网站建设技术培训学校seo关键词排名优化案例
听的b站上的这个课做的笔记,这是上集
这是下集
LLM预备知识
LLM从2017年谷歌提出Transformer结构开始,通过堆叠transformer架构实现参数扩充。现在有三条技术路线:
- 只用encoder的Bert(谷歌)
- 只用decoder的GPT(OpenAI)
- encoder和decoder都用的T5(谷歌清华GLM)
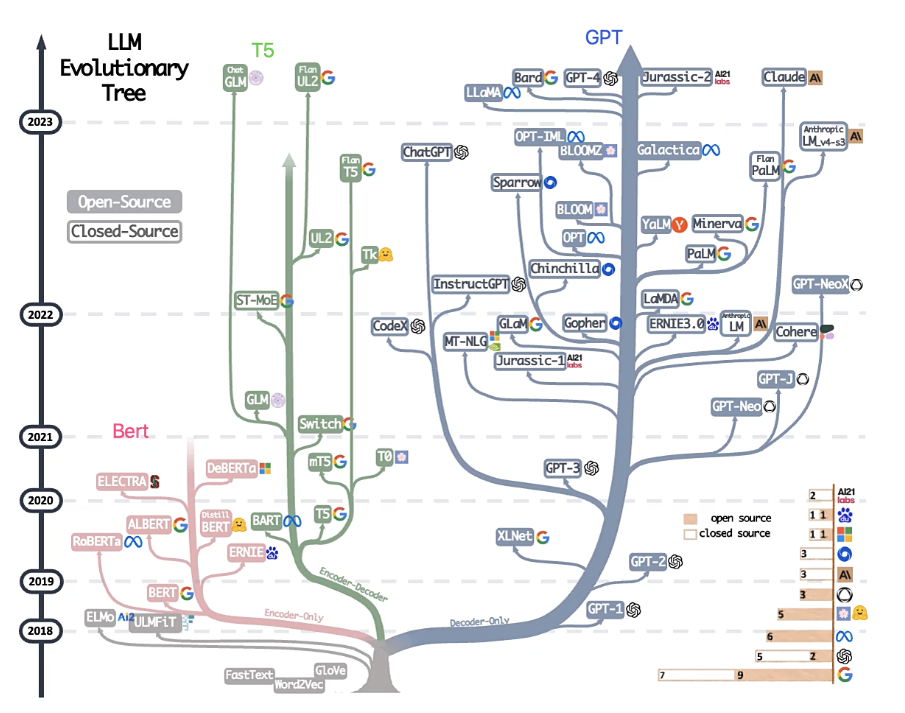
无论是哪种技术路线,都是基于预训练+微调的范式。
预训练pre-training是指在非常大的数据集上从头开始训练模型,这往往需要大量计算资源和时间,有以下三个特点:
- 数据集要求高
- 模型参数规模要求高
- 算力要求高
DeepSeek引起轰动的主要原因是突破了第三个障碍:在预训练阶段节省了内存,提高了训练效率。
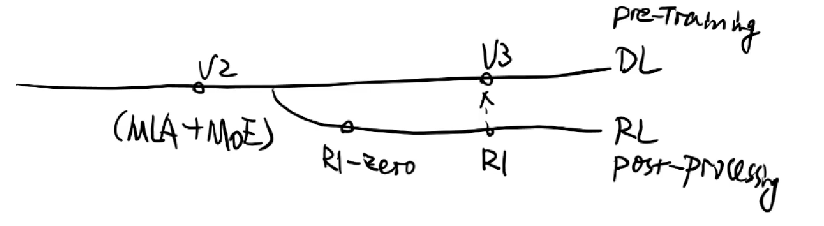
DeepSeek预训练是用的V3模型,有以下三个重要的改进:
- MLA(multi-head latent attention)->内存节省和训练效率
- DeepSeekMoE(混合专家模型)->内存节省和训练效率
- DeepSeek-R1->推理性能的提升
后期训练 post-training 是对已经训练好的模型进行调整和优化,提高推理任务的准确性,在计算资源上要求比较少。现在有三种微调(fine-tuning)方式:
- 早期:监督微调SFT, supervised fine tuning
- GPT3.5及后续版本:人类反馈强化学习RLHF, reinforcement learning from human feedback
- R1
知识蒸馏:蒸馏与微调的区别在于数据来源不同。
微调:额外标注的数据集(人工标注或合成)
蒸馏:教师模型提供的知识,让学生模型逼近教师模型
DeepSeek R1系列模型拆解
R1系列模型发展路径
DeepSeek-R1-Zero: 纯强化学习的懒人模型
损失函数
具体采用GRPO算法,并更改了损失函数
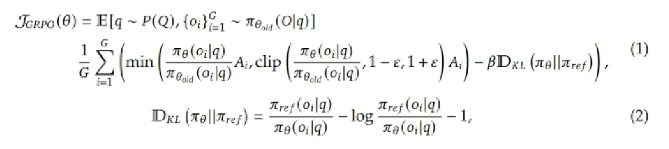
期望E的角标中(第一行),q是指问题query,P(Q)是指问题整体概率的分布,比如数学题,编程题等。 o是输出output,生成了G个output. θold是指老的策略的参数。
在强化学习建模中前者q是一种状态,o是策略π生成的动作,这其实是一个强化学习序列问题:

红色的部分:指对group里G个数据求均值。
绿色的部分:一个分式与Ai相乘。其中分式指的是新策略基于问题q给出回答oi的概率除以旧策略基于问题q给出回答oi的概率,二者的比值相当于求了一个权重,再乘上Ai,可以将Ai视为一种“优势”,可以理解成一种价值函数,用于衡量当前答案相对于平均表现的好坏,决定应该被强化还是削弱。这种用新旧策略的比例系数,对Ai进行调整的方法叫做重要性采样(importance sampling)技术。
蓝色的部分和棕黄色部分源于近端策略优化(proximal policy optimization, PPO). 近端的意思是用后面KL项进行约束,起到一种正则化的作用,限制策略的变化幅度,防止训练时漂移太远,不稳定。β是经验系数,用于实现动态惩罚。
