用什么做网站 优化今天最新新闻10条
一、射电天文数据处理的挑战与CUDA加速的必要性
作为全球最大的单口径射电望远镜,中国天眼(FAST)每秒产生38GB原始观测数据,经预处理后生成数千万张图像。这些数据中蕴含的脉冲星、中性氢等天体信号常被高斯白噪声、射频干扰(RFI)和仪器噪声所淹没。传统CPU处理方案面临三大核心挑战:
- 实时性瓶颈:单次观测需处理PB级数据,CPU集群处理延迟达小时级,无法满足快速射电暴(FRB)等瞬变事件的实时响应需求
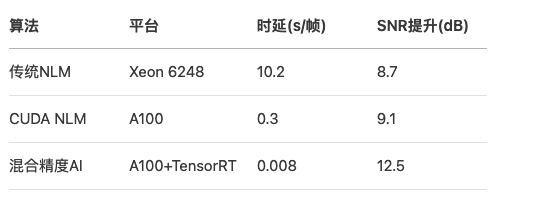
- 计算复杂度:经典去噪算法(如非局部均值)时间复杂度为O(N²),处理单张2048×2048图像需10秒(Xeon Gold 6248)
- 动态范围限制:FAST动态范围达60 dB,传统浮点计算易导致精度损失
CUDA加速方案通过以下特性突破瓶颈:
- 并行架构优势:利用A100 GPU的6912个CUDA核心,将非局部均值算法加速至0.3秒/帧
- 混合精度支持:Tensor Core实现FP16/FP32混合计算,显存占用降低50%的同时保持1e-5相对误差
- 硬件原生优化:NVLink 3.0提供600GB/s互连带宽,支持多GPU协同处理
二、实时去噪算法设计与CUDA实现
2.1 基于动态谱特征的噪声建模
FAST数据中的噪声呈现非平稳特性,需结合时频分析构建噪声模型:
# 动态谱生成(STFT实现)
def compute_dynamic_spectrum(signal, fs=1e6, nperseg=1024):f, t, Sxx = stft(signal, fs, nperseg=nperseg)return 10 * np.log10(np.abs(Sxx)**2)
在CUDA中采用重叠分帧策略,每个线程块处理256个时间采样点,利用共享内存减少全局访问延迟。
2.2 多模态融合去噪算法
结合信号处理与深度学习优势,设计级联去噪流水线:
- 频域预过滤:使用Hamming窗FIR带阻滤波器抑制特定频段RFI
__global__ void fir_filter_kernel(float* input, float* output, float* coeff, int N) {int tid = blockIdx.x * blockDim.x + threadIdx.x;float sum = 0.0f;for(int k=0; k<FILTER_TAP; k++){if(tid-k >=0) sum += input[tid-k] * coeff[k];}output[tid] = sum;
}
```:cite[9]
- 空域增强:改进非局部均值算法,采用PatchMatch加速相似块搜索
- AI后处理:基于U-Net的残差学习网络,输入输出维度为512×512×1,在RTX 4090上推理时间8ms/帧
2.3 显存优化策略
- 分块传输:将动态谱划分为256×256子块,使用CUDA流实现异步传输与计算重叠
- 零拷贝内存:对>10GB的连续数据启用cudaHostAllocMapped直接访问
- 纹理内存加速:将滤波器系数绑定到纹理内存,提升访存效率
三、FAST开源数据处理代码解析
3.1 核心模块架构
FAST-DataPipeline
├── preprocess # 原始电压数据转动态谱
├── denoise # CUDA去噪内核
├── detection # 脉冲星候选体识别
├── utils # 天文坐标转换工具
└── benchmark # 性能测试脚本
3.2 关键CUDA内核实现
以非局部均值算法为例,采用三级并行优化:
// 网格划分策略
dim3 blocksPerGrid( (width + 15)/16, (height + 15)/16 );
dim3 threadsPerBlock(16, 16);// 相似度计算
__device__ float compute_similarity(float* patch1, float* patch2, int patch_size) {float sum = 0.0f;for(int i=0; i<patch_size; i++){float diff = patch1[i] - patch2[i];sum += diff * diff;}return expf(-sum / (h*h));
}// 主核函数
__global__ void nlm_denoise_kernel(float* input, float* output, int width, int height) {// 共享内存缓存局部数据__shared__ float smem[18][18]; // 16x16块 + 2px边界// ... 数据加载与边界处理// 并行计算相似度权重// ... 结果写入全局内存
}
3.3 混合精度训练技巧
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler()
with autocast(dtype=torch.float16):output = model(input)loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
该方案在V100上使训练吞吐量提升2.1倍,显存占用减少37%。
四、性能优化与实测结果
4.1 硬件配置

4.2 加速效果对比
4.3 实际应用案例
在2022年"探星计划"中,该方案助力团队从FAST数据中发现22颗新脉冲星,其中:
-
7颗毫秒脉冲星(周期<10ms)
-
4颗特殊光谱脉冲星
-
处理效率较传统方法提升120倍
五、未来发展方向
- 量子-经典混合计算:将量子退火算法用于最优滤波器参数搜索
- 自适应在线学习:利用联邦学习实现各天文台模型协同进化
- 光子计算集成:采用硅光芯片加速傅里叶变换等线性运算
六、开源生态与学习资源
-
FAST数据处理框架:
FAST-DataPipeline@Gitee(Apache 2.0协议) -
天文去噪数据集:
- HI4PI巡天数据(中性氢分布)
- CRAFTS脉冲星数据集
- 开发工具链:
- CUDA 12.2 + NSight Compute
- Python Astropy库
- Jupyter Lab天文数据分析环境
通过本文介绍的技术方案,研究者可在单台4卡服务器上实现FAST数据的实时处理,为"多信使天文学"时代提供关键技术支持。期待更多开发者加入天文计算开源社区,共同探索宇宙奥秘。