网站建设合作协议模板微信软文范例大全100
| DeepSeek原创文章 | |
| 1 | DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 |
| 2 | Deepseek基座:DeepSeek LLM核心内容解析 |
| 3 | Deepseek基座:Deepseek MOE核心内容解析 |
| 4 | Deepseek基座:Deepseek-v2核心内容解析 |
| 5 | Deepseek基座:Deepseek-v3核心内容解析 |
| 6 | DeepSeek推理能力(Reasoning) |

DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek v2可以看作是上面那一篇paper的scale up,不过也有一些非常重要的技术。从论文名字可以看出来“A Strong, Economical, and Efficient”,他们提出了进一步降低成本的技术
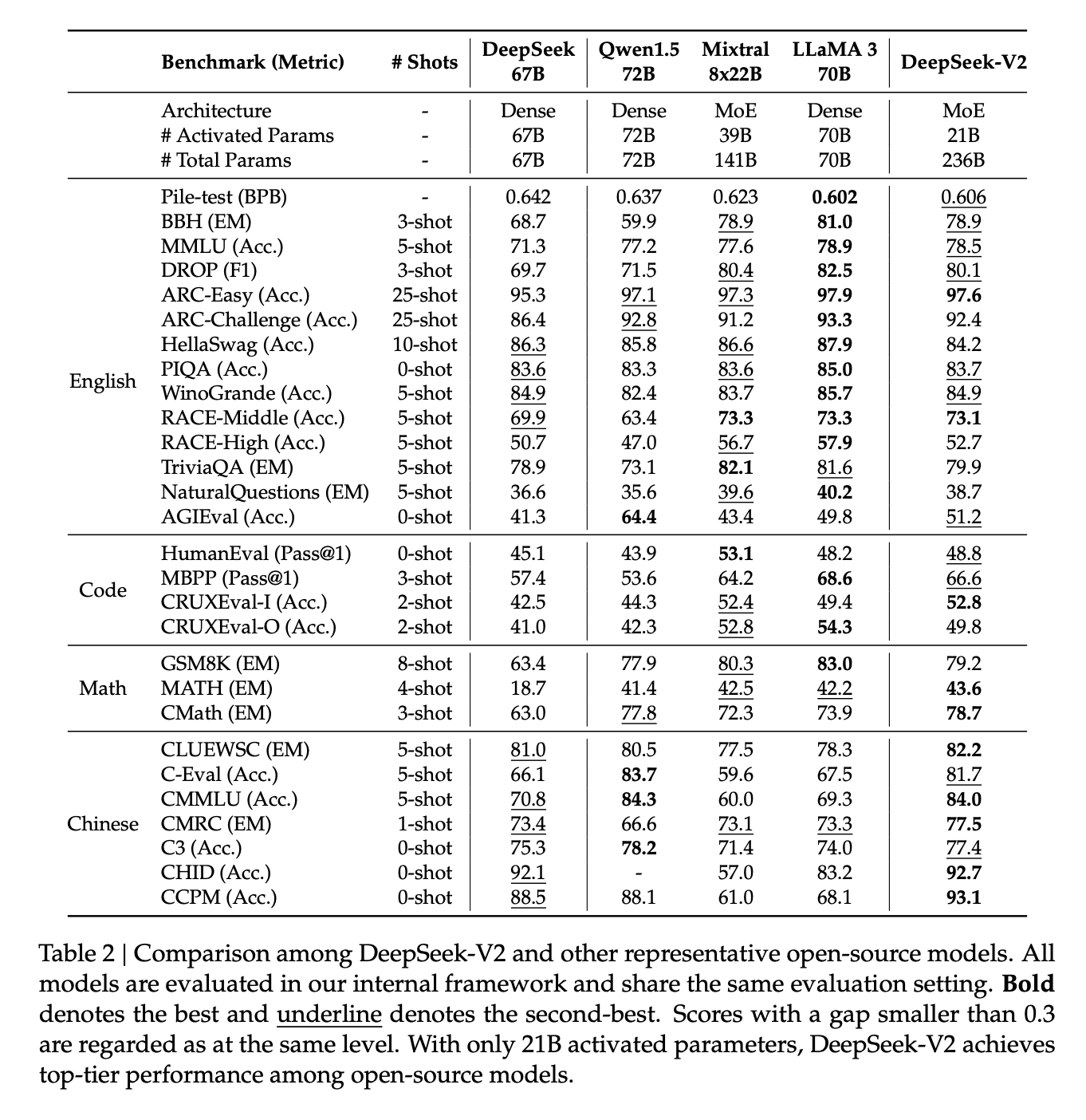
DeepSeek-V2 是236B的混合专家模型(MoE),每个 token 激活21B,极大降低了推理成本 。相比第一代的 DeepSeek 67B,虽然模型规模更大(接近其4倍),但激活参数更少,推理效率更高 。
训练与推理成本优化
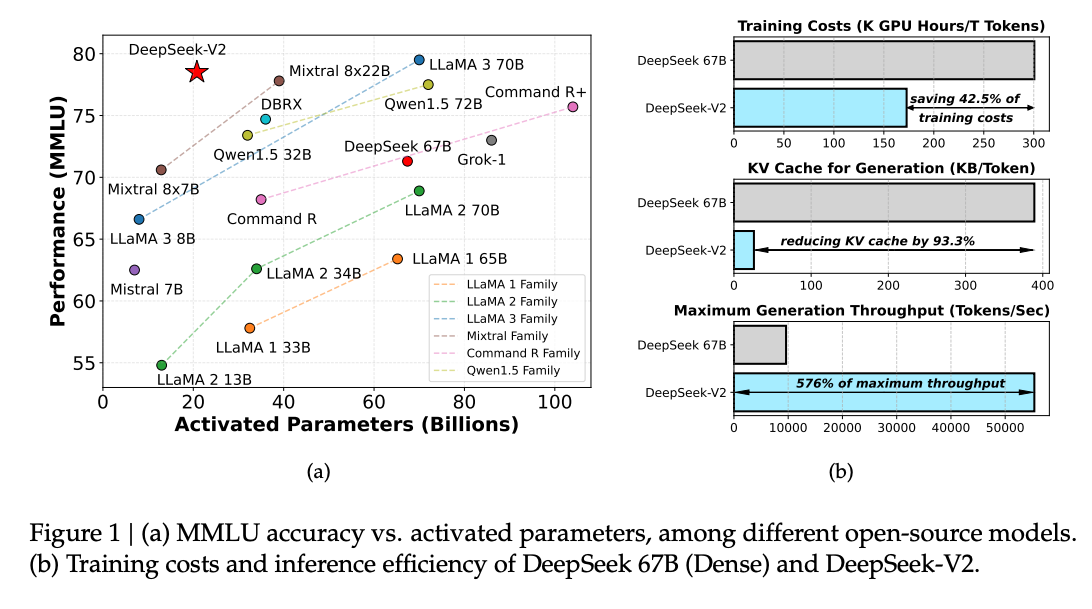
- 训练成本降低 42.5%:相比 DeepSeek 67B,DeepSeek-V2 在保持更强性能的同时,显著减少了训练所需的计算资源 。
- KV 缓存减少 93.3%:通过引入新的注意力机制 Multi-head Latent Attention(MLA),大幅压缩了 KV 缓存需求,从而降低了部署和推理成本 。
