装修公司那家好台州网站优化公司
学习视频:
04 向量数据库_哔哩哔哩_bilibili
目录
什么是 RAG ?
下载文本向量模型
模型示例数据
切割向量化代码
向量数据库
文本生成模型(推理)/ deepseek本地部署
什么是 RAG ?
Retrieval-Augmented Generation (RAG) 是一种结合了信息检索与文本生成的先进模型架构,旨在提高自然语言处理任务中的准确性和相关性。不同于传统的端到端生成模型,RAG 通过整合外部知识库来增强其输出内容的质量。具体来说,RAG 首先利用一个检索组件从大规模语料库中动态查找与输入查询最相关的文档或段落,然后将这些检索到的信息作为额外上下文传递给生成组件。这样,生成模型不仅能基于预训练的语言知识,还能依据最新的、具体的资讯来生成回复,从而确保了输出内容的时效性和准确性。
RAG 特别适用于需要实时更新和专业领域知识的应用场景,如智能问答系统、个性化推荐和对话机器人等。通过这种方式,RAG 克服了传统生成模型仅依赖于固定时间点上训练数据的局限,实现了更灵活、更强大的自然语言理解和生成能力。这种架构不仅提升了对话语义的相关性,也加强了事实核查的能力,使得生成的回答更加可靠。
本文实现框架:
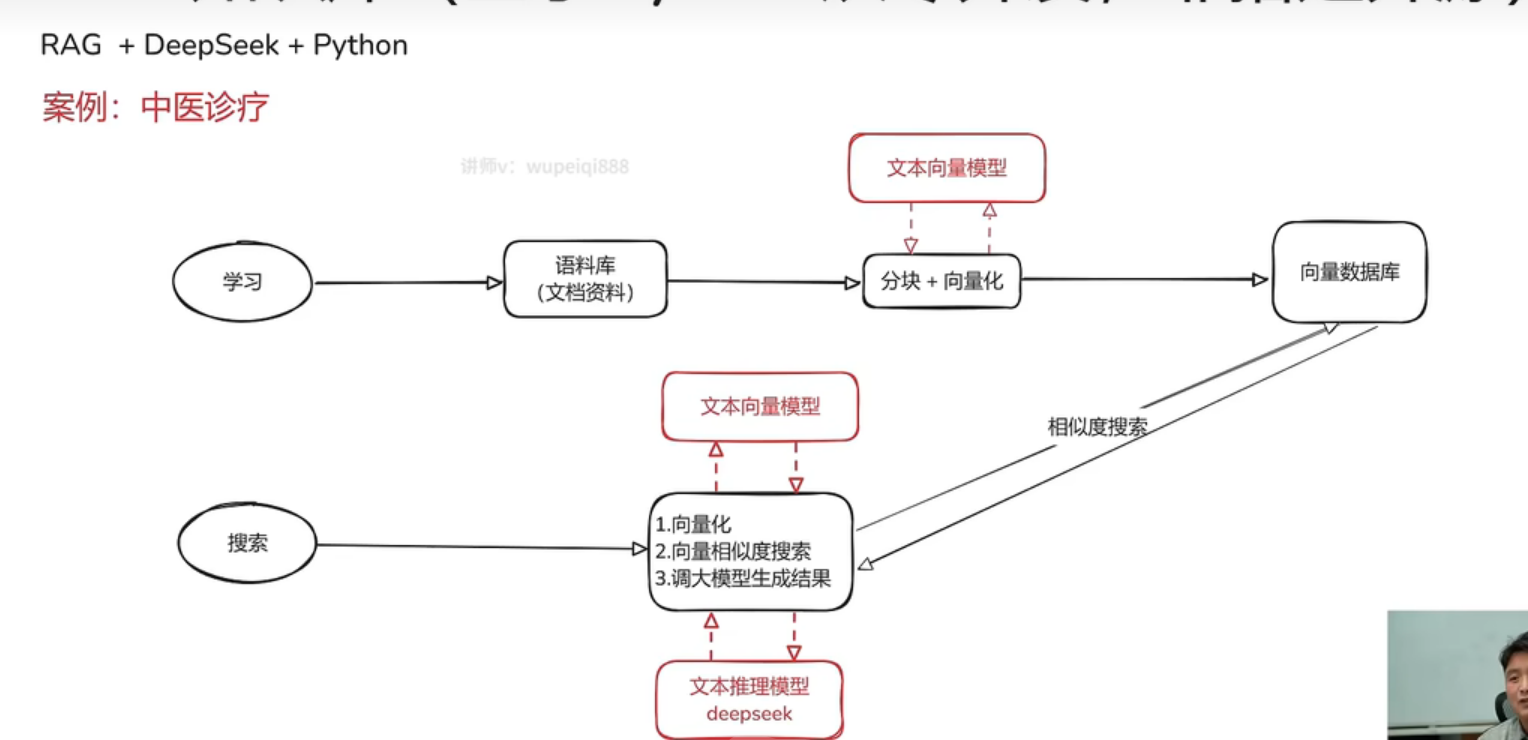
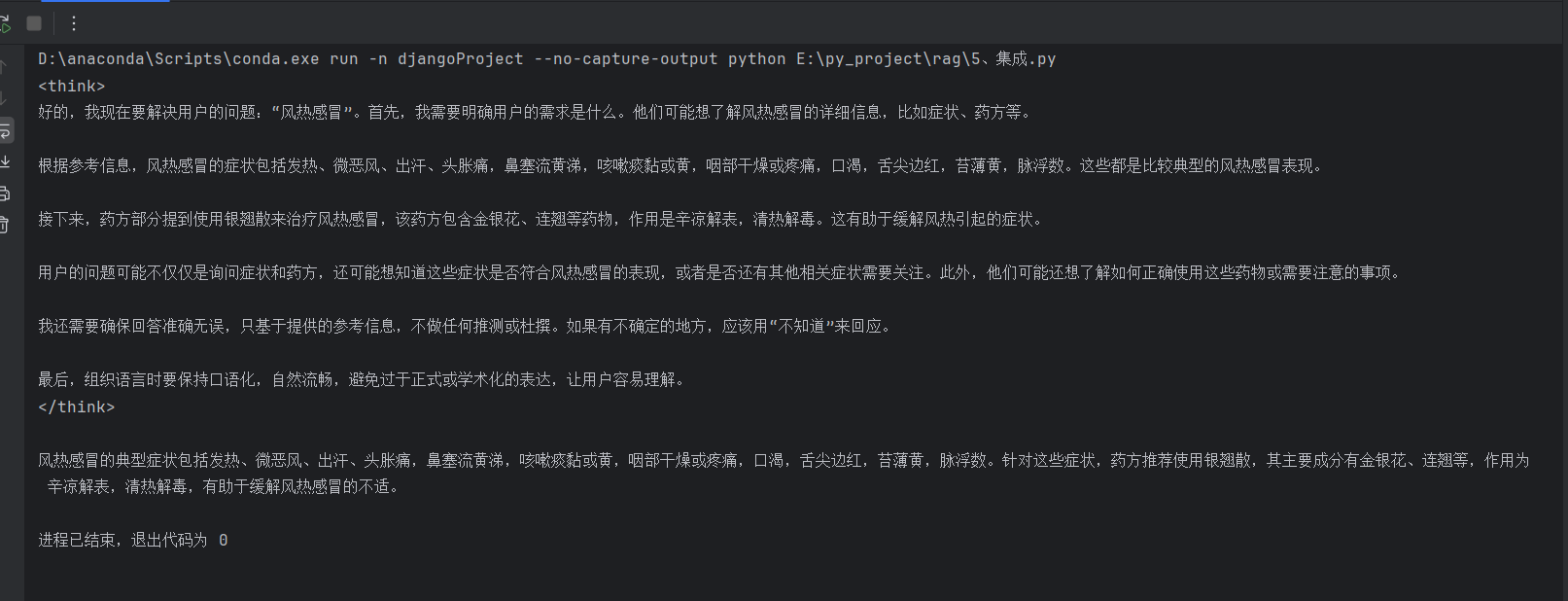
通过将资料文本向量化并存入数据库,完成向量数据库的构造,再将用户搜索内容向量化后去向量数据库搜索,搜索到最相似的文本,将搜索内容和搜索文本一起问给大语言模型,进行润色、美化。
下载文本向量模型
Ollama 是一款旨在简化在本地运行大型语言模型的工具,支持快速部署与管理,如DeepSeek等模型。它降低了技术门槛,使用户能轻松进行开发与实验,加速AI技术的应用与创新。
下载 Ollama,大家可以参考这篇, Ollama 和 大模型数据包下载到其他盘符教程:
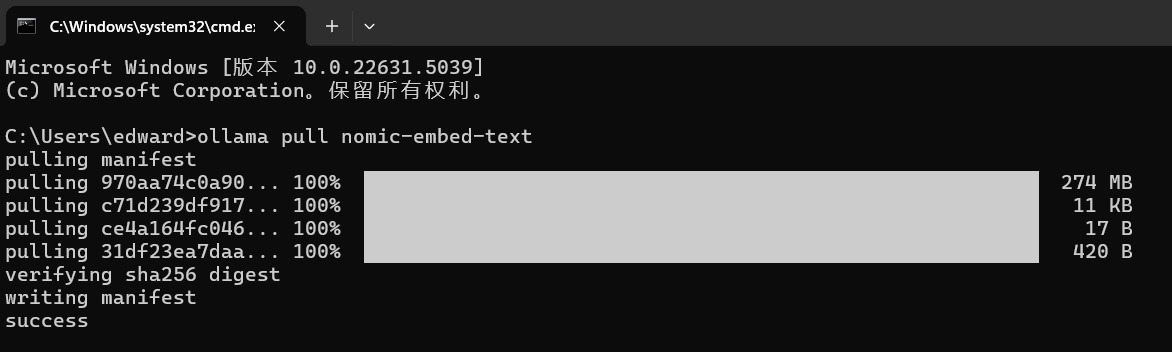
ollama pull nomic-embed-text成功下载:
模型示例数据
风寒感冒
症状:恶寒重,发热轻,无汗,头痛,肢节酸痛,鼻塞声重,或鼻痒喷嚏,时流清涕,咽痒,咳嗽,咳痰稀薄色白,口不渴或渴喜热饮,舌苔薄白而润,脉浮或浮紧。
药方:荆防败毒散。药物组成包括荆芥、防风、羌活、独活、柴胡、前胡、川芎、枳壳、茯苓、桔梗、甘草等,具有辛温解表的功效。风热感冒
