ecs做网站市场调研公司
文章目录
- 索引(重点)
- 硬件理解
- 磁盘
- 盘片和扇区
- 定位扇区
- 磁盘的随机访问和连续访问
- 软件方面的理解
- 建立共识
- 索引的理解

索引(重点)
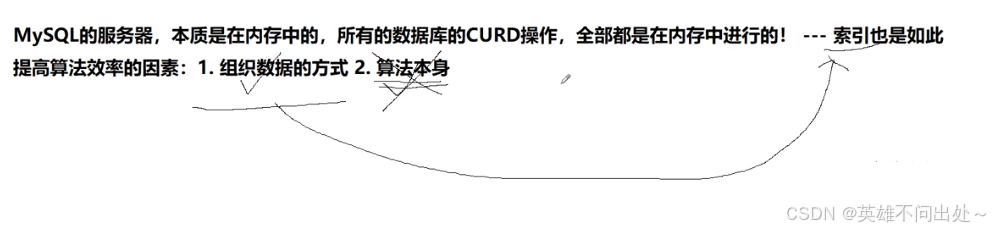
- 索引可以提高数据库的性能,它的价值,在于提高一个海量数据的检索速度。
案例:
建立一个海量表
drop database if exists 'my_index';
create database if not exists 'my_index' default character set utf8;
use 'my_index';--构建一个8000000条记录的数据
--构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解--产生随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin declare chars_str varchar(100) default'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';declare return_str varchar(255) default '';declare i int default 0;while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));set i = i + 1;end while;return return_str;end $$
delimiter ;--产生随机数字
delimiter $$
create function rand_num()
returns int(5)
begin declare i int default 0;set i = floor(10+rand()*500);
return i;
end $$
delimiter ;--创建存储过程,向雇员表添加海量数据
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0; set autocommit = 0; repeatset i = i + 1;insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());until i = max_numend repeat;commit;
end $$
delimiter ;--执行存储过程,添加8000000条记录
call insert_emp(100001, 8000000);
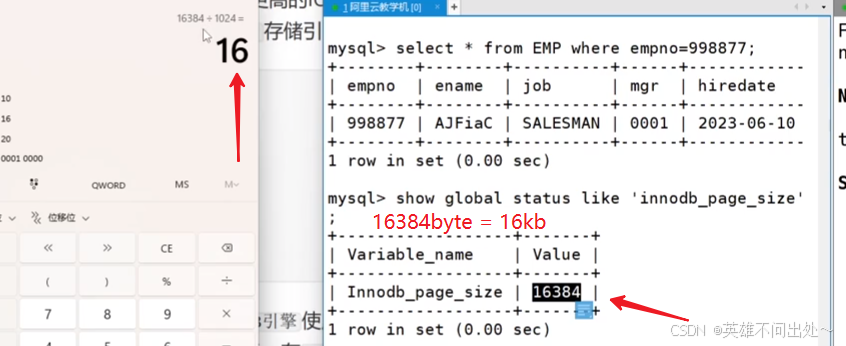
查询员工编号为998877的员工
select * from emp where empno=998877;

花了6.17秒,就你一个人就花了6秒,如果公司人很多,会死机的
给表加上索引
alter table emp add index(empno);
很明显加上索引之后,速度明显变快了

-
硬件->系统->MySQL
-
常见索引分为:
主键索引(primary key)
唯一索引(unique)
普通索引(index)
全文索引(fulltext)–解决中子文索引问题。 -
先整一个海量表,在查询的时候,看看没有索引时有什么问题?
在海量的数据表中没有索引查询起来会变得很慢,如果有索引可以加快查询的速度 -
给emp表添加索引
alter table emp add index(empno);
硬件理解
磁盘
- MySQL中的每一个表就是一个文件
- MySQL 给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。磁盘是计算机中的一个机械设备,相比于计算机其他电子元件,磁盘效率是比较低的,在加上IO本身的特征,可以知道,如何提交效率,是 MySQL 的一个重要话题。

