没有网站可以做seo吗深圳搜索引擎
本文介绍本地大模型推理数据集构成
(一)古籍数据获取
以44种竖向从右至左排列的繁体古文为研究对象,通过OCR识别、XML结构化处理,最终生成符合大模型训练要求的数据集。
1.技术路线设计
- 图像处理层:PaddleOCR识别竖排文本
- 结构转换层:生成标准XML文件
- 数据整合层:XML转Excel统一存储
2.关键技术实现
2.1OCR识别与XML生成(Python实现)
核心代码解析
def generate_xml(image_path, xml_path):# OCR识别(支持中文竖排识别)result = ocr.ocr(str(image_path), cls=True)# 从右至左排序逻辑boxes_texts.sort(key=lambda b: -b[0])# XML结构生成root = ET.Element('page', {'id': xml_id,'size': f'{width},{height}','md5': md5sum})# 文本块标注for idx, (x, y, h, text) in enumerate(boxes_texts, start=1):style = f'{x},{y},0,{h};f:0,{h-4}'ET.SubElement(root, 'text', {'id': str(idx+2), 'style': style}).text = text
关键技术点
-
竖排识别优化:
- 使用PaddleOCR的
use_angle_cls=True参数启用方向分类 lang='ch'参数优化中文识别效果
- 使用PaddleOCR的
-
从右至左排序:
boxes_texts.sort(key=lambda b: -b[0]) # 按x坐标降序排列 -
元数据保留:
- 图像MD5校验码
- 图像尺寸与格式
- 创建时间戳
2.2XML转Excel(Java实现)
核心处理逻辑
public class XmlToExcelConverter {// 多文件夹批处理File[] directories = rootDir.listFiles(File::isDirectory);// 创建Excel工作簿Workbook workbook = new XSSFWorkbook();// XML内容提取StringBuilder content = new StringBuilder();List<Node> textNodes = document.selectNodes("//text");
}
关键特性
-
批量处理架构:
- 支持多层级目录遍历
- 自动识别index.xml元数据文件
-
数据标准化:
// Excel列设计 headerRow.createCell(0).setCellValue("book_id"); headerRow.createCell(1).setCellValue("book_name"); headerRow.createCell(3).setCellValue("content"); -
内容聚合策略:
- 多XML文件合并为单个Excel
- 章节自动编号
- 文本块换行符分隔
3.成果展示

<page id="0891001001.xml" relate="0891001001.jpg" size="5696,4439">
<font id="0">zykkai</font>
<rect id="1" box="105,183,5490,4086" foreground="255,255,255"/>
<rect id="2" box="125,203,5450,4046" foreground="255,255,255"/>
<text id="3" style="4755,291,0,1304;f:0,730">周易內</text>
<text id="4" style="3938,288,0,1309;f:0,737">傳六卷</text>
<text id="5" style="3393,1373,0,345;f:0,322">後學吴讓之署</text>
<text id="6" style="1544,1046,0,374;f:0,358">同治四年湘鄉曽</text>
<text id="7" style="1034,1051,0,374;f:0,370">氏栞于金陵節署</text>
</page>

(二)古籍问答对数据生成
0.从文档中获取古籍内容
1.调用DeepSeek模型生成问题
response = client.chat.completions.create(model="deepseek-reasoner",messages=[{"role": "system", "content": "你是一名研究周易的专家"},{"role": "user", "content": f"这是一本古籍中的一段,\n{chunk}\n\n请根据文章内容提出2个问题"}],stream=False
)-
使用
deepseek-reasoner专家模型模拟《周易》研究者,生成语义相关问题。 -
要求:禁止使用“文中”、“文章”字眼,确保通用性。
2.去重判断 + 问题提取
def extract_questions(text):return re.findall(r"\d+\.\s*(.+)", text)-
提取格式如“1. 问题内容”的结构化问题,防止误提。
-
利用
guji_answer_question.txt做去重判断,确保每个问题只问一次。
3.自动回答生成并保存
response2 = client.chat.completions.create(model="deepseek-reasoner",messages=[{"role": "system", "content": "你是一名研究周易的专家"},{"role": "user", "content": f"{chunk}\n请回答问题:{final_question}"}],stream=False
)-
模拟专家作答,并保存:
-
guji_answer.txt:包含问题、推理、最终回答 -
guji_answer_question.txt:仅保存问题列表
-
4. 输出样例