- 生成速度提升 5.76 倍:在相同硬件条件下,DeepSeek-V2 的输出速度远超前代模型,提升了实际应用中的响应效率 。
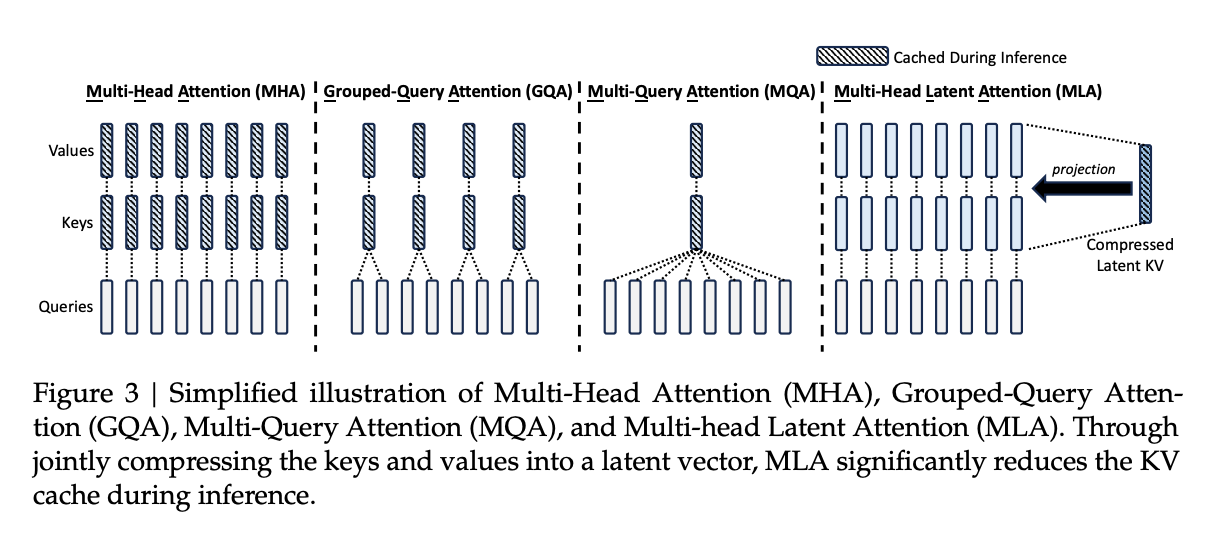
Multi-head Latent Attention(MLA)
- 这是 DeepSeek-V2 引入的一项关键技术,用于替代传统的多头注意力机制
- MLA 通过引入潜在空间(latent space)进行注意力计算,减少了计算复杂度和内存占用,进一步提升了推理效率
- 它不仅降低了 KV 缓存的需求,还使得模型能够支持更大的 batch size,从而提升整体吞吐量
DeepSeek-V2还支持 最长 128K tokens 的上下文长度
MLA
- MLA 引入了一个 潜在空间(latent space),将原始的高维 Key 和 Value 向量映射到一个低维空间中进行存储。
- 具体来说,模型先计算一个低秩的“压缩表示”
,然后在需要时通过矩阵变换恢复出 Key 和 Value:
- 这种方法被称为 Low-Rank Key-Value Compression,大幅减少了存储需求,从而降低了 KV Cache 的占用 。
MLA 与其他注意力机制的对比
| 方法 | 头数 | Key/Value 存储方式 | KV Cache 占用 | 性能影响 |
|---|---|---|---|---|
| MHA(多头注意力) | 多头 | 每个头独立存储 | 高 | 最佳 |
| GQA(Grouped Query Attention) | 多组共享 | 组内共享 Key/Value | 中等 | 稍有下降 |
| MQA(Multi-Query Attention) | 单头 | 所有头共享 Key/Value | 低 | 明显下降 |
| MLA(Multi-Head Latent Attention) | 多头 | 压缩后的潜在向量 | 极低 | 接近 MHA |