盘片和扇区
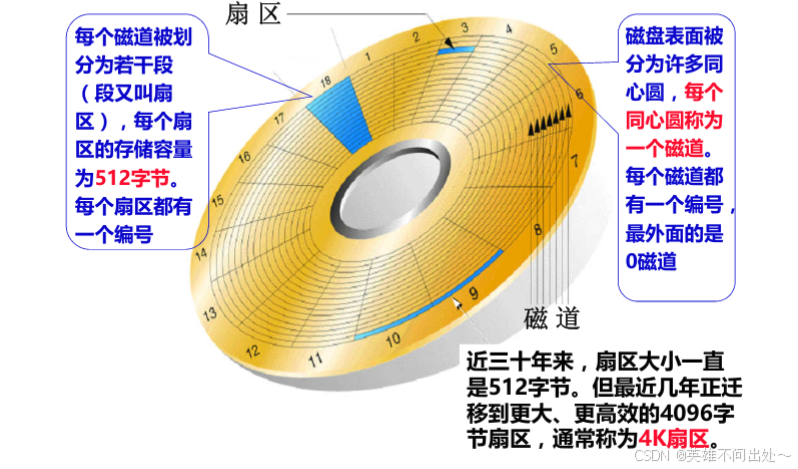
- 扇区:数据库文件,本质其实就是保存在磁盘的盘片当中。也就是上面的一个个小格子中,就是我们经常所说的扇区。当然,数据库文件很大,也很多,一定需要占据多个扇区。
- 在半径方向上,距离圆心越近,扇区越小,距离圆心越远,扇区越大
- 那么,所有扇区都是默认512字节吗?目前是的,我们也这样认为。因为保证一个扇区多大,是由比特位密度决定的。
- 我们在使用Linux,所看到的大部分目录或者文件,其实就是保存在硬盘当中的。(当然,有一些内存文件系统,如: proc , sys 之类,我们不考虑)
- 数据库文件,本质其实就是保存在磁盘的盘片当中,就是一个一个的文件,找到一个文件的全部,本质,就是在磁盘找到所有保存文件的扇区。
- 而我们能够定位任何一个扇区,那么便能找到所有扇区,因为查找方式是一样的。
定位扇区
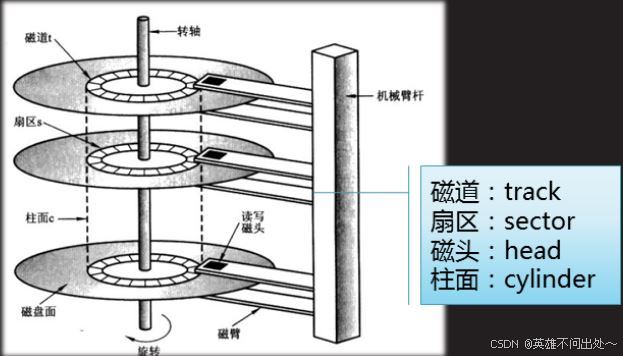
- 先找到柱面,再找磁头,最后找到扇区(chs)
- 系统读取磁盘是以块为单位的,基本单位是4kb,因为不以块为单位,以扇区为单位的话,一个是效率太慢,磁头每次都要转到相应的位置开始读取,单次是512字节,读取的量太少,第二个是耦合度太高,不便于硬件或操作系统各自升级
磁盘的随机访问和连续访问
- 随机访问:本次IO所给出的扇区地址和上次IO给出扇区地址不连续,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。
- 连续访问:如果当次IO给出的扇区地址与上次IO结束的扇区地址是连续的,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。
- 因此尽管相邻的两次IO操作在同一时刻发出,但如果它们的请求的扇区地址相差很大的话也只能称为随机访问,而非连续访问。(所以OS的文件系统一般就会将我们的一些IO请求在底层做一些归类和排序,尽可能地增加连续访问的可能,另一方面减少了磁头的摆动次数也能提高磁盘的使用寿命)
- 磁盘是通过机械运动进行寻址的,随机访问不需要过多的定位,故效率比较高。
软件方面的理解
- 为了提高基本的IO效率, MySQL 进行IO的基本单位是 16KB,使用 InnoDB 存储引擎
- 再数据块的流动方面都是数据块给操作系统,操作系统给mysql,mysql给操作系统,操作系统给磁盘
- MySQL 中的数据文件,是以page为单位保存在磁盘当中的。
