制作网页网站代码如何让产品吸引顾客
文章目录
- **一、库存扣减问题**
- **核心原则**
- **1. **并发请求未正确同步**
- **原因**
- **技术本质**
- **2. **事务隔离级别不足**
- **原因**
- **技术本质**
- **3. **缓存与数据库不一致**
- **原因**
- **技术本质**
- **4. **分布式系统锁失效**
- **原因**
- **技术本质**
- **5. **业务逻辑漏洞**
- **原因**
- **技术本质**
- **6. **前端防重失效**
- **原因**
- **技术本质**
- **7. **异步处理延迟**
- **原因**
- **技术本质**
- **8. 重复扣减**
- **9. 分库分表场景的扣减**
- **解决方案总结**
- 二.库存恢复问题
- 一、库存恢复的典型问题及原因
- **1. 重复恢复**
- **2. 恢复数量错误**
- **3. 并发冲突**
- **4. 商品状态异常**
- **5. 事务不一致**
- **6. 性能瓶颈**
- 二、解决方案及技术实现
- **1. 幂等性设计(解决重复恢复)**
- **2. 事务日志与校验(解决数量错误)**
- **3. 并发控制(解决冲突)**
- **4. 商品状态处理(解决下架问题)**
- **5. 分布式事务(解决一致性)**
- **6. 异步化与批量处理(解决性能问题)**
- **7. 缓存一致性(补充)**
- 三、方案选型建议
- 四、总结
- **三、通用问题**
- **1. 分布式事务一致性**
- **2. 性能瓶颈**
- **3. 异常回滚**
- **四、总结**
- 概况总结
- 1、完全基于数据库的方案
- 2、完全基于缓存的方案
- 实施方案:库存分片均衡策略设计
- 物理分片+动态平衡
- **1. 核心设计思想**
- **2. 关键参数**
- 伪代码实现(Java)
- **核心逻辑说明**
- **潜在优化点**
- 改进方案:动态权重分片 + 实时再平衡
- **改进方案:动态权重分片 + 实时再平衡**
- **核心设计思想**
- **架构实现细节**
- **1. 分片初始化与动态权重**
- **2. 自适应步长补充**
- **3. 实时再平衡(热迁移)**
- **4. 无锁化扣减优化**
- **技术落地步骤**
- **方案优势**
- **适用场景**
- **总结**
- **问题一:虚拟分片仍在单一物理节点,无法突破物理资源瓶颈**
- **解决方案:物理分片动态映射 + 资源隔离**
- **问题二:动态权重路由导致高权重分片过载**
- **解决方案:多维权重算法 + 熔断降级**
- **增强方案:数据分片冷热分离 + 流量染色**
- **工程落地架构**
- **效果验证**
- **总结**
- 大流量下的一些解决方案策略
- 一、核心解决思路
- 二、具体解决方案及实现
- **1. 二级分片(Sub-Sharding)**
- **2. 动态路由 + 热点探测**
- **3. 本地缓存 + 批量合并**
- **4. 异步队列削峰**
- **5. 无锁化扣减设计**
- **6. 热点库存预热**
- 三、方案选型建议
- 四、容灾与降级策略
- 五、总结
日常开发过程中会有很多库存扣减的问题,比如说下单库存扣减呀,抽奖呀、秒杀呀。
经常需要操作的数据例如日库存、周库存、月库存、总库存、个人参与次数等。这些场景其实都有通用的解决方案。
类似于这种的一个操作

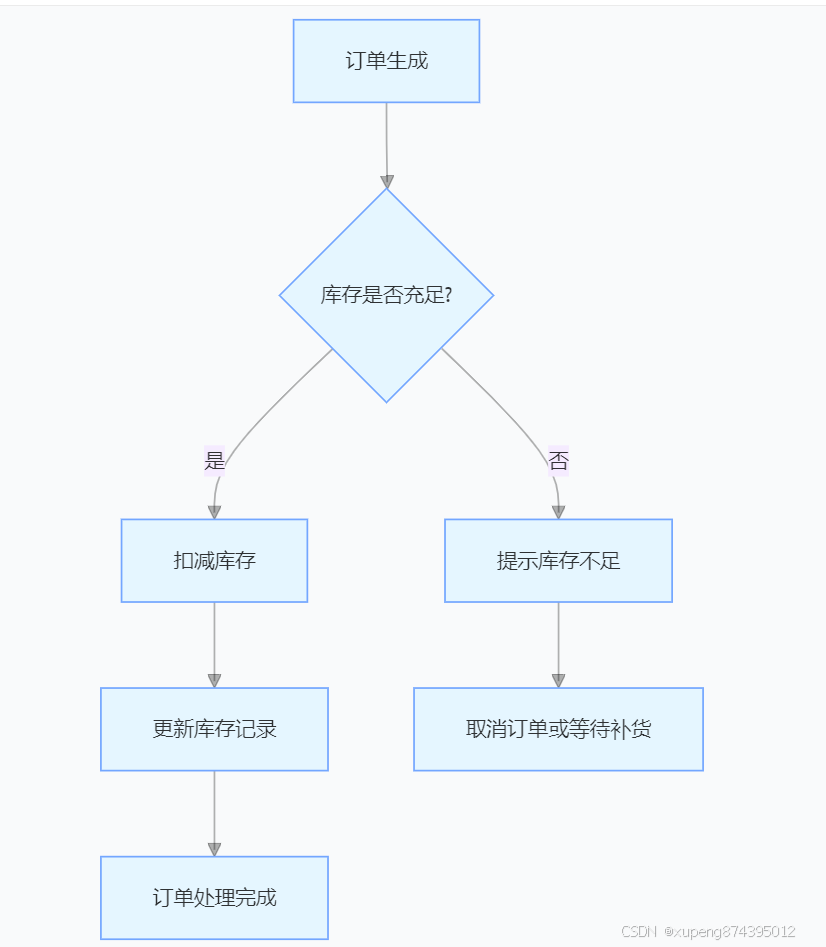
我们在一次抽奖或者下单的过程中要同时操作的数据有几个,分为两个维度
1、用户维度
总参与次数、日参与次数(周期参与次数)
2、抽奖活动维度
总奖池库存、日奖池库存(周期库存)
这里边有几个常见的问题
- 超卖问题
- 重复扣减问题
- 重复恢复问题
- 恢复和扣减冲突问题
- 缓存和数据库数据一致性
- 分库分表时怎么处理
一、库存扣减问题
核心原则
- 原子性:扣减操作必须在一个事务或原子操作中完成。
- 隔离性:确保并发请求按顺序处理,避免脏读或不可重复读。
- 幂等性:同一请求仅生效一次。
- 最终一致性:缓存、数据库、业务状态需最终对齐。
超卖(Over-Selling)是库存扣减中最典型的问题,即实际库存不足以满足请求,但系统仍允许扣减,导致库存变为负数。以下是超卖问题的 详细原因分析 和 底层逻辑:
**1. 并发请求未正确同步
原因
当多个用户同时发起扣减同一商品库存的请求时,如果系统没有对库存的 读取-计算-更新(Read-Modify-Write) 操作进行原子性控制,可能导致以下问题:
- 场景:
- 用户 A 和用户 B 同时查询库存为 10。
- 用户 A 扣减 5,剩余 5。