共处理349本易学古籍,共得到16068条问答数据。
(三)《周易研究》数据与易学知识图谱和百科全书获取
类似于易学古籍数据获取
共处理349本易学古籍,共得到16068条问答数据。
对百科全书中概论、词汇、易学史、人物、著作等部分进行了处理,共得到3643条问答数据。
(四)DeepSeek通过Self-Instruct自行生成
1. 初始化 DeepSeek 客户端
from openai import OpenAI
client = OpenAI(api_key="...", base_url="https://api.deepseek.com")2. Prompt 模板设计
每条 prompt 都在模拟不同的教学/应用场景,覆盖从“入门科普”到“哲学讨论”再到“实际应用”三个层面。

覆盖广泛:基础 → 哲学 → 应用;
风格丰富:模拟学生提问、专家回答;
易于扩展:可增加更多领域 prompt。
3. 防止重复生成:问题去重机制
# 提取编号的问题(1. xxx)用于去重等处理
def extract_questions(text):pattern = re.compile(r"\d+\.\s*(.+)")return pattern.findall(text)# 读取已有问题列表,避免重复
existing_questions_file = Path("self_instruct_questions.txt")
if existing_questions_file.exists():with open(existing_questions_file, "r", encoding="utf-8") as f:asked_questions = set(line.strip() for line in f if line.strip())
else:asked_questions = set()通过正则提取“1. xxx”结构的问题文本,并用 set 去重保存。这样可防止多个 Prompt 生成重复问题,提高数据独特性。
4. 核心主循环:生成并保存数据
这里使用 DeepSeek 的 deepseek-reasoner 模型,适合处理复杂推理与专业领域任务,并用 system prompt 设置角色背景(国学专家),提升回答可信度和风格一致性。
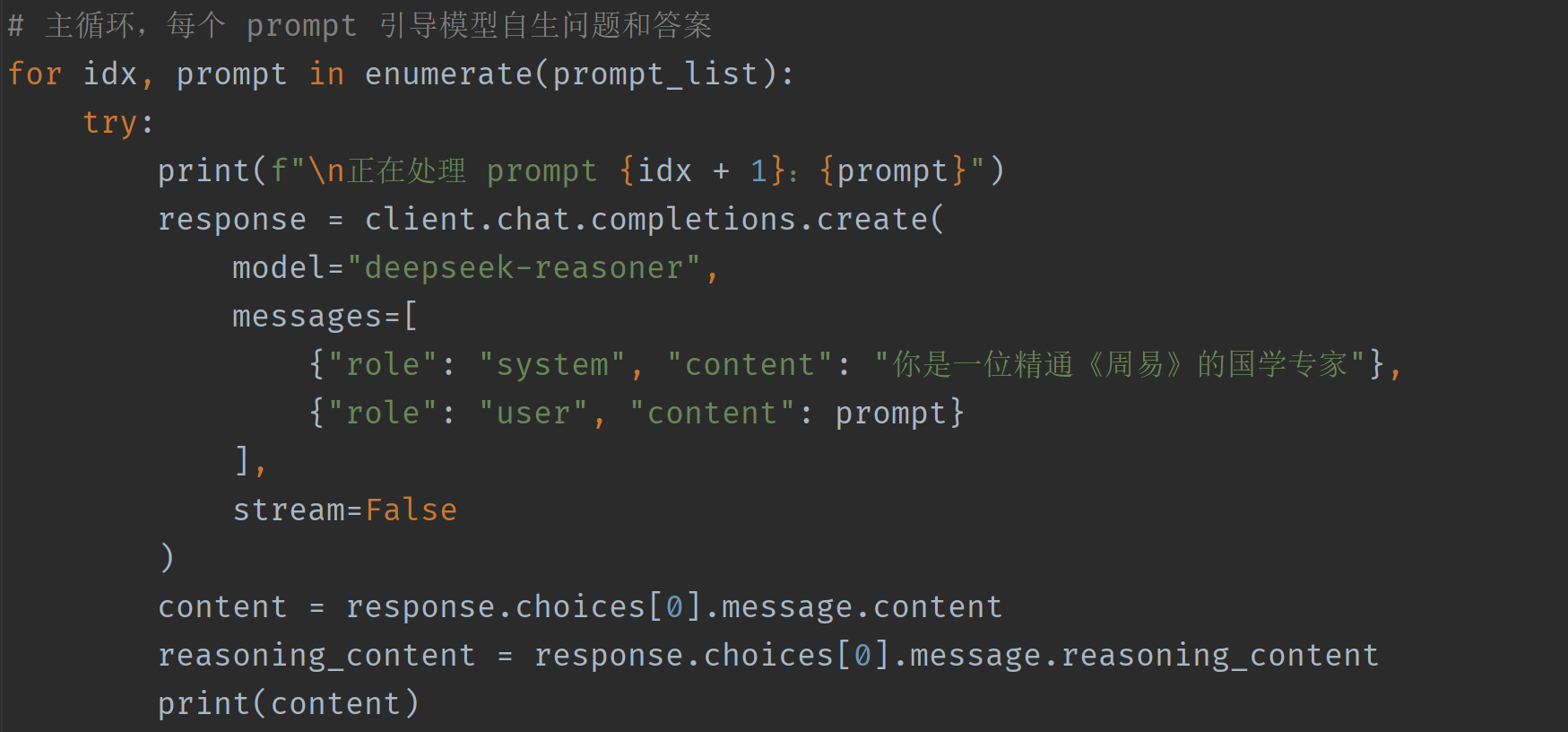
5. 数据保存结构
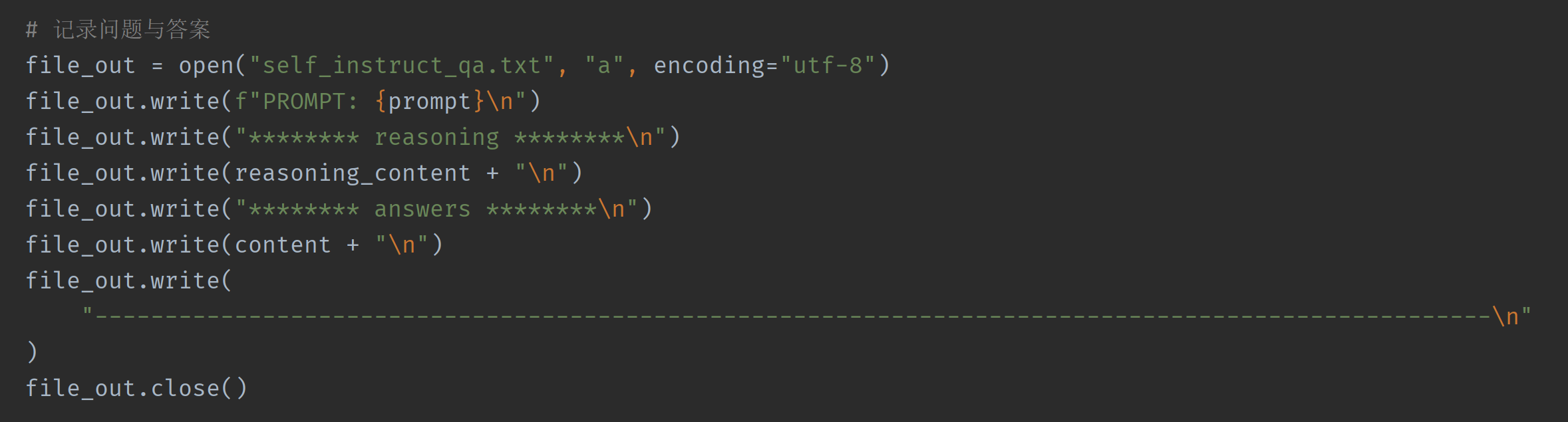
保存问答数据为结构清晰的文本格式:
-
reasoning_content: 模型的推理过程; -
answers: 结构化问答列表; -
可用于微调前进一步清洗或分句。
6.格式转换

共得到周易基础概念性、开放性等问答数据共4475条。