症状:发热,微恶风,有汗,头胀痛,鼻塞流黄涕,咳嗽,痰黏或黄,咽燥,或咽喉红肿疼痛,口渴,舌尖边红,苔薄黄,脉浮数。
药方:银翘散。主要药物有金银花、连翘、桔梗、薄荷、竹叶、生甘草、荆芥穗、淡豆豉、牛蒡子等,能辛凉解表,清热解毒。痰湿蕴肺
症状:咳嗽反复发作,咳声重浊,痰多,因痰而嗽,痰出咳平,痰黏腻或稠厚成块,色白或带灰色,每于早晨或食后则咳甚痰多,进甘甜油腻食物加重,胸闷,脘痞,呕恶,食少,体倦,大便时溏,舌苔白腻,脉象濡滑。
药方:二陈平胃散合三子养亲汤。二陈平胃散由半夏、陈皮、茯苓、甘草、苍术、厚朴组成,三子养亲汤由紫苏子、白芥子、莱菔子组成,可燥湿化痰,理气止咳。胃痛
症状:胃痛暴作,恶寒喜暖,得温痛减,遇寒加重,口淡不渴,或喜热饮,舌淡苔薄白,脉弦紧。
药方:良附丸。由高良姜、香附组成,能温胃散寒,理气止痛。脾胃虚寒
症状:胃痛隐隐,绵绵不休,喜温喜按,空腹痛甚,得食则缓,劳累或受凉后发作或加重,泛吐清水,神疲纳呆,四肢倦怠,手足不温,大便溏薄,舌淡苔白,脉虚弱或迟缓。
药方:黄芪建中汤。药物包含黄芪、桂枝、芍药、炙甘草、生姜、大枣、饴糖,可温中健脾,和胃止痛。失眠
症状:不易入睡,多梦易醒,心悸健忘,神疲食少,伴头晕目眩,四肢倦怠,腹胀便溏,面色少华,舌淡苔薄,脉细无力。
药方:归脾汤。由白术、茯神、黄芪、龙眼肉、酸枣仁、人参、木香、炙甘草、当归、远志等组成,有补益心脾,养血安神之效。切割向量化代码
读取文件数据,按行区域切割,并放入列表,通过向本地下载的文本向量模型发送 post 请求,将切割分块的文本转换成文本向量:
import requests
import functoolsdef file_chunk_list():# 1.读取文件内容with open("E:\py_project\\rag\中医v1.txt", encoding='utf-8', mode='r') as fp:data = fp.read()# 2.根据换行切割chunk_list = data.split("\n\n")return [chunk for chunk in chunk_list if chunk]def ollama_embedding_by_api(text):res = requests.post(url="http://127.0.0.1:11434/api/embeddings",json={"model": "nomic-embed-text","prompt": text})embedding = res.json()['embedding']return embeddingdef run():chunk_list = file_chunk_list()for chunk in chunk_list:vector = ollama_embedding_by_api(chunk)print(chunk)print(vector)if __name__ == '__main__':run()向量数据库
pip install chromadb导入后创建数据库及表(理解为文件夹和excel表):
import chromadbclient = chromadb.PersistentClient(path="db/chroma_demo") # 数据库 类似于=文件夹
collection = client.get_or_create_collection(name="collection_v1") # 集合 类似于=表格添加数据:
def ollama_embedding_by_api(text):res = requests.post(url="http://127.0.0.1:11434/api/embeddings",json={"model": "nomic-embed-text","prompt": text})embedding = res.json()['embedding']return embeddingdocuments = ["风寒感冒", "寒邪客胃", "心脾两虚"]
ids = [str(uuid.uuid4()) for _ in documents]
embeddings = [ollama_embedding_by_api(i) for i in documents]# 插入数据
collection.add(ids=ids,documents=documents,embeddings=embeddings
)qs = "感冒胃疼"
qs_embedding = ollama_embedding_by_api(qs)res = collection.query(query_embeddings=[qs_embedding, ],query_texts=qs, n_results=2)
print(res)将查询文本转换成 文本向量,通过 query ,传入文本向量、文本、查询个数 n_results 三个参数,查询到数据库中前 n_results 个相似度最高的文本:

