自己做网站代理产品如何做网络推广赚钱
构建和训练一个简单的CBOW词嵌入模型
在自然语言处理(NLP)领域,词嵌入是一种将词汇映射到连续向量空间的技术,这些向量能够捕捉词汇之间的语义关系。在这篇文章中,我们将构建和训练一个简单的Continuous Bag of Words(CBOW)词嵌入模型,使用PyTorch框架。
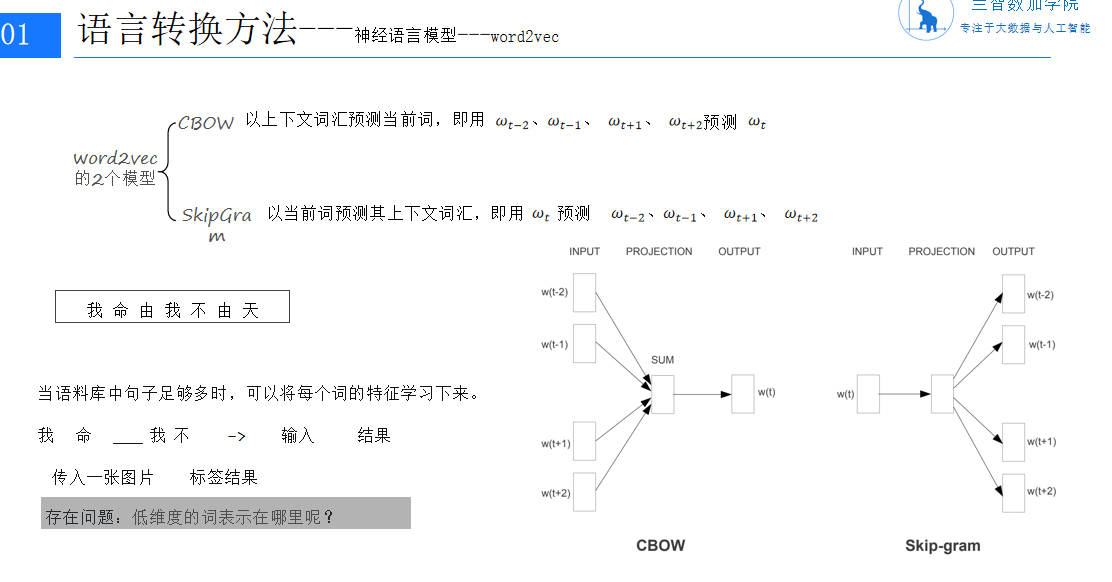
简介
CBOW模型是一种预测给定上下文中目标词的模型。它通过学习上下文词的向量表示来预测目标词。这种方法在处理大量文本数据时非常有效,因为它可以捕捉词汇之间的语义和语法关系。
环境准备
在开始之前,确保你的环境中安装了以下库:
- PyTorch
- NumPy
- tqdm(用于显示进度条)
如果未安装,可以通过以下命令安装:
pip install torch numpy tqdm
数据准备
我们将使用一个简单的文本语料库来训练我们的模型。这个语料库包含一些句子,我们将从中提取词汇和构建训练数据集。
raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells."""