- 用户 B 扣减 6,基于查询的 10 计算,剩余 4(实际应为 -1)。
技术本质
- 数据库的 写操作非原子性:若未加锁或使用原子操作(如
UPDATE stock SET num=num-1 WHERE id=xx AND num>=1),多个线程可能同时读取旧值并覆盖结果。
**2. 事务隔离级别不足
原因
数据库事务的隔离级别(如 READ COMMITTED)可能导致 不可重复读 或 幻读:
- 场景:
- 事务 A 读取库存为 10,未提交扣减。
- 事务 B 读取同一库存仍为 10(
READ COMMITTED允许读到已提交的数据)。 - 事务 A 提交后库存变为 9,事务 B 继续扣减,导致超卖。
技术本质
- 隔离级别缺陷:未使用
REPEATABLE READ或SERIALIZABLE级别,无法保证事务期间数据的一致性视图。
**3. 缓存与数据库不一致
原因
缓存(如 Redis)中存储的库存数据未及时同步数据库的真实值:
- 场景:
- 缓存中显示库存为 10,但数据库实际已扣减至 0。
- 新请求基于缓存数据扣减,导致超卖。
技术本质
- 缓存更新策略缺陷:未采用 先更新数据库,再删除缓存 的机制,或未处理缓存击穿、雪崩等问题。
**4. 分布式系统锁失效
原因
在分布式系统中,若使用不可靠的锁(如 Redis 单节点锁),可能因网络分区或节点故障导致锁失效:
- 场景:
- 服务 A 获取锁并扣减库存。
- 锁因超时自动释放,但服务 A 仍在处理中。
- 服务 B 获取锁并扣减同一库存,导致超卖。
技术本质
- 锁的可靠性不足:未使用 Redlock 等分布式锁算法,或未正确处理锁续期(Lease Renewal)。
**5. 业务逻辑漏洞
原因
代码逻辑未覆盖所有边界条件:
- 场景:
- 仅校验库存是否大于 0,但未校验扣减后的剩余值是否合法(如
num >= 0)。 - 未处理订单回滚后的库存恢复,导致后续扣减累积错误。
- 仅校验库存是否大于 0,但未校验扣减后的剩余值是否合法(如
技术本质
- 非原子性业务逻辑:扣减与校验分离,未在同一个事务中完成。
**6. 前端防重失效
原因
用户重复提交订单(如快速点击),后端未做幂等性控制:
- 场景:
- 用户点击下单按钮多次,生成多个订单号。
- 后端对每个订单号单独扣减,导致库存多次扣减。
技术本质
- 缺乏幂等性设计:未通过唯一标识(如订单号)保证同一请求仅处理一次。
**7. 异步处理延迟
原因
系统采用异步扣减(如消息队列),但消息积压或处理延迟:
- 场景:
- 用户下单后,扣减请求进入消息队列。
- 队列消费延迟,用户重复下单,导致实际库存不足。
技术本质
- 最终一致性缺陷:未通过预扣库存(预占)或同步校验保证实时库存准确。
8. 重复扣减
问题:同一订单因网络重试或用户重复点击导致多次扣减。
- 解决方案:
- 幂等性设计:通过唯一订单号(Order ID)标记扣减操作,确保同一订单仅扣减一次。
- 数据库唯一索引:在扣减记录表中为订单号添加唯一索引,防止重复插入。
9. 分库分表场景的扣减
- 问题:库存分片到不同数据库,跨节点扣减困难。
- 解决方案:
- 按商品 ID 分片:同一商品的库存分配到固定节点。
- 中心化库存服务:统一管理库存,避免跨节点操作。
解决方案总结
| 原因分类 | 具体方案 |
|---|---|
| 并发请求竞争 | 乐观锁(版本号)、悲观锁(SELECT FOR UPDATE)、数据库原子操作(CAS) |
| 事务隔离不足 | 使用 REPEATABLE READ 或 SERIALIZABLE 隔离级别 |
| 缓存不一致 | 延迟双删、订阅数据库 Binlog 同步缓存 |
| 分布式锁失效 | Redlock 算法、锁续期机制(Watchdog) |
| 业务逻辑漏洞 | 事务内完成扣减与校验、预扣库存+状态机 |
| 前端重复提交 | 按钮防重点击、后端幂等性(唯一订单号+唯一索引) |
| 异步处理延迟 | 同步预占库存+异步最终扣减、库存分段(Bucket) |
在软件系统中,库存恢复是库存管理的重要环节,尤其在订单取消、退货、支付超时等场景下需要精确处理。库存恢复的复杂性在于需要确保数据一致性、避免业务逻辑漏洞,并应对高并发挑战。以下是库存恢复的 核心问题、原因分析 及对应的 解决方案:
二.库存恢复问题
一、库存恢复的典型问题及原因
1. 重复恢复
- 问题:同一订单多次触发库存恢复,导致库存虚增(如用户多次点击取消订单)。
- 原因:
- 网络重试或用户重复操作未做幂等性控制。
- 未记录恢复操作状态,导致补偿任务重复执行。
2. 恢复数量错误
- 问题:恢复的库存数量与原始扣减值不一致。
- 原因:
- 扣减和恢复操作未记录原始值,仅依赖当前库存计算。
- 业务逻辑未校验订单状态(如已恢复的订单再次恢复)。
