淘宝客如何做网站互联网营销师证书是国家认可的吗
一、基础知识
1.1导入库
- torch 是一个深度学习框架,用于处理张量和神经网络。
- modelscope是由阿里巴巴达摩院推出的开源模型库。
- AutoTokenizer 是ModelScope 库的类,分词器应用场景包括自然语言处理(NLP)中的文本分类、信息抽取、问答、摘要、翻译和文本生成等任务。它通过提供一个统一的接口,使得开发者可以快速且方便地加载和使用不同的预训练模型,而不需要深入了解每个模型的细节;
- AutoModel 是ModelScope 库的类,允许用户在不知道具体模型细节的情况下,根据给定的模型名称或模型类型自动加载相应的预训练模型。
- snapshotdownload 是 ModelScope 提供的一个函数,便于下载模型文件。
1.2下载模型
model_dir=snapshot_download("ZhipuAI/chatglm3-6b",revision"v1.0.0")
model_dir是模型下载后的存储路径。使用snapshot_download 函数下载指定版本的模型。有两种方式,
- 第一种方式,使用本地的模型路径
model_dir=snapshot_download("本地路径/chatglm3-6b",revision"v1.0.0")- 第二种方式,默认从modelscope下载 ZhipuAI/chatglm3-6b 的 v1.0.0 版本,见示例代码。这种方式需要在终端使用pip install modelscope来安装。snapshot_download 函数中的模型名称和版本可以通过搜索魔搭社区来查找。
魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。![]() https://www.modelscope.cn/models
https://www.modelscope.cn/models
1.3加载分词器
tokenizer=AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)使用 AutoTokenizer.frompretrained 方法加载预训练的分词器。其中,trustremotecode=True 表示信任远程代码。
1.4加载模型
with torch.no_grad():model=AutoModel.from_pretrained(model_dir,trust_remote_code=True).cpu().float()1.4.1with torch.nograd()