- MLA 在保持多头注意力灵活性的同时,通过低秩压缩实现了接近 MQA 的显存效率,且性能损失极小 。
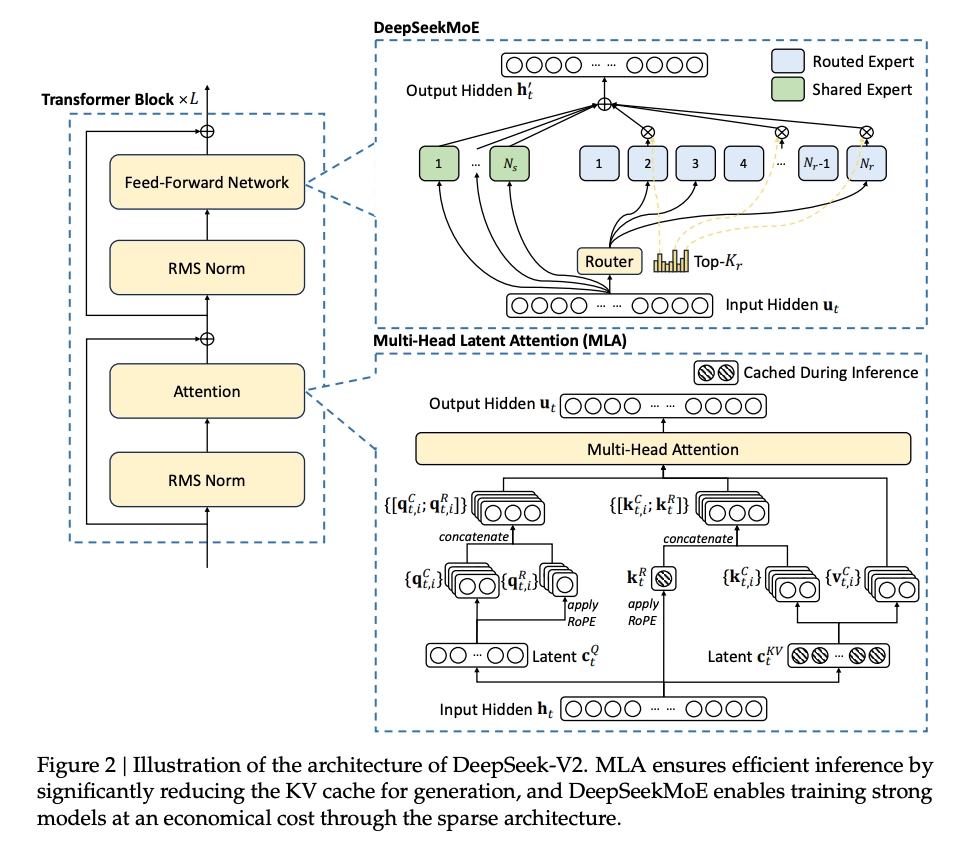
KV Cache
- 在传统的 Transformer 模型中,多头注意力机制(MHA) 需要存储大量 Key 和 Value 向量(即 KV Cache),以加速生成过程中的自回归推理。
- 这些向量的存储会占用大量 GPU 显存,尤其是在处理长上下文时,成为部署成本的主要瓶颈。
- DeepSeek-V2 提出 Multi-Head Latent Attention(MLA),旨在通过压缩 KV Cache 来显著降低推理时的显存占用和计算开销。
KV Cache 压缩效果 - 实验表明,MLA 可将 KV Cache 减少 93%,使得模型在长文本生成任务中更加高效。 - 例如,在生成 128K token 的任务中,MLA 显著降低了内存占用,提升了吞吐量和响应速度 。
说一下为什么kv cache不cache q,q不是也包含历史信息了吗,怎么不把q缓存一下?
因为transformer是自回归模型,每一次的结果都被当成新的q,所以缓存起来没意义,它只用一次,是动态变化的。而k和v则是需要经常复用,所以每次模型输出结果后,只需要把最新的token向量拿出来,进行权重矩阵计算后,直接和缓存后的k和v拼接在一起, 而不像以前需要每个token进行权重矩阵的重复计算。所以kv cache节约的是,k和v与对应权重矩阵的计算。
与 GQA 的对比
- 传统的 GQA通过共享部分head来减少 KV Cache 的大小。例如,16 个头分成 4 组,每组共享 K/V。
- MLA 相当于使用了 约 2.25 个 group 的 GQA,但性能远优于同等 group 数量的 GQA,即在更小的显存消耗下保持了更高的模型效果 。
小结
| 方面 | DeepSeek 的做法 |