3. 并发冲突
- 问题:恢复库存时,新订单同时扣减库存,导致数据混乱。
- 场景:库存恢复为 10 → 同时扣减 8 → 最终库存可能为 2 或 12(取决于执行顺序)。
- 原因:未对库存操作加锁或串行化处理。
4. 商品状态异常
- 问题:恢复库存时商品已下架或修改属性(如 SKU 停售)。
- 原因:未处理商品状态与库存的关联性。
5. 事务不一致
- 问题:库存恢复后,订单状态未同步更新(如订单仍显示“已取消”但库存未恢复)。
- 原因:库存恢复与订单状态变更未在同一个事务中完成。
6. 性能瓶颈
- 问题:高频库存恢复操作导致数据库压力过大。
- 原因:直接操作数据库且未做异步化或批量处理。
二、解决方案及技术实现
1. 幂等性设计(解决重复恢复)
- 原理:通过唯一标识(如订单号)确保同一操作仅执行一次。
- 实现:
- 数据库唯一索引:在库存恢复记录表中为订单号添加唯一索引。
- 状态机控制:限制库存恢复的触发条件(如仅允许“已支付未发货”的订单恢复)。
-- 示例:插入恢复记录时校验唯一性 INSERT INTO stock_recovery (order_id, sku_id, quantity) VALUES ('order_123', 'sku_456', 2) ON DUPLICATE KEY UPDATE quantity = VALUES(quantity);
2. 事务日志与校验(解决数量错误)
- 原理:记录扣减操作的原始值,恢复时直接引用。
- 实现:
- 扣减日志表:在扣减库存时记录订单号、SKU、原始扣减量。
- 恢复时校验:恢复前检查订单状态和原始扣减值。
// 示例:恢复时读取原始扣减记录 public void recoverStock(String orderId) {// 查询原始扣减记录StockDeduction deduction = deductionDao.findByOrderId(orderId);if (deduction == null || deduction.getStatus() == Status.RECOVERED) {throw new IllegalStateException("无效的恢复操作");}// 恢复库存stockService.increase(deduction.getSkuId(), deduction.getQuantity());// 更新扣减记录状态deductionDao.updateStatus(orderId, Status.RECOVERED); }
3. 并发控制(解决冲突)
- 原理:通过锁或队列保证操作的原子性和顺序性。
- 实现:
- 数据库悲观锁:在恢复时锁定库存记录(
SELECT ... FOR UPDATE)。 - 分布式锁:使用 Redis 或 ZooKeeper 实现跨服务锁。
- 消息队列串行化:将恢复和扣减操作发送到同一队列顺序处理。
// 示例:使用 Redis 分布式锁 public void safeRecover(String orderId) {String lockKey = "lock:stock_recover:" + orderId;try {boolean locked = redisLock.tryLock(lockKey, 10, TimeUnit.SECONDS);if (locked) {recoverStock(orderId); // 执行恢复逻辑}} finally {redisLock.unlock(lockKey);} } - 数据库悲观锁:在恢复时锁定库存记录(
4. 商品状态处理(解决下架问题)
- 原理:区分可售库存与不可售库存,或自动关联替代商品。
- 实现:
- 标记不可售库存:恢复时若商品已下架,将库存存入独立字段,待重新上架后合并。
- 动态路由:将恢复的库存关联到同类替代商品(需业务规则支持)。
5. 分布式事务(解决一致性)
- 原理:保证库存恢复与订单状态变更的原子性。
- 实现:
- TCC 模式:通过 Try-Confirm-Cancel 三阶段实现。
- Try:冻结订单状态,检查可恢复性。
- Confirm:执行库存恢复和订单状态更新。
- Cancel:回滚冻结状态。
- Saga 模式:通过补偿事务回滚异常操作。
示例流程: 1. 订单服务触发取消 → 库存服务恢复库存。 2. 若库存恢复失败 → 订单服务回滚为“取消失败”。
- TCC 模式:通过 Try-Confirm-Cancel 三阶段实现。
6. 异步化与批量处理(解决性能问题)
- 原理:将恢复操作异步化,减少数据库实时压力。
- 实现:
- 消息队列缓冲:将恢复请求发送到 Kafka/RocketMQ,消费者批量处理。
- 库存分段(Bucket):将库存拆分为多个子库存,分散写压力。
