泸州网站建设哪家好推广app赚佣金接单平台
在自然语言处理(NLP)领域,大型语言模型(LLMs)的开发和训练是一个复杂且成本高昂的过程。数据需求是一个主要问题,因为训练这些模型需要大量的标注数据来保证其准确性和泛化能力;计算资源也是一个挑战,因为需要巨大的算力来处理和训练这些数据。最重要的是经济成本,这包括了硬件投资、电力消耗以及维护费用等。
除了成本问题,模型能力的局限性也是一个关键问题。不同的LLMs可能在特定的任务或领域上表现出色,但可能在其他任务上表现不佳。这种局限性意味着,尽管单个模型可能非常强大,但它们可能无法覆盖所有类型的语言理解和生成任务。另外,模型间的冗余能力也是一个问题,因为不同的模型可能在某些功能上存在重叠,这导致资源和努力的浪费。
为了克服这些挑战,研究者们开始探索知识融合这一概念。知识融合的目标是将多个预训练的LLMs的能力结合起来,形成一个统一的模型,这个模型能够继承所有源模型的优势,并在广泛的任务上表现出色。这种方法不仅可以减少重新训练模型的需求,还可以通过结合不同模型的专长来提高整体性能。

传统模型融合技术通常包括两种方式:
- 集成(Ensemble):这种方法通过直接聚合不同模型的输出来增强预测性能和鲁棒性。这可能涉及到加权平均或多数投票等技术,但它要求在推理时同时维护多个训练好的模型。
- 权重合并(Weight Merging):此方法通过参数级的算术操作直接合并几个神经网络,通常假设网络架构是统一的,并尝试在不同神经网络的权重之间建立映射。
FUSELLM方法则采用了一种新颖的视角:
- 知识外化:FUSELLM通过使用源LLMs生成的概率分布来外化它们的集体知识和独特优势。
- 轻量级持续训练:目标LLM通过这种训练,最小化其概率分布与源LLMs生成的概率分布之间的差异,从而获得提升。
与传统的训练方法相比,知识融合不寻求从头开始训练一个全新的模型,而是通过合并现有的预训练模型来创建一个功能更强大的统一模型。
在传统的训练方法中,每个LLM都是独立训练的,这意味着每个模型都是从零开始学习,需要大量的数据和计算资源。此外,由于每个模型的架构和训练数据可能不同,它们在不同任务上的表现也会有差异。例如,一个模型可能在文本分类任务上表现出色,而在机器翻译任务上则不尽如人意。这种独立训练的方法不仅效率低下,而且无法充分利用已有模型的知识。
知识融合的核心思想是将多个源LLMs的知识进行外化和转移,通过这种方式,目标模型可以继承并整合所有源模型的优势。这一过程的第一步是生成概率分布矩阵,这是通过使用源LLMs对输入文本进行预测来实现的。每个模型都会生成一个表示其对文本理解的概率分布矩阵,这些矩阵随后被用来指导目标模型的训练。
为了解决不同模型间词汇表不一致的问题,研究者们采用了一种新颖的令牌对齐策略,即最小编辑距离(MinED)方法。这种方法通过计算不同模型生成的令牌之间的编辑距离来实现对齐,从而允许不同模型的概率分布矩阵之间进行有效的映射。
接下来是概率分布的融合阶段,这是知识融合方法的关键创新之一。研究者们提出了两种融合函数:最小交叉熵(MinCE)和平均交叉熵(AvgCE)。MinCE方法选择交叉熵损失最小的分布矩阵作为融合结果,而AvgCE方法则根据每个模型的交叉熵损失对所有分布矩阵进行加权平均。这些融合函数的目的是在保留源模型独特优势的同时,整合它们的集体知识。
目标模型通过持续训练进行更新,这个过程涉及到最小化目标模型的概率分布与融合后的概率分布之间的差异。与传统的从头开始训练相比,这种轻量级的持续训练大大减少了所需的资源和时间。

