wordpress网站没有阅读量网络营销乐云seo
ARIMA
ARIMA模型的核心就藏在其名字里,AR(自回归)代表了要预测的数据可能跟历史数据有关系,I(差分)代表了历史数据点之间的差异,MA(移动平均)代表了在预测历史数据点产生的误差可以在预测未来数据时修正,这三个点加起来共同用历史数据来预测未来值。
举个浅显的例子就是,假设要预测明天会不会下雨,首先我们查看过去的数据带你,如果过去连续三天都下雨,那么明天下雨的概率就会很高,对应着AR,即用过去的数据推测未来;假如过去几天之间的温度都在一个比较小的区间内,那么直接用过去几天的气温辅助预测不太会有效果,就要转而用天与天之间的温差来判断明天的气温,对应的是I;如果在前天预测了昨天是晴天,但昨天下雨了,那么在考虑明天的天气时就需要调整一下,把对下雨概率的考量提高一些,对应的是MA。
下面是一个例子:
# 生成具有趋势和季节性的非平稳序列
set.seed(123)
y <- cumsum(rnorm(200)) + 10*sin(2*pi*(1:200)/12) # 趋势+季节项# 统计检验平稳性(ADF检验)
library(tseries)
adf.test(y) # p>0.05说明非平稳# 差分后检验
adf.test(diff(y)) # p<0.05,差分后平稳# 自动选择ARIMA模型(包含统计准则)
library(forecast)
fit <- auto.arima(y, seasonal=TRUE, stepwise=FALSE)
summary(fit) # 查看AIC/BIC和残差检验结果# 残差诊断(Ljung-Box检验)
checkresiduals(fit) # 若p>0.05则通过检验输出:
Augmented Dickey-Fuller Testdata: diff(y)
Dickey-Fuller = -15.736, Lag order = 5, p-value = 0.01
alternative hypothesis: stationary
Series: y
ARIMA(5,0,0) with non-zero mean Coefficients:ar1 ar2 ar3 ar4 ar5 mean1.4718 -0.3562 -0.1105 -0.6130 0.4702 1.6293
s.e. 0.0619 0.1137 0.1167 0.1137 0.0625 0.5961sigma^2 = 1.418: log likelihood = -319.08
AIC=652.15 AICc=652.73 BIC=675.24Training set error measures:ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.01002482 1.172706 0.8724252 -13.61711 39.98203 0.2678866 -0.12844Ljung-Box testdata: Residuals from ARIMA(5,0,0) with non-zero mean
Q* = 31.243, df = 5, p-value = 8.389e-06Model df: 5. Total lags used: 10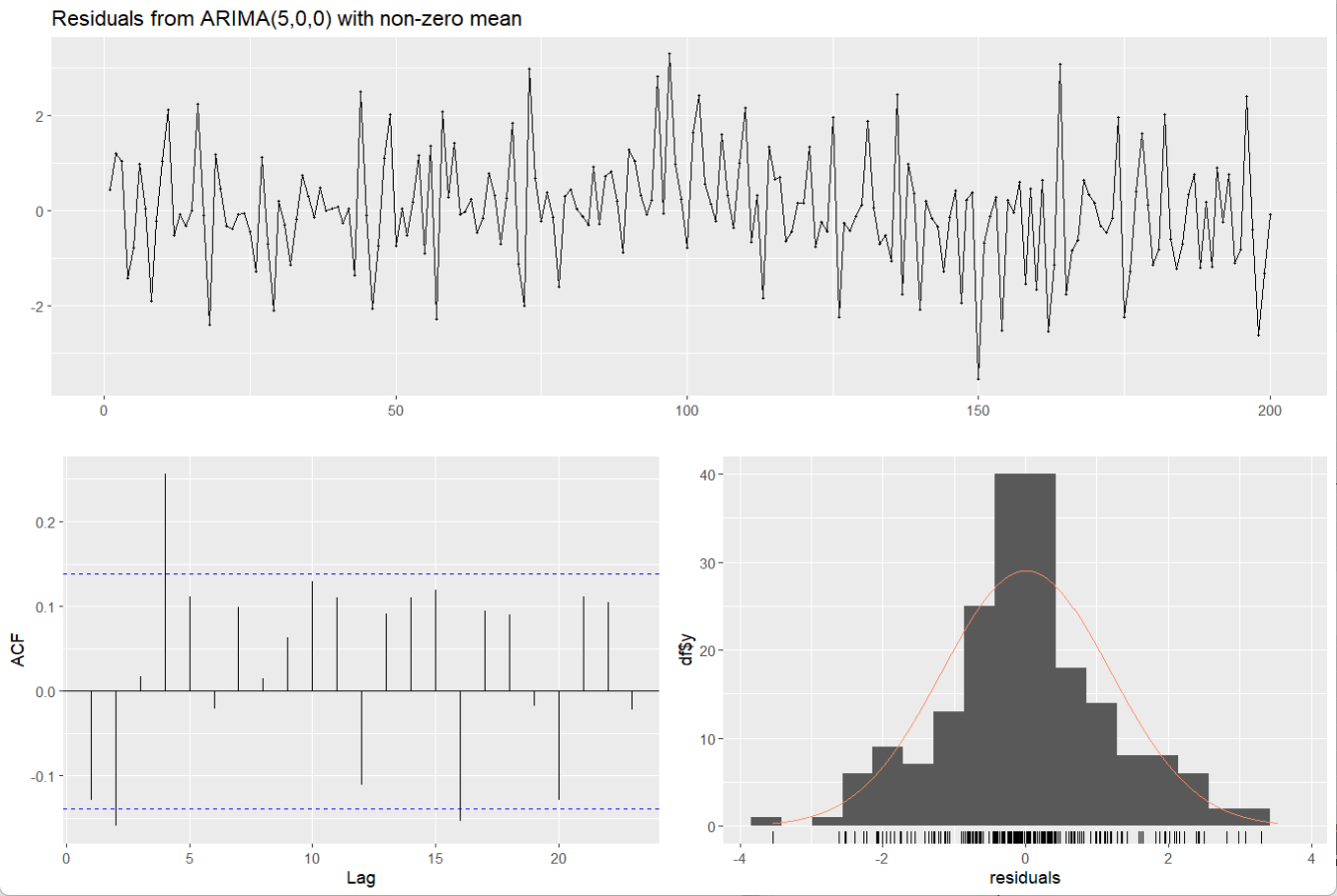