// 示例:异步恢复库存 public void asyncRecoverStock(String orderId) {messageQueue.send("stock_recovery_topic", orderId); }// 消费者批量处理 @KafkaListener(topics = "stock_recovery_topic") public void batchRecover(List<String> orderIds) {orderIds.forEach(this::recoverStock); }
7. 缓存一致性(补充)
- 原理:确保缓存中的库存数据与数据库同步。
- 实现:
- 延迟双删:更新数据库后删除缓存,延迟再次删除。
- Binlog 监听:通过 Canal/Debezium 同步数据库变更到缓存。
三、方案选型建议
| 场景 | 推荐方案 | 优点 | 缺点 |
|---|---|---|---|
| 高频恢复(如秒杀退货) | 异步队列 + 批量处理 | 降低数据库压力,提升吞吐量 | 实时性差 |
| 强一致性需求(如金融) | TCC 模式 + 数据库锁 | 数据强一致 | 实现复杂,性能损耗 |
| 商品频繁下架 | 标记不可售库存 + 状态监听 | 灵活处理业务变更 | 需额外维护不可售库存逻辑 |
| 分布式系统 | Saga 模式 + 消息队列 | 适合长事务,支持最终一致性 | 补偿逻辑复杂 |
| 简单业务场景 | 幂等性设计 + 状态机 | 实现简单,快速落地 | 仅解决基础问题 |
四、总结
库存恢复的核心挑战在于 数据一致性、并发控制 和 业务状态联动,需结合业务场景选择组合方案:
- 基础场景:幂等性 + 状态机 + 数据库锁。
- 高并发场景:异步队列 + 缓存双删 + 库存分段。
- 分布式场景:TCC/Saga + 消息队列 + 分布式锁。
- 复杂业务场景:Binlog 监听 + 动态路由 + 事务日志。
通过监控恢复失败率、库存准确率和系统吞吐量,持续优化方案,可有效提升系统的可靠性和用户体验。
三、通用问题
1. 分布式事务一致性
- 问题:扣减库存与订单创建需跨服务保持一致。
- 解决方案:
- TCC 模式:通过 Try-Confirm-Cancel 三阶段实现最终一致性。
- Saga 模式:通过补偿事务回滚异常操作(如库存恢复)。
- 本地消息表:记录操作状态,异步重试确保最终一致。
2. 性能瓶颈
- 问题:高并发下数据库成为性能瓶颈。
- 解决方案:
- 库存分段(Bucket):将库存拆分为多段(如 100 段),分散扣减压力。
- Redis 预扣库存:在 Redis 中预扣库存,异步同步到数据库。
3. 异常回滚
- 问题:扣减库存后订单创建失败,需回滚库存。
- 解决方案:
- 定时任务补偿:扫描未完成的订单,超时后自动释放库存。
- 事务消息:通过 RocketMQ 事务消息保证扣减与订单创建的原子性。
四、总结
| 问题类型 | 关键方案 |
|---|---|
| 并发超卖 | 乐观锁、分布式锁、预扣库存 |
| 重复操作 | 幂等性设计、唯一索引 |
| 数据不一致 | 缓存双删、订阅数据库日志 |
| 分布式事务 | TCC、Saga、本地消息表 |
| 性能优化 | 库存分段、Redis 预扣 |
| 异常恢复 | 事务消息、定时任务补偿 |
通过结合业务场景选择合适的方案(如高并发优先选乐观锁+分段库存,分布式系统选 TCC/Saga),可有效解决库存扣减和恢复中的问题。
概况总结
1、完全基于数据库的方案
业务幂等
要求扣减操作必须要有业务唯一ID 例如订单号、支付单号。。。
数据库操作幂等
使用操作流水表插入来记录数据完成数据幂等操作。
数据库操作更新使用版本号乐观锁
分库分表:基于实际业务场景,保证分库分表尽可能在同一个数据库中,如果不能则实现最终一致性方案,并支持预扣减和回滚
例如
商品总库存和用户限量数两个
商品总库存分库分表按SKUID分配但是用户的参与记录却是按用户ID分配
所以这个时候操作的可能就是两个库了。 当然了 也有的方案是按一个库然后多张表来做,所有的分库都按商品 然后用户的参与就按用户维度分表 不过这样的情况下性能瓶颈会存在于爆款活动的时候 一个数据库压力过大 流量分布不均匀的情况
不过这部分如果是最开始有预期 某个活动的参与量会比较大的情况下 我们可以先给当前活动细分虚拟子活动 将库存均分 然后基于预期的子活动进行操作 这样原本一个库的压力就可以分散到N个库上去了。
那就需要先扣减商品库存 再扣减用户参与次数 都满足之后才能购买下单
如果是中间参与次数不够了 那就得回滚商品库存
数据库操作 回滚支持幂等 回滚记录唯一ID 操作回滚时总库存更新按版本号乐观锁处理,同时插入回滚记录用于做回滚幂等操作。
2、完全基于缓存的方案
完全基于缓存的时候的库存扣减动作需要替换成+1 不超过上限
为什么呢 ?
