贵港市住房和城乡规划建设委员会网站中国500强最新排名
文章目录
- 0. 数据代码下载
- 1. 项目介绍
- 2. 数据处理
- 1. 导入数据
- 2. 处理数据
- 3. 建立模型
- 4. 考察单个特征
0. 数据代码下载
关注公众号:『AI学习星球』
回复:糖尿病预测 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiubiu滴滴我

1. 项目介绍
本次实验的主要内容是使用回归分析和聚类分析来预测某人患糖尿病的可能性和身体的糖尿病指数。
本次数据分析实战,对糖尿病数据集进行回归分析。
sklearn.datasets 包提供了一些小的数据集,可用于机器学习入门,见下图。
| 导入toy数据的方法 | 介绍 | 任务 | 数据规模 |
|---|---|---|---|
| load_boston() | 加载和返回一个boston房屋价格的数据集 | 回归 | 506*13 |
| load_iris([return_X_y]) | 加载和返回一个鸢尾花数据集 | 分类 | 150*4 |
| load_diabetes() | 加载和返回一个糖尿病数据集 | 回归 | 442*10 |
| load_digits([n_class]) | 加载和返回一个手写字数据集 | 分类 | 1797*64 |
| load_linnerud() | 加载和返回一个健身数据集 | 多分类 | 20 |
2. 数据处理
1. 导入数据
导入数据分析常用包
# 导数据分析常用包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
导包获取糖尿病数据集
from sklearn.datasets import load_diabetes
data_diabetes = load_diabetes()
print(data_diabetes)
我们先看一下数据是什么样:
diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况。
从结果可以看到,这个数据集是个字典形式,三个key值,分别是['data' , 'feature_names' , 'target']
为了方便后续处理数据,现在将这个字典形式的数据集进行拆分。
data = data_diabetes['data']
target = data_diabetes['target']
feature_names = data_diabetes['feature_names']
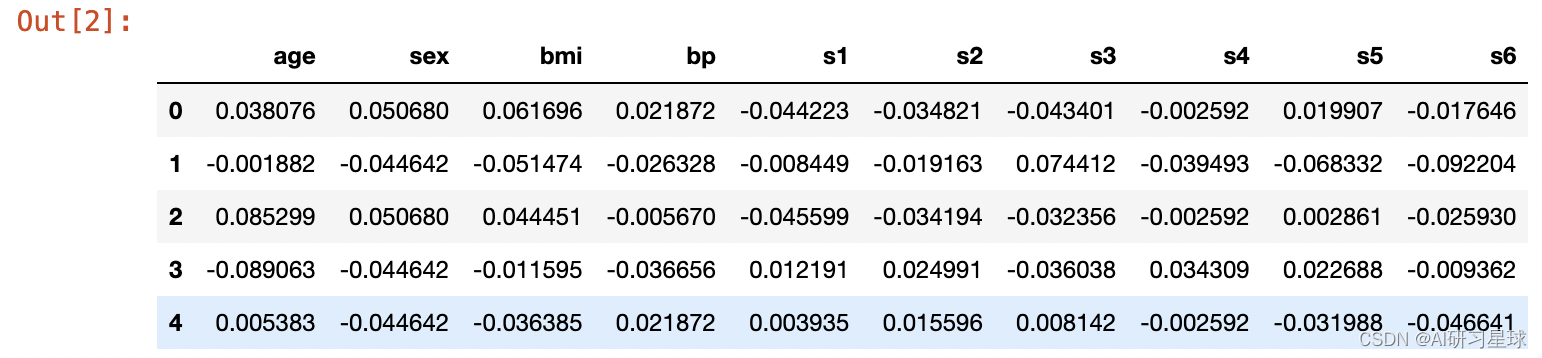
现在三个数据都是numpy的一维数据形式,将她们组合成dataframe,可以更直观地观察数据
df = pd.DataFrame(data,columns = feature_names)
df.head() # 查看前几行数据
2. 处理数据
查看数据集的基本信息
df.info()

数据集共442条信息,特征值总共10项, 如下:
age:年龄sex:性别bmi= body mass index:身体质量指数,是衡量是否肥胖和标准体重的重要指标,理想BMI(18.5~23.9) = 体重(单位Kg) ÷ 身高的平方 (单位m)bp= blood pressure :血压s1,s2,s3,s4,s4,s6(六种血清的化验数据)
3. 建立模型
- 抽取训练集合测试集
from sklearn.model_selection import train_test_split