从结果可以看到,Dickey-Fuller = -15.736,说明数据是平稳的,p小于0.01,也说明这个结果是可靠的;进一步看残差检验,存在有黑线超出了蓝色虚线以外,可能是没考虑到有季节性的特征,p远小于0.05也说明还存在自相关变量,未能完全捕捉全部的数据。
格兰杰因果检验
同样是看历史数据,这个方法研究的是两个变量,需要弄清楚另一个变量的过去值是否有助于预测这个变量。检验的方法类似于同对照试验的方法,先是只看变量Y一个的历史数据,先尝试用他自己的过去值来预测,再将带有变量X的数据的过去值拿来预测,看结果是否会更好。用简单的话来说就是,假设要研究小明生病的原因是不是不吃蔬菜,那么就先只看小明不生病的记录,尝试用过去生病的数据来预测未来是否会生病,再用小明不吃蔬菜期间的生病记录来预测,看看结果会不会更准,以此来辅助判断。注意,这样得出来的只是统计意义上的因果,并不能直接代表客观的意义。
以下是一个例子:
library(vars)
# 生成模拟数据(含共同潜在因素z)
set.seed(123)
n <- 200
z <- rnorm(n) # 潜在因素(如宏观经济)
x <- 0.5*lag(z,-1) + rnorm(n, sd=0.2)
y <- 0.3*lag(z,-1) + rnorm(n, sd=0.3)
data <- na.omit(data.frame(x, y, z)) # 注意列名已明确命名为x/y/z# 转换为矩阵格式并指定列名
var_data <- cbind(data$x, data$y, data$z)
colnames(var_data) <- c("x", "y", "z") # 关键步骤:显式命名列# 选择最优滞后阶数(AIC准则)lag_selection <- VARselect(var_data, lag.max=5)
best_lag <- lag_selection$selection["AIC(n)"] # 选择AIC最小的阶数# 构建VAR模型
var_model <- VAR(var_data, p=best_lag)# 格兰杰因果检验(注意使用正确的列名)
# 检验x是否引起y
causality(var_model, cause="x")$Granger
# 检验y是否引起x
causality(var_model, cause="y")$Granger输出:
Granger causality H0: x do not Granger-cause y zdata: VAR object var_model
F-Test = 0.26816, df1 = 2, df2 = 585, p-value = 0.7649Granger causality H0: y do not Granger-cause x zdata: VAR object var_model
F-Test = 0.49958, df1 = 2, df2 = 585, p-value = 0.607首先判断x的历史数据是否能更好地帮助y去预测,可以看到p值为0.7649 > 0.05,无法拒绝原假设,即x的变化对y的预测没有作用;同样的,可以看到关于y能否帮助x更好地去预测,p值为0.607 > 0.05,这说明x和y是相互独立的两个变量(在统计意义上),注意,即使我们用格兰杰因果得出这样的结果,我们也不能直接下这种判断,还需要考虑是否是因为影响了什么中间变量导致了变化。