with torch.nograd():表示在这个上下文中不计算梯度,以节省内存和计算资源。
Python中的with语句是一种用于简化资源管理的语法结构,通过上下文管理器协议(实现__enter__和__exit__方法)自动确保资源的获取和释放,常用于文件操作、数据库连接、线程锁等场景。
with 上下文管理器 as 变量:# 执行代码块1.4.2AutoModel.frompretrained方法
AutoModel.frompretrained方法加载预训练的模型。其中,
- .trustremotecode=True表示信任远程代码。
- .cpu() 将模型移动到 CPU 上。
- .float() 将模型的参数转换为浮点数类型。
针对当前模型,若使用GPU,可以将.cpu() 替换为.cuda()。此时,.float()是首选,float32提供较高的精度;.half()是float16,与float相比,内存减半。还可以通过.quantize()来选择模型量化方式:
- .quantize(8)是INT8量化,表示将模型的权重和激活值量化为8位整数
- .quantize(4)是INT4量化,表示将模型的权重和激活值量化为4位整数,但不是所有的硬件都支持INT4量化。(示例如下)
with torch.no_grad():model=AutoModel.from_pretrained(model_dir,trust_remote_code=True).quantize(8).cuda()1.5设置模型为评估模式
model=model.eval()model.eval() 将模型设置为评估模式,不启用 Batch Normalization 和 Dropout ,确保模型在测试和推理阶段的行为与训练阶段有所不同,从而提高结果的稳定性和准确性。。Batch Normalization 在训练过程中会对每一特征维做归一化操作,对每一批量输入算出 mean 和 std,而在 eval 模式下 BN 层将能够使用全部训练数据的均值和方差,即测试过程中不再针对测试样本计算mean和std,而是直接用训练好的值。
1.6第一次交互
responses,history=model.chat(tokenizer,"你好",history=[])
print(responses)- 使用 model.chat() 方法与模型进行交互,输入是 “你好”,初始历史记录为空列表
