网站设计应该遵循的原则西安百度推广网站建设
1.每日复盘与今日内容
1.1复盘
- 磁盘分区方案(自己创建自定义虚拟机 跑下流程.)
- swap增加,关闭.
- 故障案例:进入救援模式.
- 故障案例:优盘救援模式.
- 故障案例:磁盘空间不足系列(复现,排查,解决)
经典
inode不足
未彻底删除不足
1.2今日内容
- 几个特殊符号
- 引号系列
- 重定向符号系列
- 正则(grep/egrep)
- awk -F
2.特殊符号
2.1引号系列
面试题:单引号,双引号,不加引号,反引号
引号 | 说明 |
|---|---|
反引号 | 优先执行,加上命令 ` ` $()2种写法 |
单引号 | ' ' 所见即所得的,单引号里面的内容不会被处理,直接进行输出,命令解释器没有解析 |
双引号 | “ ” 类似于单引号,但一些特殊符号会被解析运行 , $ $() ... |
不加引号 | 不加引号类似于双引号,额外支持{} *通配符 |
- 通配符--文件名替换,它主要是作用于匹配文件名,常用命令是ls、find、cp、mv;
echo $(pwd) `pwd` pwd
/root /root pwd2.2 重定向符号
- > >>
重定向符号 | 说明 | 使用 |
|---|---|---|
>或1> | 重定向符号,标准输出重定向,先清空然后写入 | 创建文件并写入内容 |
>>或1>> | 追加重定向,标准输出追加重定向,追加到末尾 | 修改配置 |
2> | 标准错误输出重定向,先清空然后写入错误 | 较少单独使用 |
2>> | 标准错误输出追加重定向,写入末尾 | 较少单独使用 |
>>oldboy.log 2>&1 &>>oldboy.log | 错误和正确信息都写入到同一个文件中 | 经常使用(运行脚本,定时任务) |
< 或0< | 与特定命令使用,读取文件内容tr,xargs | 其他命令几乎不会用 |
<<或0<< | cat命令向文件中批量写入多行内容 | 常用 |
- cat
#先在某几个地方写好,然后整个复制到linux系统
#相当于vimcat >>oldboy.txt <<EOF- tr字母/字符级别的替换(大写-->小写)
tr 'a-z' 'A-Z' < passwd #输出- xargs参数转换,控制参数个数(列)
xargs -n3 <num.txt3.正则表达式
3.1 简介
- linux一般是四剑客使用,开发语言也支持
- 对字符进行过滤,精确一些
3.2 注意事项
- 符号英文符号
- 配置grep,egrep --color颜色别名
3.3 正则符合
正则符号 | 符号 | 命令 |
|---|---|---|
基础正则 | ^ $ ^ $ . * .* [] [^] | grep/sed/awk |
扩展正则 | | + {} () ? | egrep/sed -r/awk |
3.4 基础正则
测试文件
cat >/oldboy/re.txt<<EOF
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and
chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
EOF1.^以xxxx开头的行
^Igrep '^I' re.txt2.$以xxxx结尾的行
!$grep '!$' re.txt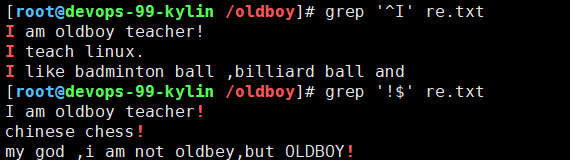
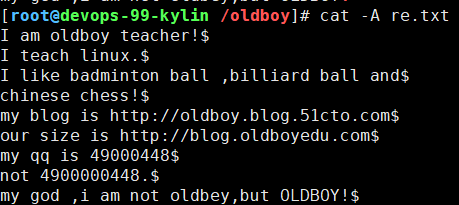
- cat -A查看隐藏符号
有些时候明明看到每行最后一个字母,抓取时却又抓不到,说明结尾还有其他符号(空格),故需要使用cat -A查看
3.^$空行
- 一般排除空行或者包含井号的行.(井号开头的行)
grep -v '^$' re.txt- 排除/etc/ssh/sshd_config空行或包含井号的行.
