百度百科官网上海seo网站优化软件
一、前言
MNIST(Modified National Institute of Standards and Technology)是一个经典的手写数字图像数据集,由美国国家标准与技术研究院(NIST)在20世纪80年代整理和标注。以下是关于MNIST数据集的详细介绍:
数据集组成
- 训练集:包含60,000张手写数字图像。
- 测试集:包含10,000张手写数字图像。
- 图像尺寸:每张图像都是28x28像素的灰度图像。
- 像素值范围:每个像素的灰度值在0到255之间。
- 标签:每个图像都有一个对应的标签,表示图像中的手写数字(0到9)。12345
应用领域
- 数字识别:训练机器学习模型以识别手写数字。
- 自动化填写:结合光学字符识别(OCR)技术,实现自动化表单填写。
- 目标检测与跟踪:在图像或视频中检测和跟踪手写数字。
SUM:该数据集自1998年起,被广泛地应用于机器学习和深度学习领域,用来测试算法的效果,例如线性分类器(Linear Classifiers)、K-近邻算法(K-Nearest Neighbors)、支持向量机(SVMs)、神经网络(Neural Nets)、卷积神经网络(Convolutional nets)等等
二、载入数据
1、文件简介:
训练数据集:train-images-idx3-ubyte.gz (9.45 MB,包含60,000个样本)。
训练数据集标签:train-labels-idx1-ubyte.gz(28.2 KB,包含60,000个标签)。
测试数据集:t10k-images-idx3-ubyte.gz(1.57 MB ,包含10,000个样本)。
测试数据集标签:t10k-labels-idx1-ubyte.gz(4.43 KB,包含10,000个样本的标签)。
2、下载地址:
数据集本地下载地址:
链接:https://pan.baidu.com/s/16PBnJLzcj-3znWSbIHBzew
提取码:hjzsMNIST数据集官网地址为http://yann.lecun.com/exdb/mnist/(现在进不去了不知道为啥)
百度网盘文件来自网友:计算机视觉两个入门数据集(mnist和fashion mnist)本地下载地址_mnist官网-CSDN博客
网盘 所下载的是npz格式,
3、两种文件格式使用方式:
(1)如果下载的是npy格式:

x_train 和 y_train_label 是从 .npy 文件加载的 NumPy 数组。
我们先加载数据,然后打印矩形张量(即多维数组)的内容。
import numpy as np# 载入数据
x_train = np.load("dataset/mnist/x_train.npy")
y_train_label = np.load("dataset/mnist/y_train_label.npy")# 打印 x_train 的形状
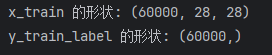
print("x_train 的形状:", x_train.shape)# 打印 y_train_label 的形状
print("y_train_label 的形状:", y_train_label.shape)
(2)如果下载的是npz格式:you need to use the numpy.load() function.
import numpy as np#使用Python中的NumPy库data = np.load('mydata.npz')# 使用numpy.load()函数读取npz文件print(data.files)# List all arrays in the NPZ filearray = data['array_name']# 通过键访问数组。print(array) 实例:
import numpy as np
import matplotlib.pyplot as plt# 导入相关模块# 加载数据
data = np.load('dataset/mnist.npz')
x_train = data['x_train']
y_train = data['y_train']print("x_train 的形状:", x_train.shape)
print("y_train_label 的形状:", y_train.shape)两种方式的效果都一样:
三、读取模式分类应用
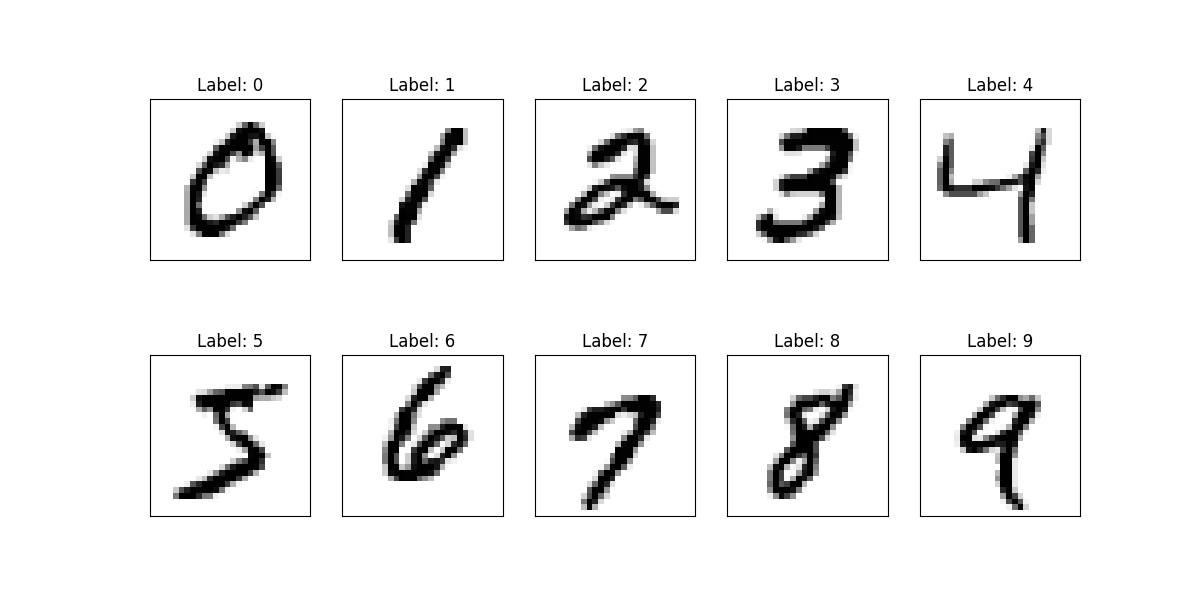
1、取每个标签第一个
import matplotlib.pyplot as plt# 导入相关模块
from tensorflow.keras.datasets import mnist# 导入mnist模块
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 导入数据
# 输出数据维度
print("x_train 的形状:", x_train.shape)
print("y_train_label 的形状:", y_train.shape)
# 指定绘图尺寸
plt.figure(figsize=(12, 8))
# 绘制10个数字
for i in range(10):# 找到每个类别的第一个样本img = x_train[y_train == i][0].reshape(28, 28)plt.subplot(2, 5, i + 1)plt.xticks([])plt.yticks([])plt.imshow(img, cmap=plt.cm.binary)plt.title(f'Label: {i}')plt.show()
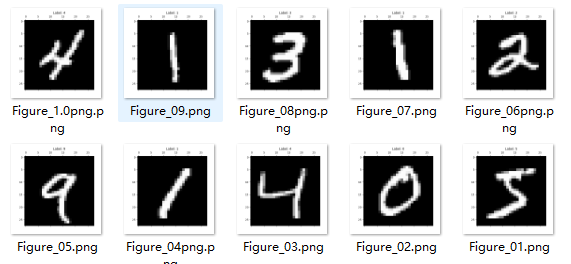
2、随机读取数据
import numpy as np
import matplotlib.pyplot as plt# 导入相关模块
from tensorflow.keras.datasets import mnist# 导入mnist模块
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 导入数据
# 加载数据
print("x_train 的形状:", x_train.shape)
print("y_train_label 的形状:", y_train.shape)# img = np.reshape(train_img[i, :], (28, 28))# label = np.argmax(train_img[i, :])for i in range(10):img = x_train[i]label = y_train[i]plt.matshow(img, cmap=plt.get_cmap('gray'))plt.title(f'Label: {label}')plt.show()
3、unet模型读取
由于复杂性和速度很慢,这里就不展开了