[]。 - print(responses) 打印模型的回复。其中,responses 是模型的回复,history 是更新后的历史记录。
1.7第二次交互
responses,history=model.chat(tokenizer,"快乐学习大模型开发的方法",history=history)
print(responses)- 使用 model.chat() 方法与模型进行交互,输入是 “快乐学习大模型开发的方法”,历史记录是上一次交互的历史记录。
- print(responses) 打印模型的回复。
二、大模型问答交互【CPU版】
2.1代码
import torch
from modelscope import AutoTokenizer,AutoModel,snapshot_download#终端运行pip install modelscope
#模型下载的默认路径为C:\Users\Administrator\.cache\modelscope\hub\models\
model_dir=snapshot_download("ZhipuAI/chatglm3-6b",revision="v1.0.0")
tokenizer=AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)with torch.no_grad():model=AutoModel.from_pretrained(model_dir,trust_remote_code=True).cpu().float()model=model.eval()
responses,history=model.chat(tokenizer,"你好",history=[])
print(responses)
responses,history=model.chat(tokenizer,"快乐学习大模型开发的方法",history=history)
print(responses)
2.2运行结果
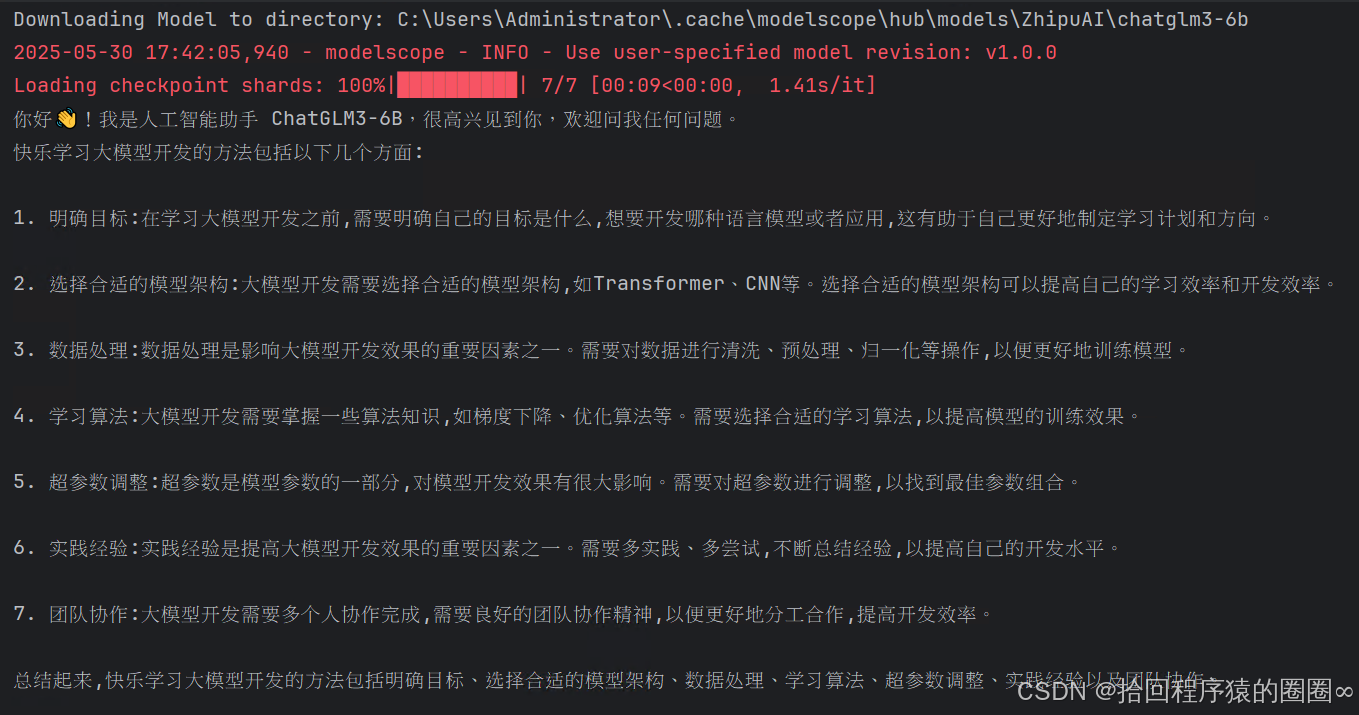
2.3问题与解决
问题一:'torchvision' has no attribute 'extension'
解决一:重新安装torchvision
pip uninstall torchvision