egrep -v '^$|#' /etc/ssh/sshd_config 4.任意一个字符
过滤内容,不匹配空行
刚开始学习正则,了解作用即可
后面常用的是.与*搭配5.*--前一个字符出现0次或0次以上
出现/重复/连续出现
0
000000000000000000
aaaaaaaaaaaaa
bbbbbbbbbbbbbb
cccccccccccccccccccc
lidao
996- .*最常用的,表示:所有
#找到含有开头到oldboy中间任意的行
grep '^.*oldboy' re.txt
#找出文本中任意开头含有o的行
grep '^.*o' re.txt
#正则表达式匹配所有或连续出现的时候:贪婪性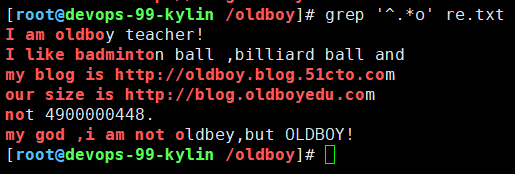
#找出以I开头以$结尾的行
grep '^I.*!$' re.txt![]()
6.[]--[abc]1个整体包含3个情况,匹配
- 基本用法与格式
#过滤a或b或c
grep '[abc]' re.txt#显示详细信息
grep -o '[abc]' re.txt#过滤小写字母
grep '[a-z]' re.txt#过滤大写字母
grep '[A-Z]' re.txt#过滤数字
grep '[0-9]' re.txt#过滤大小写字母
grep '[a-zA-Z]' re.txt
#精简写法,不通用
grep '[a-Z]' re.txt#过滤大小写字母和数字
grep '[a-zA-Z0-9]' re.txt
#精简写法,不通用
grep '[0-Z]' re.txt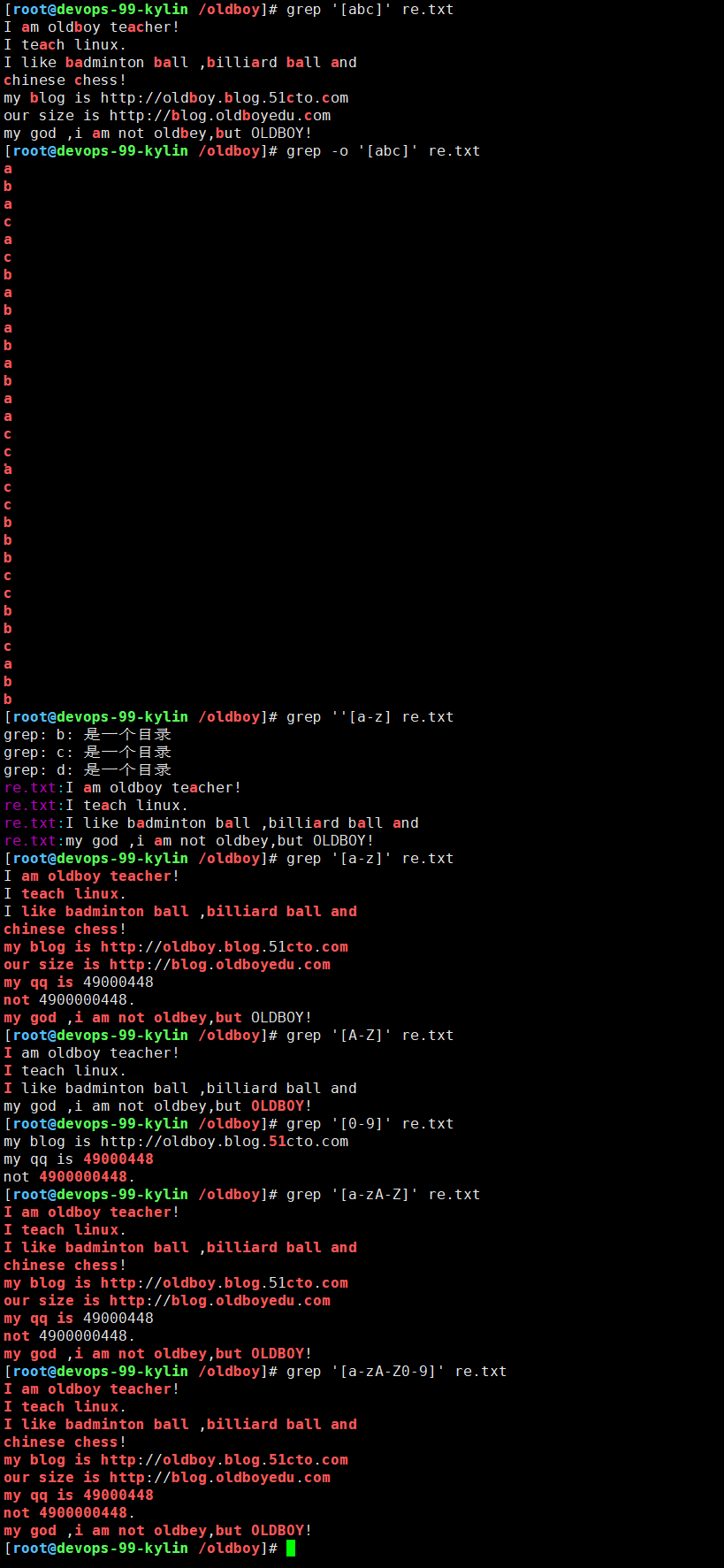
- 过滤出文件中以I或m或n开头的行
grep '^[Imn]' re.txt- 过滤出文件中以I或m或n开头的然后结尾是!或数字
grep '^[Imn].*[0-9!]$' re.txt7.[^]--[^abc]1个整体不包含a或b或c
#找出除abc以外的内容
grep '[^abc]' re.txt#找出除小写26个字母以外的内容
grep '[^a-z]' re.txt8.过滤出以.结尾的行
grep '\.$' re.txt
#\--转义字符,作用是让.失效基础正则 | 符号 |
|---|---|
常用的基础正则 | ^ $ ^$ .* [] |
其他 | . * [^] |
3.5扩展正则
1.| 或者
#查看含有sshd以及rsyslog的内容
ps —ef | egrep 'sshd|rsyslog'
ps -ef |grep -E 'sshd|rsyslog'
ps -ef | grep 'sshd\|rsyslog'2.+ 前一个字符出现1次或1次以上
- 出现/重复/连续出现
- 经常与[]搭配实现
#取出文章中的单词
egrep '[a-z]+' re.txt
egrep -o '[a-z]+' re.txt- 取出re.txt文件中连续出现的单词统计次数,取出前5
egrep -o '[a-z]+' re.txt | sort |uniq -c |sort -rnk1 |head -5- 取出re.txt文件中出现的小写字母统计次数,取出前5
egrep -o '[a-z]' re.txt | sort | uniq -c | sort -rnk1 | head -53.{} o{n,m}前一个字符o,出现至少n次,最多出现m次.