以上是FUSELLM方法的完整过程在算法。FUSELLM算法可以应用于任何需要融合多个预训练LLMs的场景,特别是在资源有限或需要快速提升模型性能的情况下。通过这种方法,研究者和开发者可以有效地利用现有的模型资源,创造出更强大的语言处理能力。
研究者们精心挑选了适合的源LLMs,并对它们进行了融合。实验使用了MiniPile数据集,这是一个经过精简但内容丰富的语料库,它来源于The Pile,包含了约100万文档和1.8亿个token,覆盖了22个不同的领域。
在训练过程中,采用了Llama-2 7B模型作为目标模型,并使用AdamW优化器进行参数更新,同时采用了余弦学习率调度策略,以提高训练效率。
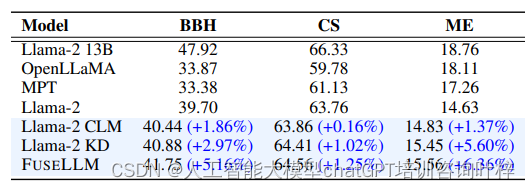
实验结果令人鼓舞,FUSELLM在多个基准测试中展现了其优越性。在Big-Bench Hard (BBH)、Common Sense (CS)和MultiPL-E (ME)等基准测试中,FUSELLM的性能在大多数任务上都超过了单独的源LLMs和基线模型。例如,在BBH任务中,FUSELLM的平均性能提升为5.16%,在CS任务中为1.25%,在ME任务中为6.36%。这些结果表明,FUSELLM能够有效地整合不同源LLMs的知识,并在广泛的任务上提升性能。


研究者们还深入分析了融合概率分布对训练过程的影响。通过比较FUSELLM和单独的Llama-2 CLM(持续语言模型)在不同规模训练数据上的表现,发现FUSELLM在训练过程中能够更快地达到更高的准确率,并且需要的训练token数量显著减少。这一发现证实了融合概率分布包含了比原始文本序列更易于学习的知识,从而加速了优化过程。
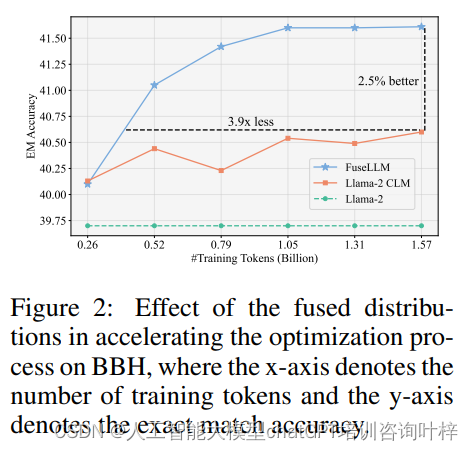
实验还包括了对FUSELLM实现过程中关键元素的分析。这包括了对源LLMs数量的影响、不同令牌对齐标准的效果以及不同融合函数的选择。研究者们发现,随着融合的源LLMs数量增加,FUSELLM的性能也随之提升。此外,最小编辑距离(MinED)方法在令牌对齐上优于精确匹配(EM)方法,而最小交叉熵(MinCE)作为融合函数在所有基准测试中均优于平均交叉熵(AvgCE)。

知识蒸馏是一种常见的技术,通过训练一个学生模型来模仿教师模型的行为。实验结果表明,尽管知识蒸馏能够提升模型性能,但FUSELLM通过结合三个7B模型的持续训练,相比于从单一13B模型中提取知识的蒸馏方法,取得了更显著的性能提升。
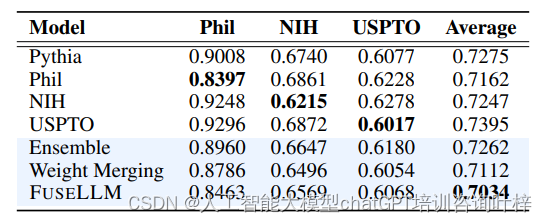
最后,研究者们还将FUSELLM与其他模型融合技术,如模型集成和权重合并,进行了比较。在模拟了多个具有相同基础模型结构但训练数据不同的LLMs的场景中,FUSELLM在所有测试域中都实现了最低的平均困惑度(perplexity),这表明其在整合多样化模型知识方面的有效性超过了传统的集成和合并方法。
FUSELLM方法成功地展示了如何通过知识融合提升LLMs的性能。该方法不仅减少了初始训练的成本,还允许目标模型继承并超越所有源模型的能力。这一发现为未来LLMs的研究和应用提供了新的方向。
论文地址:https://arxiv.org/pdf/2401.10491.pdf
git: https://github.com/fanqiwan/FuseLLM