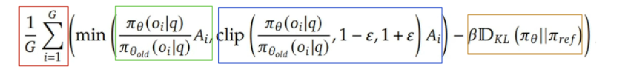
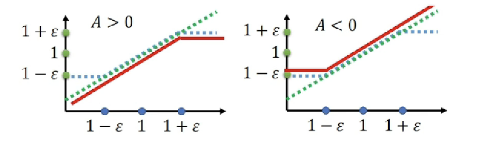
对于蓝色部分,具体来说如下图所示:
clip限制了新旧策略概率(绿色折线)比例在1-ε到1+ε,变成了蓝色折线。像这样裁剪的目的,是不想让损失函数震荡,出现特别大或者特别小的值。
橙黄色部分:πref指一种理想的方式,对πθ和πref求散度,实际上是在引导训练向理想策略看齐。
绿色部分就相当于油门,蓝色部分相当于刹车,而橙黄色部分相当于教练。
整体上来看,GRPO损失函数的设计目标是稳定策略优化过程,防止策略更新过大导致不稳定或崩溃。
KL散度实际上是在求两个概率分布的差异。标准KL散度如下所示:
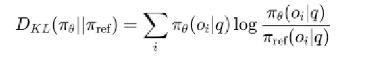
但是R1里的KL散度变体为:
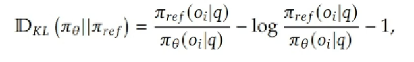
这里的-1相当于一个bias
奖励函数
优势函数Ai的计算与奖励函数息息相关,其中的r1……rg就是G个备选答案的奖励值。实际上就是将奖励函数标准化。
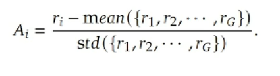
奖励函数的设计没有详细的披露,只介绍了大概的思路。总体来说是基于规则的设计,先确定一个类似思维链COT的分步骤模板。基于推理链Cot设计奖励函数。比如解答数学题或者编程题,会被拆分成多个步骤。每步的结果和格式都会得当相应的奖励。
R1-zero是基于规则的奖励函数设计,提升了推理效率。

三种post-traing方法的优缺点:
- SFT = 监督学习,喂数据,类似 BERT、GPT3、T5 等传统人模型,受制于数据质量
- RLHF = 学习评分标准 +RL优化,比 SFT 强,但奖励模型依然受制于数据
- DeepSeek-R1-Zero = 纯 RL 规则奖励,摆脱 SFT 和 RLHF 局限性,不依赖标注数据
DeepSeek-R1: SFT+RL
- SFT1: 冷启动,其实就是用SFT 优化强化学习的起始点,具休说,就是人工“过滤+后处理“收集了一批数据,定义了输出数据将式样例,然后 SFT 训练得到能生成清晰思维链的初始策略,这样训出来的模型可读、更精准、更符合人类偏好,而不是杂乱无章或难以理解。
- RL1: 面向推理的 RL。希望增强模型在代码、数学、科学和逻辑推理任务上的能力,其实就是有针对性的给出解题思维链,然后设置奖励函数。具体来说:准确性奖助(accuracy reward)语言一致性奖励 (language consistency feward,比如回答的语言和问题的语言一致,都是中文或都是英文).
- SFT2: 拒绝采样与监督微调 (Rejection Sampling and SFT)。核心思想就是用 RL 训练出的策略生成数据,然后人工筛选、过滤、优化,然后再监督微调SFT。
- RL2: 全场景强化学习。相当于二次强化学习,提升推埋能力、实用性和安全性
其他知识
强化学习RL
之前学过的笔记在这里:RL,近端策略优化PPO也在这节课
知识蒸馏Knowledge Distillation
之前的笔记在这里:Knowledge Distillation