个人做网站有什么条件电工培训内容
目录
一、任务调度系统概述
(一)任务调度的目标
(二)任务调度框架的关键组成
二、任务状态设计
(一)任务状态流转设计
(二)任务表设计(SQL)
三、单机任务调度实现
(一)获取待处理任务
(二)执行任务
代码实现(单线程版本)
(三)多线程提高吞吐量
四、使用阻塞队列解耦生产者-消费者
五、分布式任务调度
(一)分片ID(取模分片)
(二)中心化调度(使用 Redis)
六、结论
干货分享,感谢您的阅读!
在实际业务中,任务调度系统负责从任务队列中获取任务并执行。为了满足高吞吐、高可用、轻量级及可扩展性等需求,任务调度系统的设计必须具备灵活性、可伸缩性和容错性。
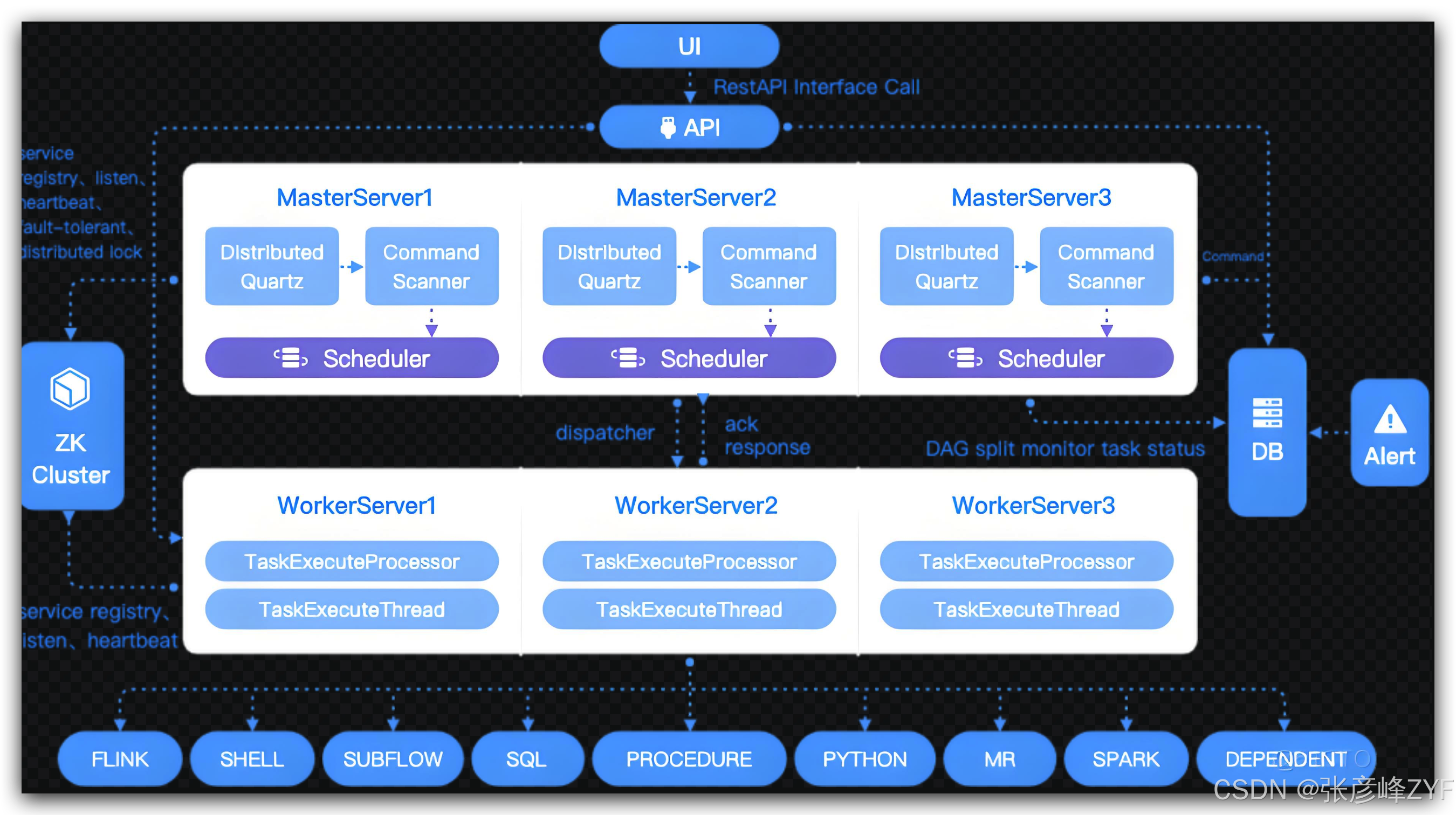
本文将展示如何使用 Java 实现一个简单且高效的任务调度框架,并深入探讨每个设计要点,包括任务状态管理、任务并发执行、分布式处理等内容。
一、任务调度系统概述
任务调度系统广泛应用于各种业务场景中,任务往往是异步执行的,需要管理任务的生命周期、处理任务的优先级、失败重试、任务超时等问题。
(一)任务调度的目标
-
高吞吐量:任务处理速度需要尽可能快。
-
高可用性:任务调度系统在遇到故障时能够恢复并继续处理任务。
-
低延迟:任务提交后能迅速被处理。
-
易于扩展:可以轻松应对任务量的增加,适应分布式环境。
(二)任务调度框架的关键组成
-
任务状态管理:追踪任务的执行状态。
-
任务执行策略:决定如何执行任务,包括单机和分布式执行策略。
-
任务失败与重试机制:处理任务失败后如何重试。
-
系统监控与报警:对任务执行情况进行实时监控,发现异常时报警。
二、任务状态设计
(一)任务状态流转设计
任务的状态管理是调度系统的核心。任务需要在生命周期内从一个状态流转到另一个状态。常见的任务状态有:
-
INIT:任务初始状态,表示任务已创建但尚未处理。
-
PROCESSING:任务正在处理中,标识任务已被调度但尚未完成。
-
SUCCESS:任务执行成功。
-
FAILED:任务执行失败。
-
RETRY:任务执行失败后需要重试。
任务状态流转的主要问题是如何避免任务的重复执行、如何保证任务在失败时的容错性和可靠性。
(二)任务表设计(SQL)
任务表记录了任务的当前状态及其他元数据,如任务类型、优先级、执行时间等。
CREATE TABLE task (task_id BIGINT AUTO_INCREMENT PRIMARY KEY,task_type VARCHAR(255) NOT NULL,status ENUM('INIT', 'PROCESSING', 'SUCCESS', 'FAILED', 'RETRY') DEFAULT 'INIT',priority INT DEFAULT 0,retry_count INT DEFAULT 0,create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,execute_time TIMESTAMP NULL
);
三、单机任务调度实现
(一)获取待处理任务
首先,我们需要从数据库中获取状态为 INIT 的任务,并按优先级和创建时间排序,优先处理高优先级和较早创建的任务。
SELECT * FROM task WHERE status = 'INIT'
ORDER BY priority DESC, create_time ASC LIMIT 10;
(二)执行任务
当获取到待处理任务时,系统将执行这些任务,并在任务执行结束后更新任务的状态。对于任务失败的情况,我们可以设置重试机制,最多重试一定次数。
代码实现(单线程版本)
public class TaskScheduler {private static final int SLEEP_INTERVAL = 5000; // 每5秒检查一次任务private TaskRepository taskRepository; // 任务存储库(假设是数据库)public TaskScheduler(TaskRepository taskRepository) {this.taskRepository = taskRepository;}public void start() {while (true) {Task task = getPendingTask();if (task != null) {try {executeTask(task);updateTaskStatus(task.getTaskId(), "SUCCESS");} catch (Exception e) {updateTaskStatus(task.getTaskId(), "FAILED");}} else {try {Thread.sleep(SLEEP_INTERVAL); // 无任务,休眠} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}}private