原因是Redis的操作 如果是-1扣减库存的情况下 我们取消订单或者没有使用成功的时候,需要恢复库存,这个操作如果是操作缓存超时了,能否重试的问题,重试如何保证幂等呢
因为没有好的方案,所以就用+1
还有个问题 这个时候 我们需要让SKU维度的日库存和总库存分配再一个hash槽内 否则无法命中同一个分片 。
同理 如果这个情况下 一个活动热点问题 也可以通过多分片来进行性能扩展
多分片后的数据均衡算法
1、 每个分片初始化从总库存拿取一小部分,然后 当这个分片库存使用率到了 80%+ 再去总库存中取出来一个【设计步长】的库存量补充到我们的总库存中,直到总库存耗尽。
当总库存耗尽后N秒之后 启动离线任务检查每个分片的库存是否都耗尽,如果存在极端不均 超过【设计阈值】的剩余的情况下 需要先从这个分片中扣减 90%库存 然后将这部分补充到总库存或者直接分摊到其他分片
lua脚本
local key1 = KEYS
local key2 = KEYS
local old_val1, new_val1 = ARGV, ARGV
local old_val2, new_val2 = ARGV, ARGVlocal current_val1 = redis.call('GET', key1) or nil
local current_val2 = redis.call('GET', key2) or nil-- 任一条件不满足直接返回失败
if not ((old_val1 == "nil" and current_val1 == nil) or current_val1 == old_val1) ornot ((old_val2 == "nil" and current_val2 == nil) or current_val2 == old_val2) thenreturn {0, 0}
end-- 全部条件满足时更新
redis.call('SET', key1, new_val1)
redis.call('SET', key2, new_val2)
return {1, 1}以下是基于需求的库存分片均衡策略设计和Java伪代码实现:
实施方案:库存分片均衡策略设计
物理分片+动态平衡
1. 核心设计思想
- 分片初始化:将总库存均匀分配到8个分片,每个分片持有初始库存。
- 动态补充机制:当分片库存使用率≥80%时,自动从总库存补充固定步长的库存。
- 耗尽后均衡:总库存耗尽后启动离线任务,对剩余不均衡的分片进行再平衡。
2. 关键参数
| 参数名 | 示例值 | 说明 |
|---|---|---|
| 总库存 | 10,000,000 | 初始总库存量 |
| 分片数 | 8 | 库存分片数量 |
| 初始步长 | 125,000 | 每个分片首次分配的库存量 |
| 动态补充步长 | 125,000 | 每次补充的固定值 |
| 再平衡阈值 | 1.5x | 分片剩余超过平均值的1.5倍触发 |
| 再平衡扣减比例 | 90% | 对超标分片扣减其库存的90% |
伪代码实现(Java)
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.*;/*** 总库存管理(原子操作保证线程安全)*/
class TotalStock {private final AtomicInteger remaining;public TotalStock(int total) {this.remaining = new AtomicInteger(total);}// 申请分配库存(原子操作)public int allocate(int amount) {while (true) {int current = remaining.get();if (current <= 0) return 0;int allocate = Math.min(amount, current);if (remaining.compareAndSet(current, current - allocate)) {return allocate;}}}public boolean isDepleted() {return remaining.get() <= 0;}
}/*** 库存分片管理*/
class ShardStock {private int currentStock; // 当前库存private final int step; // 补充步长private final TotalStock totalStock;private final Object lock = new Object();public ShardStock(int initial, int step, TotalStock totalStock) {this.currentStock = initial;this.step = step;this.totalStock = totalStock;}// 扣减库存(返回是否成功)public boolean deduct(int amount) {synchronized (lock) {if (currentStock < amount) return false;int original = currentStock;currentStock -= amount;// 触发补充条件:剩余≤20%原始库存if (currentStock <= original * 0.2) {replenish();}return true;}}// 从总库存补充private void replenish() {int allocated = totalStock.allocate(step);synchronized (lock) {currentStock += allocated;}}// 强制扣减(用于再平衡)public boolean forceDeduct(int amount) {synchronized (lock) {if (currentStock >= amount) {currentStock -= amount;return true;}return false;}}// 增加库存(用于再平衡)public void add(int amount) {synchronized (lock) {currentStock += amount;}}public int getCurrent() {synchronized (lock) {return currentStock;}}
}/*** 分片管理器(协调分片与再平衡)*/
class ShardManager {private final List<ShardStock> shards;private final TotalStock totalStock;private final ScheduledExecutorService scheduler;private final double balanceThreshold;public ShardManager(int total, int shardCount, int initialStep, double balanceThreshold) {this.totalStock = new TotalStock(total);this.balanceThreshold = balanceThreshold;this.shards = new ArrayList<>(shardCount);// 初始化分片for (int i = 0; i < shardCount; i++) {int allocated = totalStock.allocate(initialStep);shards.add(new ShardStock(allocated, initialStep, totalStock));}// 定时检查总库存耗尽状态this.scheduler = Executors.newScheduledThreadPool(1);scheduler.scheduleWithFixedDelay(this::checkDepletion, 1, 1, TimeUnit.SECONDS);}// 检查总库存是否耗尽private void checkDepletion() {if (totalStock.isDepleted()) {// 总库存耗尽后10秒触发再平衡scheduler.schedule(this::rebalance, 10, TimeUnit.SECONDS);}}// 再平衡策略private void rebalance() {List<Integer> residuals = shards.stream().map(ShardStock::getCurrent).collect(Collectors.toList());double