数据预处理
首先,我们需要将文本转换为模型可以理解的格式。这包括创建词汇表、单词到索引的映射以及构建训练数据集。
vocab= set(raw_text) # 集合。词库,里面内容就是无人
vocab_size = len(vocab) # 计算词汇集合的大小word_to_idx = {word: i for i, word in enumerate(vocab)} # for 循环的复合写法。第1次循环,i得到的索引号, word 取1个单词
idx_to_word = {i: word for i, word in enumerate(vocab)}data = [] # 获取上下文词, 将上下文词作为输入, 目标词作为输出。构建训练数据集。
# 遍历文本,提取上下文和目标词对,构建训练数据集
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE): # (2, 60)。context = ([raw_text[i - (2-j)] for j in range(CONTEXT_SIZE)] + # 获取左边的上下文词[raw_text[i + j + 1] for j in range(CONTEXT_SIZE)] # 获取右边的上下文词) # 获取上下文词 ['we','are','to','study']target = raw_text[i] # 获取目标词 'about'data.append((context, target)) # 将上下文词和目标词保存到data中[((['we','are','to','study']),'about')]模型定义
接下来,我们定义CBOW模型。这个模型包括嵌入层、投影层和输出层。
# 定义CBOW模型类
class CBOW(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOW, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim) # 定义嵌入层self.proj = nn.Linear(embedding_dim, 128) # 定义投影层self.output = nn.Linear(128, vocab_size) # 定义输出层def forward(self, inputs):embeds = sum(self.embeddings(inputs)).view(1, -1) # 计算上下文词的嵌入向量的平均值out = F.relu(self.proj(embeds)) # 通过ReLU激活函数out = self.output(out) # 通过输出层nll_prob = F.log_softmax(out, dim=1) # 计算负对数似然损失return nll_prob
训练模型
现在,我们训练模型。我们将使用Adam优化器和负对数似然损失函数。
# 确定设备(GPU或CPU)
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(device)
# 初始化模型并将其移动到指定设备
model = CBOW(vocab_size, 10).to(device)# 初始化优化器
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器# 初始化损失列表
losses = []
# 定义损失函数
loss_function = nn.NLLLoss()
# 设置模型为训练模式
model.train()
# 训练模型100个epoch
for epoch in tqdm(range(100)): # 开始训练total_loss = 0# 遍历所有数据for context, target in data:context_vector = make_context_vector(context, word_to_idx).to(device)target = torch.tensor([word_to_idx[target]]).to(device)# 开始前向传播train_predict = model(context_vector)loss = loss_function(train_predict, target)# 反向传播optimizer.zero_grad() # 梯度值清零loss.backward() # 反向传播计算得到每个参数的梯度值optimizer.step() #根据梯度更新网络参数total_loss += loss.item()# 记录每个epoch的损失losses.append(total_loss)print(losses)
测试模型
最后,我们测试模型,看看它如何预测给定上下文的下一个词。
# 定义一个上下文列表,包含四个词
context = ['People', 'create', 'to', 'direct']# 将上下文词转换为模型可以理解的向量形式
context_vector = make_context_vector(context, word_to_idx).to(device)# 将模型设置为评估模式,在评估模式下,模型的行为会有所改变,例如不会应用Dropout等
model.eval()# 使用模型进行预测,传入上下文向量
predict = model(context_vector)# 获取预测结果中概率最高的索引值,这个索引值对应预测的下一个词
max_idx = predict.argmax(1)# 打印出输入的上下文
print('context', context)# 使用索引到单词的映射字典,将预测的索引值转换为对应的单词,并打印出来
print("Predicted next word:", idx_to_word[max_idx.item()])
运行结果
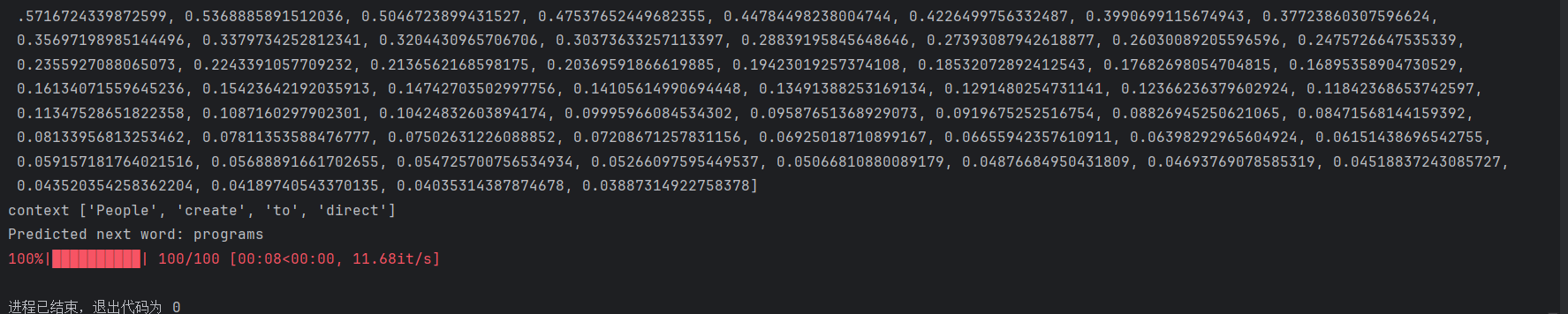
结论
通过这篇文章,我们构建了一个简单的CBOW词嵌入模型,并使用PyTorch框架进行了训练和测试。这个模型能够学习词汇的向量表示,并预测给定上下文的下一个词。这对于许多NLP任务,如文本分类、情感分析等,都是非常有用的。