- 表示范围的匹配怕,出现1位数字到3位数字
- 身份证号18位数字
egrep '[0-9]{1,3}' re.txt
egrep '[0-9]{3}' re.txt书写1个简易的正则匹配ip地址:10.0.0.200 4个数字中间3个点.每个数字范围是1-255.
ip a | awk 'NR==3'| egrep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'![]()
4.()1个整体(sed命令中表示反向引用)
export LANG=en_US.UTF-8
lscpu |egrep -i 'L1d cache|L1i cache|L2 cache|L3 cache'lscpu |egrep -i 'L1d|1i|2|3 cache' #这样写有问题 多过滤了很多内容.
lscpu |egrep -i 'L(1d|1i|2|3) cache' #需要使用()括起来就行了.#更加精简的写法慢慢理解.
lscpu |egrep -i 'L(1[di]|2|3) cache'
lscpu |egrep -i 'L(1[di]|[23]) cache'5.?前一个字符出现0次或1次
测试文件
cat >test.txt<<EOF
good
goooood
gd
god
gooood
EOF
#查看文本中gd或god
egrep 'gd|god' test.txt#同上的不同写法
egrep 'go?d' test.txt#查看文本中g与d中间多个o
egrep 'go+d' test.txt#查看文本中g与d中间任意个o
egrep 'go*d' test.txt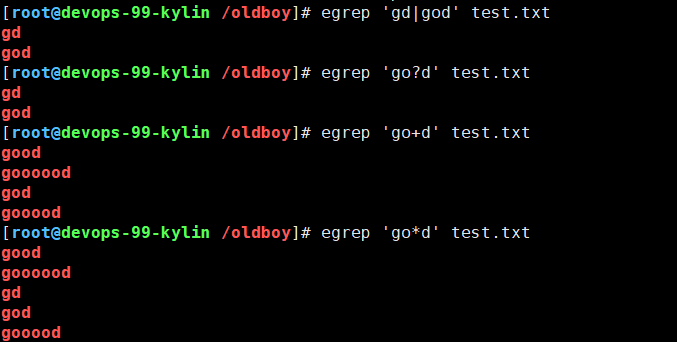
6.扩展正则小结
- 核心:| +
- {} ()
- ?
4.awk
- awk取列,取行.
- 取列(正着取,倒着取,结合正则取)
- 取行
4.1 awk取列与正则
awk -F 选项的作用是修改/指定awk的分隔符🍟🍟🍟🍟🍟
- 取出/etc/passwd第1列,第2列,最后一列
awk -F':' '{print $1,$2,$NF}' /etc/passwd- 运行ip a命令取出网卡ip地址
#显示当前系统中所有的网络接口信息
ip a s ens33
#查看所有网络接口的IP地址信息
ip addr show ens33#接下来需要使用awk -F实现功能--指定遇到空格切割一下.遇到/斜线切割,正则匹配: 空格或者/
ip a s ens33 | awk 'NR==3'
ip a s ens33 | awk 'NR==3' |awk -F '[ /]+' '{print $3}'![]()
w命令结果中获取运行时间
cat >w.txt<<EOF
07:15:06 up 13:08, 1 user, load average: 0.00, 0.00, 0.00
USER TTY LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 04:44 2.00s 0.33s 0.00s w
EOF
wk -F 'up |, +[0-9]+ user' '{print $2}' w.txt4.2 awk取行
- awk 'NR==3' 指定行号
- awk 'NR>=3'
- awk 'NR>=3&&NR<=10'
- awk取行与正则搭配 类似于grep/egrep
#1.在/etc/passwd中过滤包含root的行或oldboy的行
egrep 'root|oldboy' /etc/passwd
awk '/root|oldboy/' /etc/passwd
awk '/^root/' /etc/passwd
awk '/bash$/' /etc/passwd5.今日工作总结
- 基础正则扩展正则:^ $ ^$ .* [] | +
- grep/egrep命令过滤
- awk取行取列