- 证明MySQL是以16kb为单位的
- 也就是说,磁盘这个硬件设备的基本单位是 512 字节,而 MySQL InnoDB引擎使用 16KB 进行IO交互。即, MySQL 和磁盘进行数据交互的基本单位是 16KB 。这个基本数据单元,在 MySQL 这里叫做page(注意和系统的page区分)
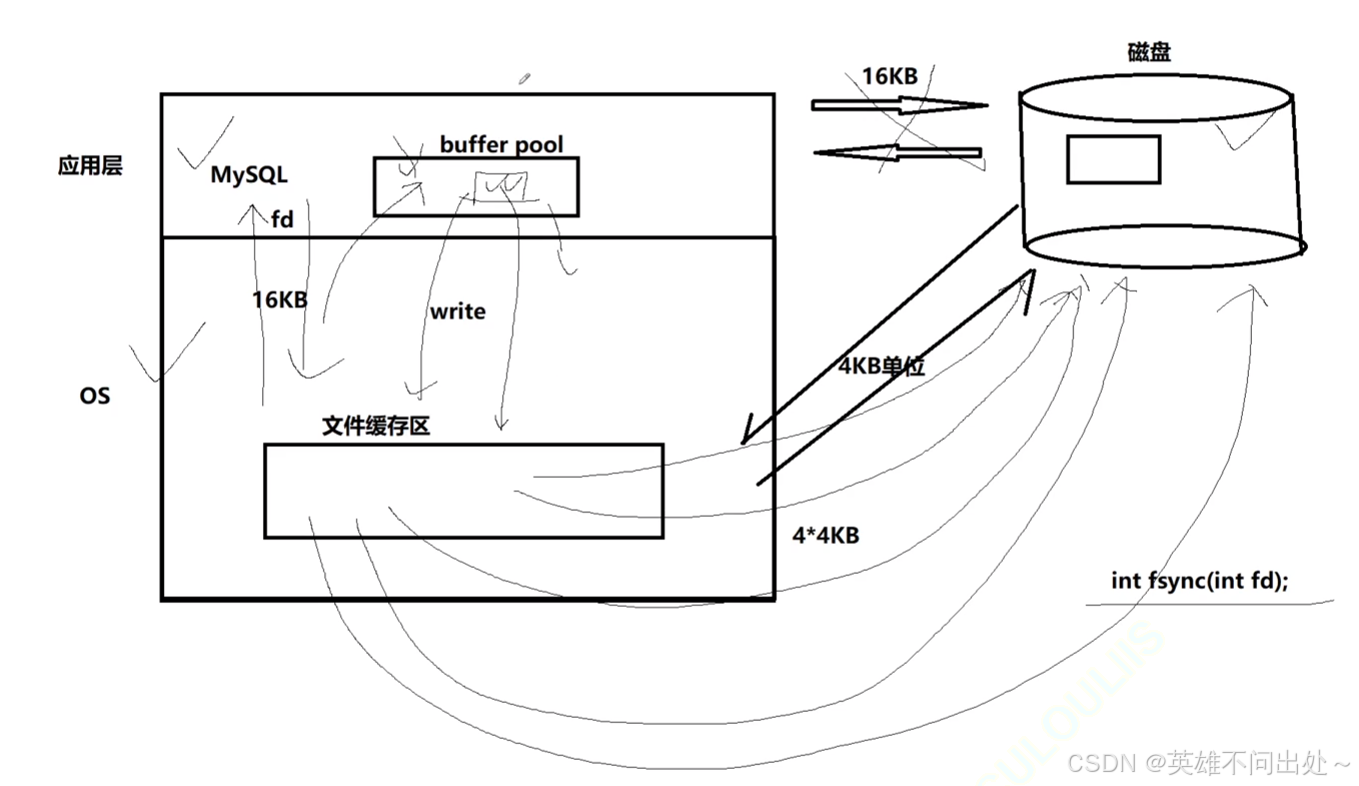
建立共识
- MySQL以16kb为单位进行mysql级别的IO
- MySQL要有自己的buff pool(缓冲池),会把数据读到buff pool里,把buff pool的数据刷新到操作系统的缓冲区里,最后刷新到磁盘
- 一定要尽可能的减少系统和磁盘IO的次数,一次IO的数据量越大,比多次IO数据量小效率更高
- mysql会预先开辟一个128mb的缓冲池
索引的理解
- 建立测试表,存储引擎默认是InnoDB的
create table if not exists user (id int primary key, --一定要添加主键哦,只有这样才会默认生成主键索引age int not null,name varchar(16) not null
);
show create table user \G;
- 插入信息,插入5条无序的数据
--插入多条记录,注意,我们并没有按照主键的大小顺序插入哦
mysql> insert into user (id, age, name) values(3, 18, '杨过');
mysql> insert into user (id, age, name) values(4, 16, '小龙女');
mysql> insert into user (id, age, name) values(2, 26, '黄蓉');
mysql> insert into user (id, age, name) values(5, 36, '郭靖');
mysql> insert into user (id, age, name) values(1, 56, '欧阳锋');
- 查看表中的内容,发现数据是有序的

4. 理解page

5. 为何io操作要page?
为了减少IO的次数,提高IO的效率,在单个page中,不在单个page中,会进行多次IO操作
你怎么保证,用户一定下次找的数据,就在这个Page里面?---->我们不能严格保证,但是有很大概率再一个Page当中或者是周围的,因为有局部性原理。