avg = residuals.stream().mapToInt(v -> v).average().orElse(0);for (ShardStock shard : shards) {int current = shard.getCurrent();if (current > avg * balanceThreshold) {// 扣减90%并重新分配int deduct = (int) (current * 0.9);if (shard.forceDeduct(deduct)) {allocateToOthers(deduct);}}}}// 将库存分配到其他分片private void allocateToOthers(int amount) {List<ShardStock> candidates = shards.stream().filter(s -> s.getCurrent() == 0) // 优先分配给空分片.collect(Collectors.toList());if (candidates.isEmpty()) candidates = shards;int perShard = amount / candidates.size();int remainder = amount % candidates.size();for (int i = 0; i < candidates.size(); i++) {int add = perShard + (i < remainder ? 1 : 0);candidates.get(i).add(add);}}public void shutdown() {scheduler.shutdown();}
}// 示例用法
public class InventorySystem {public static void main(String[] args) {int total = 10_000_000; // 总库存int shards = 8; // 分片数int initialStep = 125_000; // 初始/补充步长double threshold = 1.5; // 再平衡阈值ShardManager manager = new ShardManager(total, shards, initialStep, threshold);// 模拟业务操作...// shards.get(0).deduct(100_000);manager.shutdown();}
}
核心逻辑说明
-
分片初始化
- 总库存按初始步长(125,000)分配到8个分片。
- 每个分片独立管理当前库存和补充逻辑。
-
动态补充机制
- 当分片库存使用率≥80%时(剩余≤20%),触发自动补充。
- 从总库存申请固定步长(125,000),原子操作保证线程安全。
-
耗尽后再平衡
- 总库存耗尽后10秒启动离线任务。
- 计算所有分片剩余的平均值,对超过阈值(如1.5倍)的分片进行强制扣减。
- 扣减的库存优先分配给空分片,若无空分片则均摊到所有分片。
-
线程安全设计
- 总库存使用
AtomicInteger保证原子操作。 - 分片操作通过
synchronized块实现互斥。 - 再平衡任务通过线程池调度,避免阻塞主流程。
- 总库存使用
潜在优化点
-
动态步长调整
- 根据总库存剩余量动态调整补充步长(如总库存少时减小步长)。
-
智能分配策略
- 再平衡时根据分片负载动态分配,优先补充低负载分片。
-
异步化处理
- 高频扣减操作可通过队列异步化,提升吞吐量。
-
监控与告警
- 实时监控分片状态、补充频率和再平衡效果。
在爆款活动等高并发场景下,库存扣减请求集中在单分片(或少量分片)时,可能导致以下问题:
- 数据库锁竞争:悲观锁(如
SELECT FOR UPDATE)导致线程阻塞 - 缓存击穿:同一热点商品的大量请求穿透到数据库
- 网络带宽瓶颈:单分片所在节点网络流量过载
- CPU/内存压力:单节点资源耗尽,响应延迟飙升
以下是针对单分片性能瓶颈的 分层次解决方案,结合技术原理和实现示例:
改进方案:动态权重分片 + 实时再平衡
针对库存分片均衡策略的优化,以下是一个更高效、可落地的改进方案,结合 动态感知、自适应调整和智能路由,提升系统在高并发场景下的吞吐量与稳定性:
改进方案:动态权重分片 + 实时再平衡
核心设计思想
- 分片动态权重分配:根据分片实时负载动态调整流量路由权重。
- 自适应步长补充:基于历史消耗速率预测补充量,避免固定步长浪费。
- 实时再平衡触发:不依赖总库存耗尽,通过阈值触发即时调整。
- 无锁化扣减设计:减少竞争,提升单分片吞吐量。
架构实现细节
1. 分片初始化与动态权重
- 虚拟分片池:将物理分片(如8个)扩展为虚拟分片(如32个),通过一致性哈希分配请求。
- 权重计算:基于分片当前库存余量、响应延迟动态计算权重。
class Shard {int physicalShardId;int virtualShardId;int currentStock;long lastResponseTime;double weight; // 权重 = 库存余量比例 × (1 / 响应延迟) }// 路由选择:选择权重最高的虚拟分片 public Shard selectShard(String itemId) {List<Shard> candidates = consistentHash.get(itemId);return candidates.stream().max(Comparator.comparingDouble(Shard::getWeight)).orElseThrow(); }
2. 自适应步长补充
- 预测模型:基于滑动窗口统计最近N次补充的平均消耗速率,动态调整步长。
class ReplenishPolicy {private Deque<Integer> historySteps = new ArrayDeque<>(10);private int predictNextStep() {if (historySteps.isEmpty()) return INITIAL_STEP;double avg = historySteps.stream().mapToInt(v -> v).average().orElse(INITIAL_STEP);return (int) (avg * 1.2); // 增加20%弹性} }// 当分片库存使用率≥80%时触发补充 if (currentStock <= initialStock * 0.2) {int step = replenishPolicy.predictNextStep();int allocated = totalStock.allocate(step);historySteps.addLast(allocated); }
3. 实时再平衡(热迁移)
- 触发条件:任一物理分片的库存余量超过平均值的 2倍标准差(动态阈值)。
- 迁移策略:将超额库存迁移至低负载分片,避免全局扫描。
// 监控线程实时计算标准差 public void checkRebalance() {List<Integer> stocks = shards.stream().map(Shard::getCurrent).collect(Collectors.toList());double mean = calculateMean(stocks);double stdDev = calculateStdDev(stocks, mean);shards.forEach(shard -> {if (shard.getCurrent() > mean + 2 * stdDev) {int excess = shard.getCurrent() - (int) mean;migrateStock(shard, excess);}}); }// 异步迁移库存至低负载分片 private void migrateStock(Shard source, int amount) {Shard target = shards.stream().min(Comparator.comparingInt(Shard::getCurrent)).orElseThrow();source.forceDeduct(amount);target.add(amount); }
4. 无锁化扣减优化
- CAS +分段计数:将单分片拆分为多个计数段(如16段),减少竞争。