Task getPendingTask() {return taskRepository.findFirstByStatusOrderByPriorityDescCreateTimeAsc("INIT");}private void executeTask(Task task) {// 任务执行逻辑,具体实现根据任务类型而定System.out.println("Executing task: " + task.getTaskId());}private void updateTaskStatus(Long taskId, String status) {taskRepository.updateStatus(taskId, status);}
}
(三)多线程提高吞吐量
在单线程模型下,任务处理速度较慢,我们可以通过使用线程池来提高并发性。线程池会创建一定数量的线程,并行执行多个任务,从而提升系统的吞吐量。
public class TaskScheduler {private static final int THREAD_POOL_SIZE = 10; // 线程池大小private static final int SLEEP_INTERVAL = 5000;private TaskRepository taskRepository;private ExecutorService executorService;public TaskScheduler(TaskRepository taskRepository) {this.taskRepository = taskRepository;this.executorService = Executors.newFixedThreadPool(THREAD_POOL_SIZE);}public void start() {while (true) {Task task = getPendingTask();if (task != null) {executorService.submit(() -> {try {executeTask(task);updateTaskStatus(task.getTaskId(), "SUCCESS");} catch (Exception e) {updateTaskStatus(task.getTaskId(), "FAILED");}});} else {try {Thread.sleep(SLEEP_INTERVAL); // 无任务,休眠} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}}private Task getPendingTask() {return taskRepository.findFirstByStatusOrderByPriorityDescCreateTimeAsc("INIT");}private void executeTask(Task task) {// 任务执行逻辑System.out.println("Executing task: " + task.getTaskId());}private void updateTaskStatus(Long taskId, String status) {taskRepository.updateStatus(taskId, status);}
}
四、使用阻塞队列解耦生产者-消费者
为了更好地解耦任务生产者和消费者,我们可以使用阻塞队列。生产者从任务表中拉取任务并放入队列,消费者从队列中取任务并执行。这种方式能够有效地隔离任务生产和消费的压力。
import java.util.concurrent.*;public class TaskScheduler {private static final int THREAD_POOL_SIZE = 10;private static final int SLEEP_INTERVAL = 5000;private static final BlockingQueue<Task> taskQueue = new LinkedBlockingQueue<>();private TaskRepository taskRepository;private ExecutorService executorService;public TaskScheduler(TaskRepository taskRepository) {this.taskRepository = taskRepository;this.executorService = Executors.newFixedThreadPool(THREAD_POOL_SIZE);}public void start() {// 启动消费者线程池for (int i = 0; i < THREAD_POOL_SIZE; i++) {executorService.submit(this::consumeTasks);}// 