南山做网站公司在哪里软文营销ppt
数据集
通过网盘分享的文件:
链接: https://pan.baidu.com/s/17TLeF8PW2GSWTbAIJC69-A?pwd=4dak 提取码: 4dak
准备工作
# 导入必要的库
import numpy as np # 用于数值计算(如矩阵运算、数学函数等)
import pandas as pd # 用于数据处理和分析(如读取CSV、数据清洗等) # 使用 os.walk() 遍历 '/kaggle/input/' 目录及其子目录
# 该目录通常存放 Kaggle 比赛或项目的数据集
for dirname, _, filenames in os.walk('/kaggle/input'): # 遍历当前目录下的所有文件名 for filename in filenames: # 打印文件的完整路径(目录名 + 文件名) print(os.path.join(dirname, filename)) # 这段代码的作用:
# 1. 检查 '/kaggle/input/' 目录下有哪些数据文件
# 2. 帮助用户确认数据是否已正确加载
# 3. 方便后续代码读取数据文件(如 pd.read_csv()) 导入训练集数据,查看部分数据
# 导入数据
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
# 看开头部分数据
train_data.head()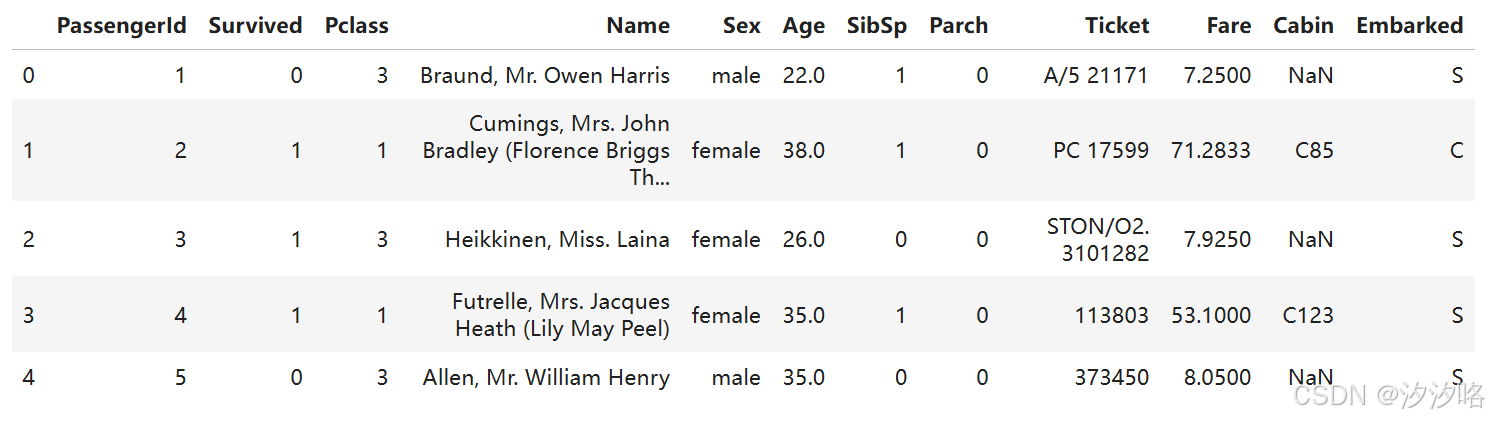
导入测试集数据,查看部分数据
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()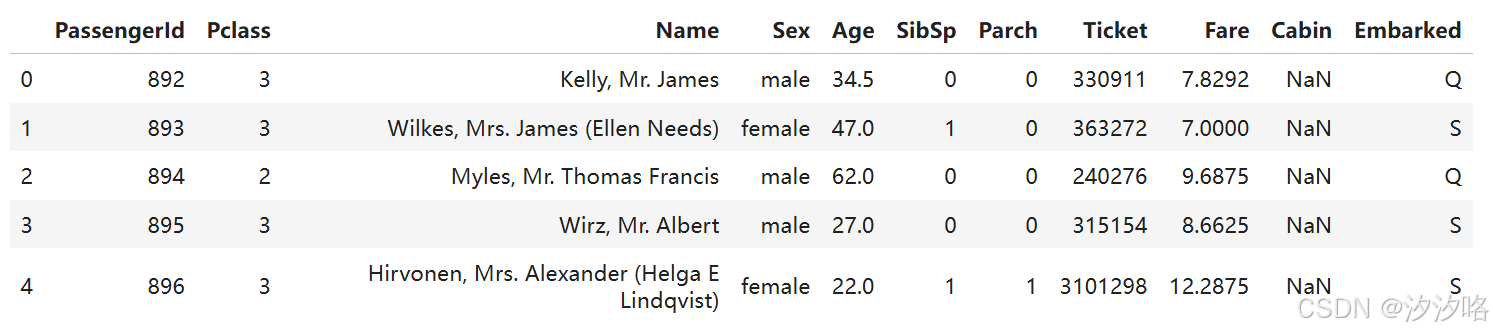
探索数据
看女性存活率
# 从训练数据中筛选性别为女性的乘客,并提取其生存状态(Survived列)
women = train_data.loc[train_data.Sex == 'female']["Survived"]# 计算女性乘客的生存率(生存人数 / 总女性人数)
rate_women = sum(women) / len(women)# 打印女性生存率(格式化为百分比形式)
print("% of women who survived:", rate_women)看男性存活率
men = train_data.loc[train_data.Sex == 'male']["Survived"]
rate_men = sum(men)/len(men)print("% of men who survived:", rate_men)训练与预测
# 导入随机森林分类器(scikit-learn 库)
from sklearn.ensemble import RandomForestClassifier# 定义目标变量 y(即训练数据中的生存状态:0=死亡,1=存活)
y = train_data["Survived"]# 选择特征列:舱位等级、性别、兄弟姐妹/配偶数量、父母/子女数量
features = ["Pclass", "Sex", "SibSp", "Parch"]# 对训练数据和测试数据进行独热编码(One-Hot Encoding),将分类变量(如Sex)转换为数值
X = pd.get_dummies(train_data[features]) # 训练集特征
X_test = pd.get_dummies(test_data[features]) # 测试集特征# 初始化随机森林模型,参数:
# n_estimators=100(100棵树), max_depth=5(树的最大深度), random_state=1(固定随机种子)
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)# 训练模型:输入特征 X 和目标变量 y
model.fit(X, y)# 对测试集进行预测,生成生存预测结果(0或1)
predictions = model.predict(X_test)# 将预测结果保存为DataFrame,包含两列:乘客ID和预测的生存状态
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})# 输出到CSV文件(用于Kaggle提交),不保存行索引(index=False)
output.to_csv('submission.csv', index=False)# 打印成功信息
print("Your submission was successfully saved!")