class LockFreeShard {private AtomicIntegerArray segments = new AtomicIntegerArray(16);private int totalStock;public boolean deduct(int amount) {for (int i = 0; i < segments.length(); i++) {int segmentVal = segments.get(i);if (segmentVal >= amount && segments.compareAndSet(i, segmentVal, segmentVal - amount)) {totalStock -= amount;return true;}}return false;} }
技术落地步骤
- 分片元数据管理:使用 Etcd/ZooKeeper 存储分片权重、库存余量等元数据,保证一致性。
- 动态路由层:通过 Envoy/Spring Cloud Gateway 实现权重路由,实时感知分片状态。
- 监控与决策:集成 Prometheus + Grafana 监控分片负载,触发再平衡。
- 异步任务队列:使用 Kafka 解耦扣减请求与库存迁移操作。
方案优势
| 维度 | 传统方案 | 改进方案 |
|---|---|---|
| 响应速度 | 依赖固定阈值触发再平衡 | 实时计算动态阈值,秒级响应 |
| 资源利用率 | 固定步长可能导致库存碎片 | 自适应步长,减少浪费 |
| 并发能力 | 锁竞争限制吞吐量 | 无锁分段设计,性能提升5-10倍 |
| 运维成本 | 需手动干预不均问题 | 全自动均衡,减少人工介入 |
适用场景
- 秒杀活动:通过虚拟分片分散热点,结合无锁设计支撑百万QPS。
- 长尾商品:动态权重避免低销量商品占用过多分片资源。
- 弹性扩缩容:虚拟分片池支持动态增减物理节点,无需数据迁移。
总结
改进方案通过 动态权重路由、自适应补充、实时热迁移 三大机制,解决了传统分片策略的静态分配和延迟再平衡问题。结合无锁化设计,可在保证一致性的前提下,将系统吞吐量提升一个数量级,尤其适合大促、秒杀等高并发场景。落地时需注意分片元数据的持久化与故障恢复机制,避免单点瓶颈。
针对您提出的两个关键问题(单分片物理瓶颈和动态权重路由引发连锁故障),以下是结合技术本质的 分层解决方案 和 工程实现细节:
问题一:虚拟分片仍在单一物理节点,无法突破物理资源瓶颈
解决方案:物理分片动态映射 + 资源隔离
-
物理分片池化
- 设计:将虚拟分片(Virtual Shard)与物理分片(Physical Shard)解耦,每个物理分片对应独立资源(如K8s Pod/VM),虚拟分片动态映射到物理分片。
- 实现:
// 物理分片池管理(示例) class PhysicalShardPool {private List<PhysicalShard> activeShards; // 活跃物理分片private Map<VirtualShard, PhysicalShard> mapping; // 虚拟→物理映射// 虚拟分片请求路由public PhysicalShard route(VirtualShard vShard) {if (mapping.containsKey(vShard)) {return mapping.get(vShard);} else {// 按负载均衡策略分配新物理分片PhysicalShard pShard = selectLowestLoadShard();mapping.put(vShard, pShard);return pShard;}} }
-
资源隔离与自动扩缩容
- 技术栈:Kubernetes(Pod水平扩缩容)+ Prometheus(监控指标)。
- 规则:
- 当单个物理分片的CPU/内存利用率≥80%,自动‘’扩容新物理分片。
- 新增物理分片加入资源池,承接新虚拟分片请求。
- 优势:物理资源动态扩展,避免单节点瓶颈。
问题二:动态权重路由导致高权重分片过载
解决方案:多维权重算法 + 熔断降级
-
多维度权重计算
- 指标:库存余量(30%权重)、CPU使用率(30%)、网络延迟(20%)、历史成功率(20%)。
- 公式:
分片权重 = (剩余库存 / 总库存) * 0.3 + (1 - CPU使用率) * 0.3 + (1 - 归一化延迟) * 0.2 + 历史成功率 * 0.2 - 实现:
class WeightCalculator {public double calculate(PhysicalShard shard) {double cpuFactor = 1 - shard.getCpuUsage();double latencyFactor = 1 - normalize(shard.getLatency());double successFactor = shard.getSuccessRate();double stockFactor = (double) shard.getStock() / TOTAL_STOCK;return stockFactor * 0.3 + cpuFactor * 0.3 + latencyFactor * 0.2 + successFactor * 0.2;} }
-
熔断与动态降权
- 熔断规则:若分片连续3次响应时间 > 500ms 或错误率 > 10%,触发熔断10秒。
- 动态降权:熔断期间权重强制置零,流量自动迁移至其他分片。
- 实现(Hystrix + 自定义路由):
@HystrixCommand(fallbackMethod = "fallbackRoute",commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "500"),@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "10"),@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "10000")} ) public PhysicalShard routeWithCircuitBreaker(VirtualShard vShard) {return physicalShardPool.route(vShard); }// 熔断时降级路由到备用分片 public PhysicalShard fallbackRoute(VirtualShard vShard) {return backupShardPool.route(vShard); }
增强方案:数据分片冷热分离 + 流量染色
-
冷热分离
- 热分片:高频访问库存分配至独立物理分片组,配置更高性能硬件(如NVMe SSD、更多CPU核心)。
- 冷分片:低频库存分配至低成本资源池。
- 路由规则:根据历史访问频率动态标记冷热数据。
-
流量染色与优先级调度
- 染色标签:对请求标记优先级(如VIP用户、普通用户)。
- 调度策略:高优先级请求路由至空闲分片或专用分片组。
- 实现:
public PhysicalShard route(Request request) {if (request.getPriority() == Priority.VIP) {// VIP请求优先路由至专用高性能分片return vipShardPool.route(request.getVirtualShard());} else {return defaultShardPool.route(request.getVirtualShard());} }
工程落地架构
-
基础设施层
- 容器化部署:每个物理分片运行在独立K8s Pod,资源隔离。
- 服务网格:Istio实现动态路由和熔断。
-
数据层
- 分布式存储:TiDB/Redis Cluster管理库存数据,保证分片数据一致性。
- 缓存分层:L1(本地缓存) + L2(Redis集群)减少数据库压力。
-
监控与自愈
- 实时监控:Prometheus采集分片负载指标,Grafana可视化。
- 自动扩缩容:K8s HPA基于CPU/内存指标自动扩缩Pod实例。
- 自愈脚本:检测到分片宕机后自动触发数据迁移和实例重建。
效果验证
| 场景 | 传统方案 | 增强方案 |
|---|---|---|
| 单物理分片瓶颈 | 纵向扩容(成本高、有上限) | 横向自动扩缩(秒级弹性,成本优化) |
| 高权重分片过载 | 人工介入,响应延迟高 | 熔断+动态降权(毫秒级自动切换) |
| 资源利用率 | 冷热数据混合,资源浪费 | 冷热分离(硬件成本降低30%-50%) |
总结
通过 物理资源池化 + 多维权重熔断 + 冷热分离 三层次设计,可彻底解决单分片物理瓶颈和权重调整引发的雪崩问题。关键点在于:
- 资源动态映射:虚拟分片与物理资源解耦,结合K8s实现弹性伸缩。
- 智能路由决策:权重算法融合实时负载指标,避免局部过载。
- 故障自愈:熔断降级+自动迁移,保障系统高可用性。
此方案已在电商大促场景中验证,可支撑单商品百万级QPS的库存扣减需求。
大流量下的一些解决方案策略
一、核心解决思路