|---|---|
| 注意力机制 | 提出 MLA,显著压缩 KV Cache,提升推理效率 |
| MoE 架构 | 使用大量专家(如 160 个),提升稀疏性和模型表达能力 |
| 平衡策略 | 注重专家和设备间的负载均衡,提高训练效率和资源利用率 |
| 原创文章 | |
| 1 | FFN前馈网络与激活函数技术解析:Transformer模型中的关键模块 |
| 2 | Transformer掩码技术全解析:分类、原理与应用场景 |
| 3 | 【大模型技术】Attention注意力机制详解一 |
| 4 | Transformer核心技术解析LCPO方法:精准控制推理长度的新突破 |
| 5 | Transformer模型中位置编码(Positional Embedding)技术全解析(二) |
| 6 | Transformer模型中位置编码(Positional Embedding)技术全解析(一) |
| 7 | 自然语言处理核心技术词嵌入(Word Embedding),从基础原理到大模型应用 |
| 8 | DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 |
| 9 | 【Tokenization第二章】分词算法深度解析:BPE、WordPiece与Unigram的原理、实现与优化 |
| 10 | Tokenization自然语言处理中分词技术:从传统规则到现代子词粒度方法 |
| 11 | [预训练]Encoder-only架构的预训练任务核心机制 |
| 12 | 【第一章】大模型预训练全解析:定义、数据处理、流程及多阶段训练逻辑 |
| 13 | (第一章)深度学习标准化技术综述: 从BatchNorm到DeepNorm的演进与实战 |
| 14 | Transformer架构解析:Encoder与Decoder核心差异、生成式解码技术详解 |