生产者循环,持续从数据库拉取任务并放入队列while (true) {Task task = getPendingTask();if (task != null) {try {taskQueue.put(task); // 将任务放入队列updateTaskStatus(task.getTaskId(), "PROCESSING");} catch (InterruptedException e) {Thread.currentThread().interrupt();}} else {try {Thread.sleep(SLEEP_INTERVAL); // 无任务,休眠} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}}private void consumeTasks() {while (true) {try {Task task = taskQueue.take(); // 从队列中取任务executeTask(task);updateTaskStatus(task.getTaskId(), "SUCCESS");} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}private Task getPendingTask() {return taskRepository.findFirstByStatusOrderByPriorityDescCreateTimeAsc("INIT");}private void executeTask(Task task) {// 任务执行逻辑System.out.println("Executing task: " + task.getTaskId());}private void updateTaskStatus(Long taskId, String status) {taskRepository.updateStatus(taskId, status);}
}
五、分布式任务调度
随着任务量的增加,单机版的任务调度框架可能会遇到性能瓶颈。此时,我们可以考虑分布式任务调度框架。
(一)分片ID(取模分片)
将任务根据 task_id 进行分片处理,每个机器只负责一个特定范围的任务。
例如,通过 task_id % N 来决定任务属于哪个分片,这样可以使每台机器只处理一部分任务。
(二)中心化调度(使用 Redis)
我们可以使用 Redis 来实现分布式任务调度。任务生产者将任务推送到 Redis 队列,任务消费者从队列中获取任务并执行。
import redis.clients.jedis.Jedis;public class DistributedTaskScheduler {private Jedis jedis;private ExecutorService executorService;public DistributedTaskScheduler(Jedis jedis) {this.jedis = jedis;this.executorService = Executors.newFixedThreadPool(10);}public void start() {while (true) {String taskJson = jedis.blpop(0, "taskQueue").get(1); // 阻塞式取任务Task task = deserializeTask(taskJson);executorService.submit(() -> {try {executeTask(task);updateTaskStatus(task.getTaskId(), "SUCCESS");} catch (Exception e) {updateTaskStatus(task.getTaskId(), "FAILED");}});}}private void executeTask(Task task) {// 任务执行逻辑System.out.println("Executing task: " + task.getTaskId());}private void updateTaskStatus(Long taskId, String status) {// 更新任务状态}private Task deserializeTask(String taskJson) {return new Gson().fromJson(taskJson, Task.class);}
}
六、结论
本文介绍了如何设计并实现一个简单的高吞吐、高可用的任务调度系统。我们从任务的状态管理、任务的并发执行、失败重试机制到分布式任务调度等方面进行了详细的探讨。通过合适的设计模式和技术栈,我们能够实现一个灵活且高效的任务调度系统,满足业务需求并具备良好的扩展性和容错性。
未来可以在此框架的基础上增加更多的功能,例如任务优先级、任务分片、动态调整线程池、任务监控与报警等。