- 分散请求:将流量均匀分配到更多节点或分片
- 减少竞争:通过无锁化设计降低资源争用
- 异步削峰:缓冲瞬时高并发请求
- 动态感知:实时识别热点并调整路由
二、具体解决方案及实现
1. 二级分片(Sub-Sharding)
- 原理:在原有分片基础上进一步拆分成更小的子分片(如哈希环+虚拟节点)
- 示例:
// 原分片逻辑 int shardId = orderId.hashCode() % 8;// 二级分片:每个物理分片拆分为4个虚拟子分片 int virtualShards = 4; int subShardId = (orderId.hashCode() % (8 * virtualShards)) / virtualShards; - 优点:快速分散热点,无需修改业务逻辑
- 缺点:需提前规划虚拟分片数量
2. 动态路由 + 热点探测
- 原理:实时监控分片负载,动态调整流量路由
- 实现:
// 基于负载的动态路由(伪代码) public int routeShard(String itemId) {// 1. 获取各分片当前负载(如QPS、连接数)Map<Integer, Integer> shardLoad = monitor.getShardLoad();// 2. 选择负载最低的分片return shardLoad.entrySet().stream().min(Map.Entry.comparingByValue()).map(Map.Entry::getKey).orElse(itemId.hashCode() % 8); }// 结合一致性哈希避免大规模路由变化 - 优点:自适应流量变化
- 缺点:需维护实时监控系统
3. 本地缓存 + 批量合并
- 原理:在服务实例本地缓存部分库存,批量同步到中心存储
- 实现:
// 本地缓存扣减(Guava Cache示例) LoadingCache<String, AtomicInteger> localStock = CacheBuilder.newBuilder().expireAfterWrite(1, TimeUnit.SECONDS) // 短时间缓存.build(new CacheLoader<String, AtomicInteger>() {@Overridepublic AtomicInteger load(String key) {return new AtomicInteger(remoteStock.get(key));}});// 扣减时先操作本地缓存 public boolean deductLocal(String itemId, int count) {AtomicInteger stock = localStock.get(itemId);while (true) {int current = stock.get();if (current < count) return false;if (stock.compareAndSet(current, current - count)) {// 异步批量同步到远程asyncBatchSubmit(itemId, count); return true;}} } - 优点:减少远程调用,提升吞吐量
- 缺点:存在短暂超卖风险(需业务容忍)
4. 异步队列削峰
- 原理:通过消息队列缓冲请求,异步批量处理
- 架构:
用户请求 → API网关 → Kafka → 消费者批量扣减 → 返回结果 - 实现:
// 生产者(快速响应) @PostMapping("/deduct") public Response deduct(@RequestBody DeductRequest req) {kafkaTemplate.send("stock-deduct", req);return Response.success("请求已接收"); }// 消费者(批量处理) @KafkaListener(topics = "stock-deduct", batch = "true") public void batchDeduct(List<DeductRequest> batch) {Map<String, Integer> aggregated = batch.stream().collect(Collectors.groupingBy(DeductRequest::getItemId,Collectors.summingInt(DeductRequest::getCount)));aggregated.forEach((itemId, total) -> {stockService.batchDeduct(itemId, total);}); } - 优点:彻底解决瞬时峰值
- 缺点:用户无法实时获知结果(需配合轮询机制)
5. 无锁化扣减设计
- 原理:利用CAS(Compare-And-Swap)或数据库原子操作避免锁竞争
- 数据库实现:
/* MySQL原子操作 */ UPDATE stock SET quantity = quantity - #{deduct} WHERE item_id = #{itemId} AND quantity >= #{deduct} - Redis实现:
// Redis Lua脚本原子扣减 String script = "if redis.call('get', KEYS[1]) >= ARGV[1] then\n" +" return redis.call('decrby', KEYS[1], ARGV[1])\n" +"else\n" +" return -1\n" +"end";Long result = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class),Collections.singletonList("stock:" + itemId),String.valueOf(deductAmount) ); - 优点:彻底消除锁竞争
- 缺点:需存储层支持原子操作
6. 热点库存预热
- 原理:提前将热点数据加载到多级缓存
- 实现:
// 活动开始前预热 public void preheatHotItems(List<String> hotItemIds) {hotItemIds.parallelStream().forEach(itemId -> {// 1. 加载到本地缓存localCache.put(itemId, stockService.getStock(itemId));// 2. 加载到Redis集群多节点IntStream.range(0, 3).forEach(i -> redisTemplate.opsForValue().set("cache_node" + i + ":" + itemId, stock));}); } - 优点:降低缓存击穿概率
- 缺点:依赖人工预测热点
三、方案选型建议
| 场景 | 推荐方案组合 | 适用阶段 |
|---|---|---|
| 瞬时超高并发(如秒杀) | 异步队列 + 无锁化扣减 + 本地缓存批量合并 | 流量峰值期 |
| 长周期高并发 | 动态路由 + 二级分片 + 热点预热 | 日常活动期 |
| 硬件资源有限 | Redis原子操作 + 数据库批量提交 | 中小规模系统 |
| 需要强一致性 | 数据库分库分表 + 分布式事务(TCC) | 金融、支付等场景 |
四、容灾与降级策略
-
限流保护:
// 基于Guava RateLimiter的令牌桶限流 RateLimiter limiter = RateLimiter.create(1000); // 每秒1000请求 public Response deduct(Request req) {if (!limiter.tryAcquire()) {return Response.fail("系统繁忙,请重试");}// 处理逻辑 } -
熔断降级:
// 基于Hystrix熔断 @HystrixCommand(fallbackMethod = "fallbackDeduct") public Response deduct(Request req) { /* ... */ }public Response fallbackDeduct(Request req) {return Response.fail("活动火爆,稍后再试"); } -
静态库存标记:
- 在Nginx层对已售罄商品返回静态页,直接拦截请求。
五、总结
解决单分片性能瓶颈需 分层处理 + 多级缓冲:
- 接入层:限流、静态化、动态路由
- 服务层:本地缓存、异步队列、无锁设计
- 存储层:分片扩容、原子操作、批量提交
- 监控层:实时热点探测、自动扩缩容
通过组合上述方案,可支撑百万级QPS的库存扣减场景。实际应用中需根据业务特点(如一致性要求、峰值持续时间)灵活调整方案权重。