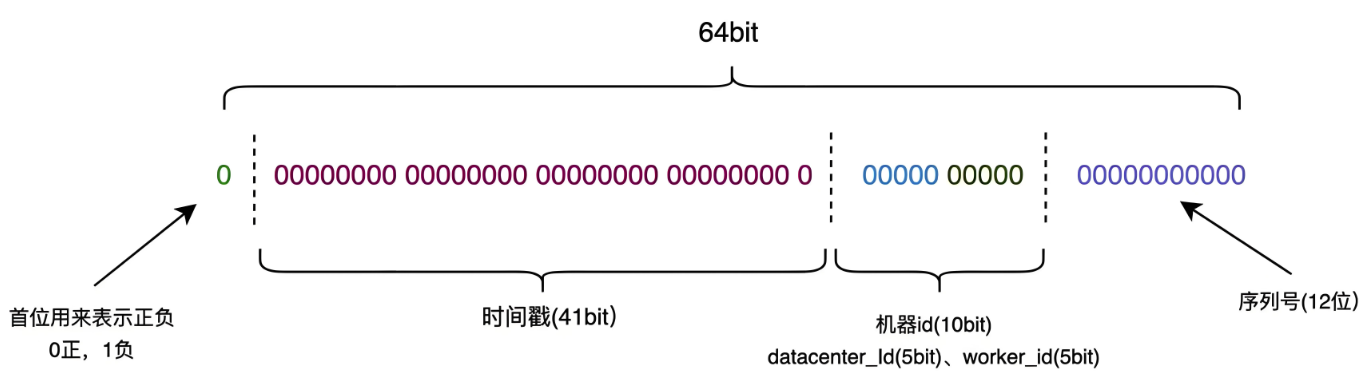
twitter开源的分布式ID生成算法
生成的ID中包含时间戳,所以生成的ID按照时间递增
部署多台服务器,需要保证系统时间一样,机器编号不一样
缺点:依赖系统时间(时钟回拨问题)
配置使用shardingjdbc的雪花算法
# 配置ID使用雪花算法
spring.shardingsphere.sharding.key-generator.column=id
spring.shardingsphere.sharding.key-generator.type=SNOWFLAKE看一下源码, shardingjdbc的雪花算法是怎么解决时钟回拨问题的?
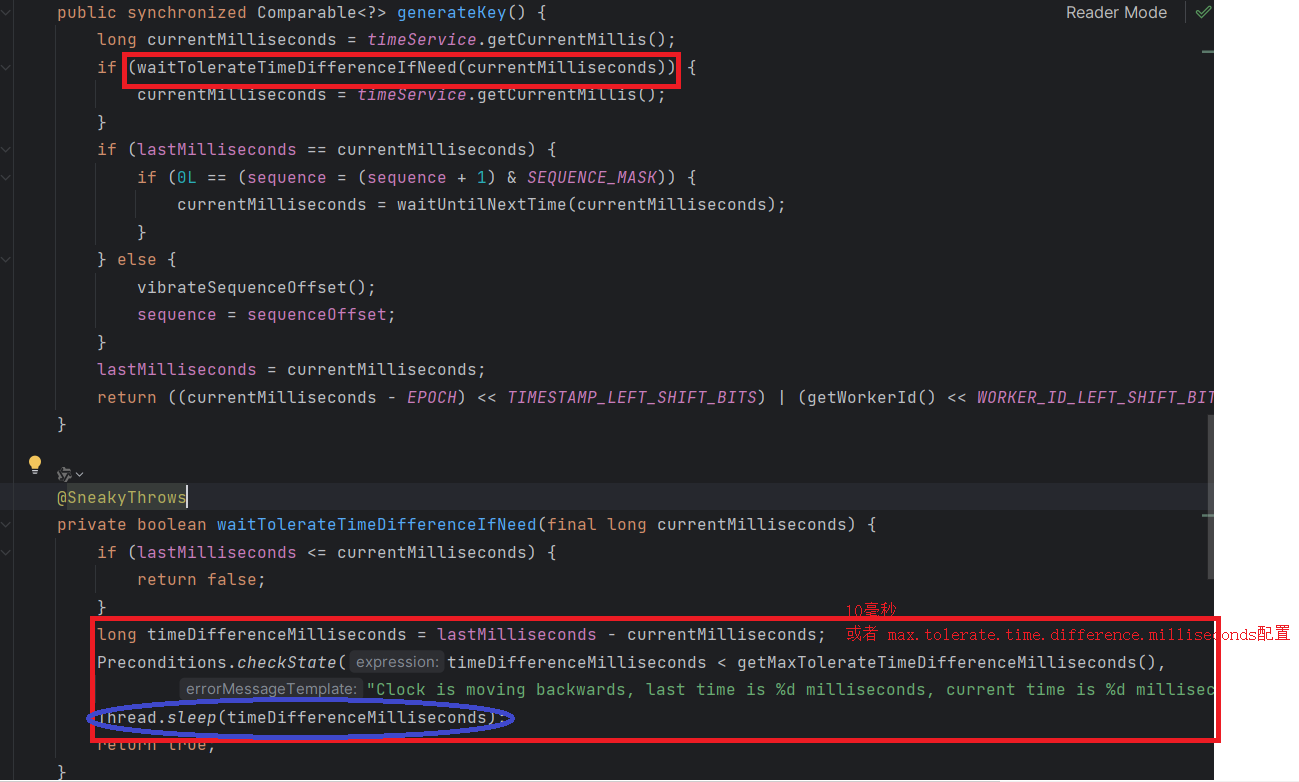
4 广播表和绑定表配置
广播表:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致
如:字典表,配置表等
(1)创建一个配置表
CREATE TABLE `config` (`id` bigint unsigned NOT NULL COMMENT '主键id',`config_key` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置key',`config_value` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置value',`type` varchar(128) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '类型',PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;(3)创建实体类
@Data @TableName("config") @EqualsAndHashCode(callSuper = false) public class ConfigDO {@TableId(value = "id")private Long id;private String configKey;private String configValue;private String type; }(3)添加广播表配置
#配置广播表 spring.shardingsphere.sharding.broadcast-tables=config(4)测试代码
@Test public void insertConfig() {ConfigDO configDO = new ConfigDO();configDO.setConfigKey("iphone");configDO.setConfigValue("iphone16秒杀广告");configDO.setType("AD");configMapper.insert(configDO); }

5 分库分表核心流程
解析 --> 路由 --> 改写 --> 执行 --> 结果归并
(1)解析
词法解析
语法解析
(2)路由
分片路由(带分片键):直接路由,标准路由,笛卡尔积路由
广播路由(不带分片键):全库表路由,全库路由,全实例路由
(3)改写
将逻辑SQL改写为可以正确执行的真实SQL
(4)执行
采用自动化的执行引擎
内存限制模式:适用于OLAP(连接数量不做限制,多线程并发执行)
连接限制模式:适用于OLAP(1库1线程,多库多线程,保证数据库资源足够多使用)
(5)结果归并
从各个数据节点获取多数据结果集,组合成为一个结果集
流式归并:每一次从结果集中获取到数据
内存归并:分片结果集的数据存储在内存中