train_X,test_X,train_Y,test_Y = train_test_split(data,target,train_size =0.8)
- 建立模型
from sklearn.linear_model import LinearRegression
model = LinearRegression()
- 训练数据
model.fit(train_X,train_Y)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
- 评估模型
model.score(train_X,train_Y)
输出结果 : 0.51298922173144801
- 模型评估结果只有0.5左右,不是很高,说明变量之间的因果关系不是很强。
- 一般这种情况下,我们会考察 单个特征值 与 结果标签 之间的相关关系。
4. 考察单个特征
考察单个特征值与结果之间的关系,以图表形式展示
- 取出特征值
df.columns
Index([‘age’, ‘sex’, ‘bmi’, ‘bp’, ‘s1’, ‘s2’, ‘s3’, ‘s4’, ‘s5’, ‘s6’], dtype=‘object’)
- 循环对每个特征值进行建模训练,作图
# 建立画板,作图5行2列的图
plt.figure(figsize=(2*6,5*5))
for i,col in enumerate(df.columns): #enumerate 枚举train_X = df.loc[:,col].values.reshape(-1,1)
# 每一次循环,都取出datafram中的一列数据,是一维Series数据格式,但是线性回归模型要求传入的是一个二维数据,因此利用reshape修改其形状train_Y = targetlinear_model = LinearRegression() # 构建模型linear_model.fit(train_X,train_Y) #训练模型score = linear_model.score(train_X,train_Y) # 评估模型
# 以训练数据为X轴,标记为Y 轴,画出散点图,直观地看每个特征和标记直接的关系axes = plt.subplot(5,2,i+1)plt.scatter(train_X,train_Y)
# 画出每一个特征训练模型得到的拟合直线 y= kx + bk = linear_model.coef_ # 回归系数b = linear_model.intercept_ # 截距x = np.linspace(train_X.min(),train_X.max(),100)y = k * x + b
# 作图plt.plot(x,y,c='red')axes.set_title(col + ':' + str(score))
plt.show()
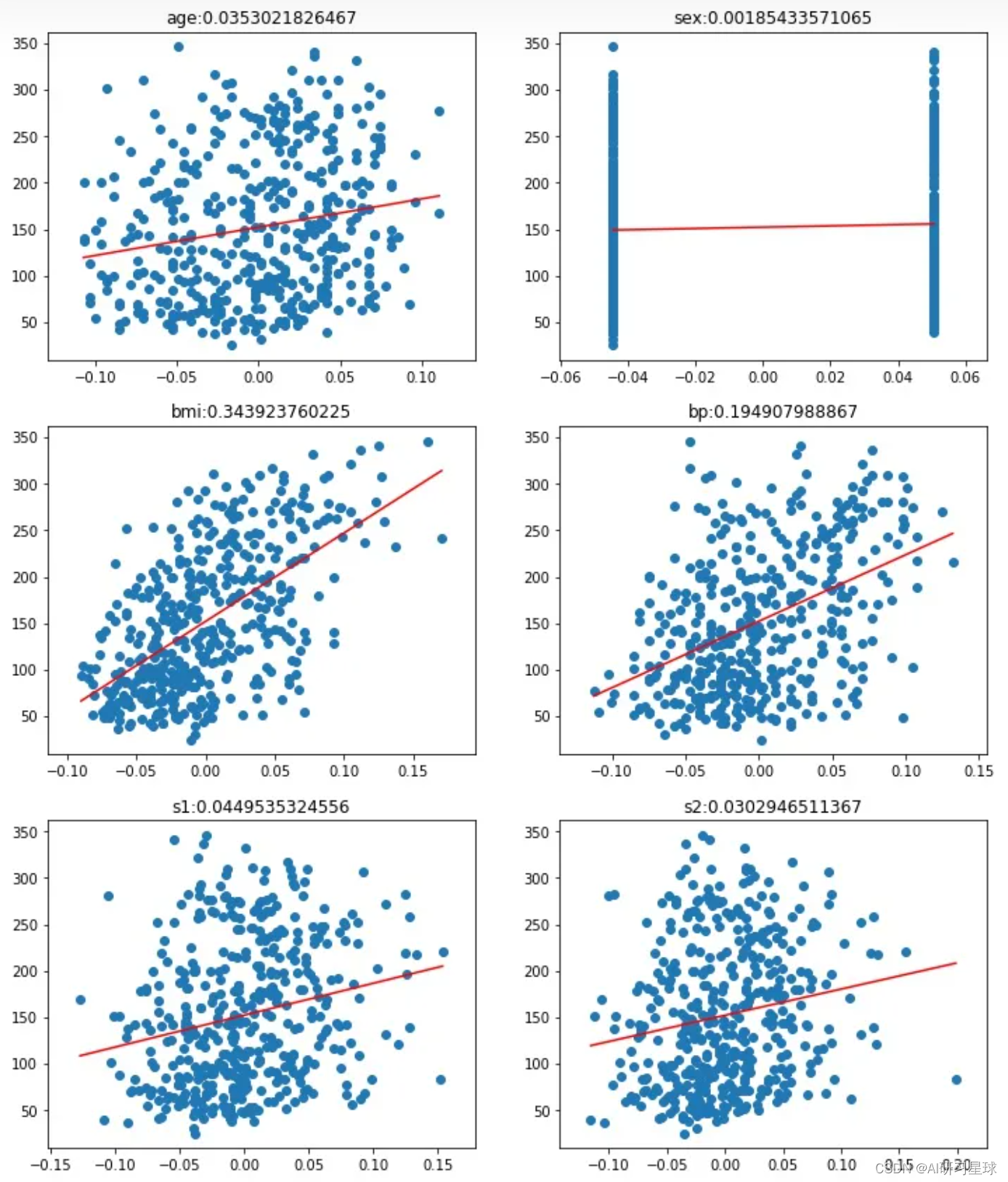
总结
从以上分析可知,单独看所有特征的训练结果,并不没有得到有效信息,我们拆分各个特征与指标的关系,可以看出:
- bmi与糖尿病的相关性非常高,bp也有一定的关系,但是是否是直接关系,还是间接关系,有待深入考察。
- 其他血清指标多少都和糖尿病有些关系,有的相关性强,有的相关性弱。
关注公众号:『AI学习星球』
回复:糖尿病预测 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiubiu滴滴我