pip install torchvision问题二:TypeError: ChatGLMTokenizer._pad() got an unexpected keyword argument 'padding_side'
解决二:transformers版本问题,安装4.41.2版本
pip install transformers==4.41.2三、大模型问答交互【GPU版】
3.1代码
import torch
from modelscope import AutoTokenizer,AutoModel,snapshot_download#终端运行pip install modelscope
#模型下载的默认路径为C:\Users\Administrator\.cache\modelscope\hub\models\
model_dir=snapshot_download("ZhipuAI/chatglm3-6b",revision="v1.0.0")
tokenizer=AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)with torch.no_grad():model=AutoModel.from_pretrained(model_dir,trust_remote_code=True).quantize(8).cuda()model=model.eval()
responses,history=model.chat(tokenizer,"你好",history=[])
print(responses)
responses,history=model.chat(tokenizer,"快乐学习大模型开发的方法",history=history)
print(responses)
3.2运行结果
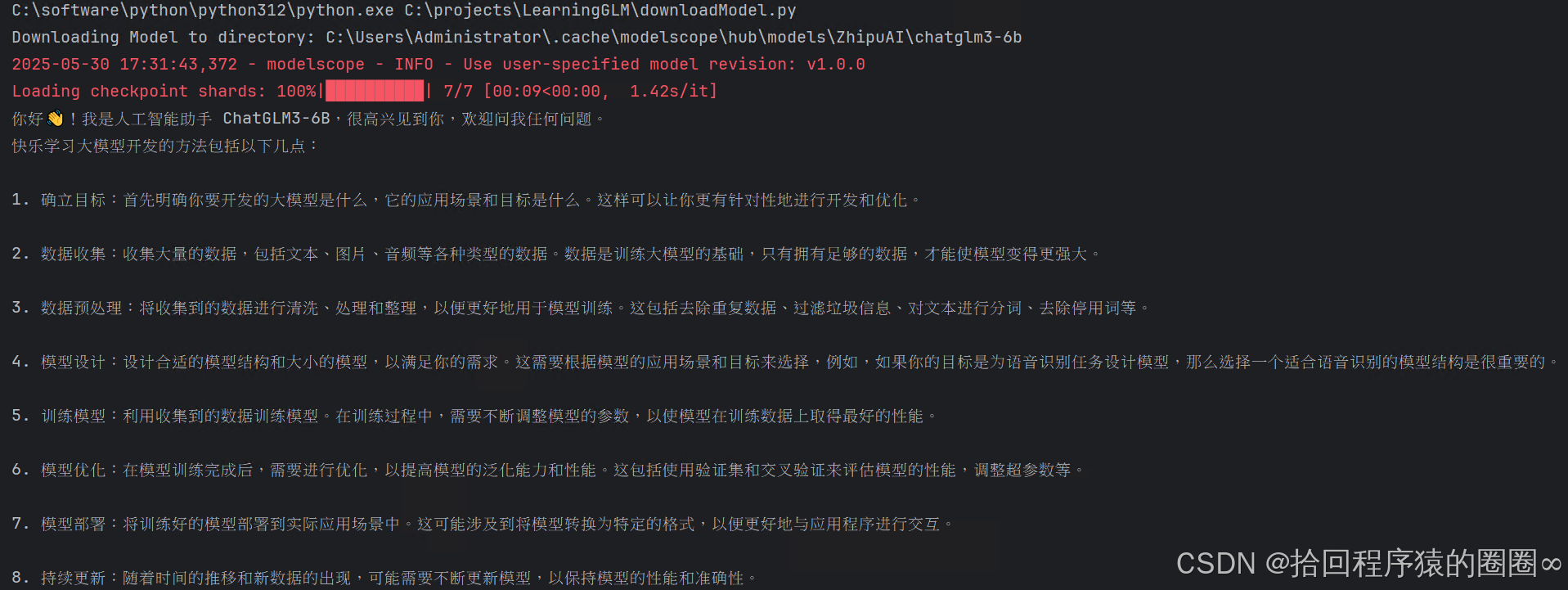
3.3问题与解决
问题一:AssertionError:Torch not complied with CUDA enable
解决一:PyTorch和CUDA版本不匹配
问题二:TypeError: ChatGLMTokenizer._pad() got an unexpected keyword argument 'padding_side'
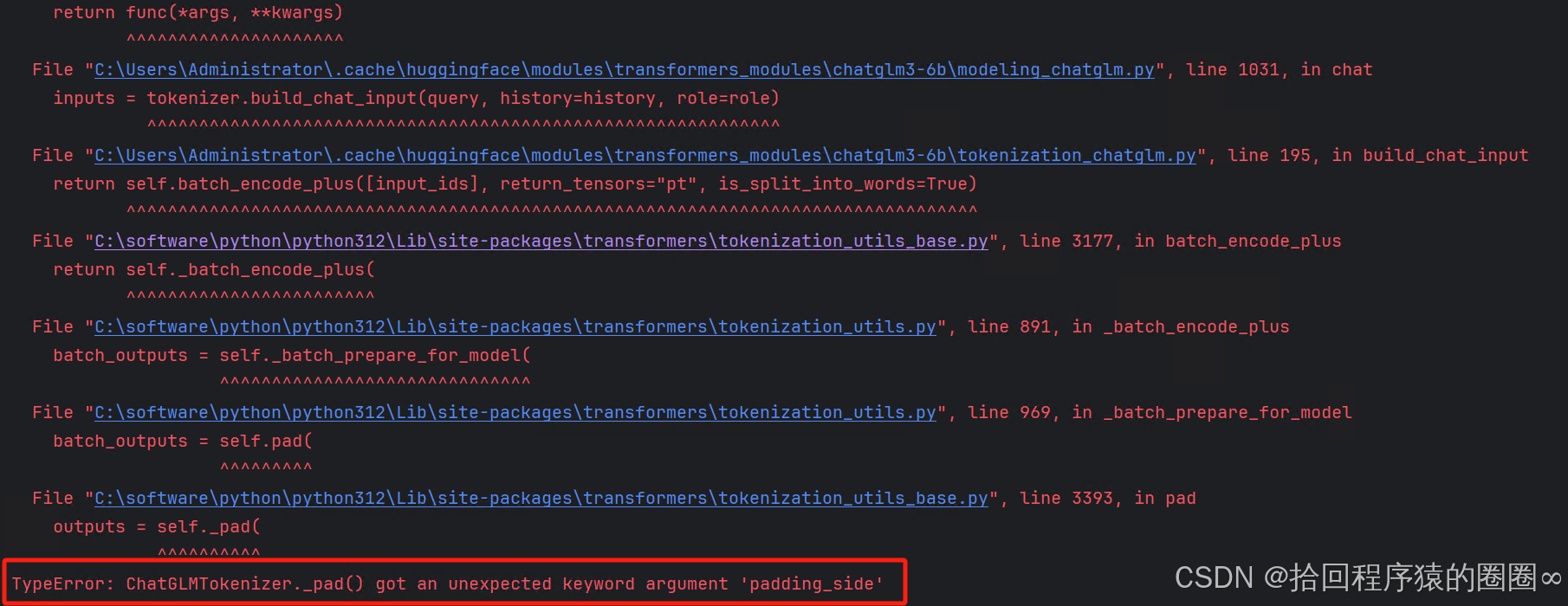
解决二:安装transformers版本问题,安装4.41.2版本
pip install transformers==4.41.2