文本生成模型(推理)/ deepseek本地部署
ollama pull deepseek-r1:7b想要下载更小或者更大模型的,可以看看下表:
| DeepSeek模型版本 | 参数量 | 特点 | 适用场景 | 硬件配置 |
|---|---|---|---|---|
| DeepSeek-R1-1.5B | 1.5B | 轻量级模型,参数量少,模型规模小 | 适用于轻量级任务,如短文本生成、基础问答等 | 4核处理器、8G内存,无需显卡 |
| DeepSeek-R1-7B | 7B | 平衡型模型,性能较好,硬件需求适中 | 适合中等复杂度任务,如文案撰写、表格处理、统计分析等 | 8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或更高 |
| DeepSeek-R1-8B | 8B | 性能略强于7B模型,适合更高精度需求 | 适合需要更高精度的轻量级任务,比如代码生成、逻辑推理等 | 8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或4060 |
| DeepSeek-R1-14B | 14B | 高性能模型,擅长复杂的任务,如数学推理、代码生成 | 可处理复杂任务,如长文本生成、数据分析等 | i9-13900K或更高、32G内存,RTX 4090(24GB)或A5000 |
| DeepSeek-R1-32B | 32B | 专业级模型,性能强大,适合高精度任务 | 适合超大规模任务,如语言建模、大规模训练、金融预测等 | Xeon 8核、128GB内存或更高,2-4张A100(80GB)或更高 |
| DeepSeek-R1-70B | 70B | 顶级模型,性能最强,适合大规模计算和高复杂任务 | 适合高精度专业领域任务,比如多模态任务预处理。这些任务对硬件要求非常高,需要高端的 CPU 和显卡,适合预算充足的企业或研究机构使用 | Xeon 8核、128GB内存或更高,8张A100/H100(80GB)或更高 |
| DeepSeek-R1-671B | 671B | 超大规模模型,性能卓越,推理速度快,适合极高精度需求 | 适合国家级 / 超大规模 AI 研究,如气候建模、基因组分析等,以及通用人工智能探索 | 64核、512GB或更高,8张A100/H100 |

ollama run deepseek-r1:7b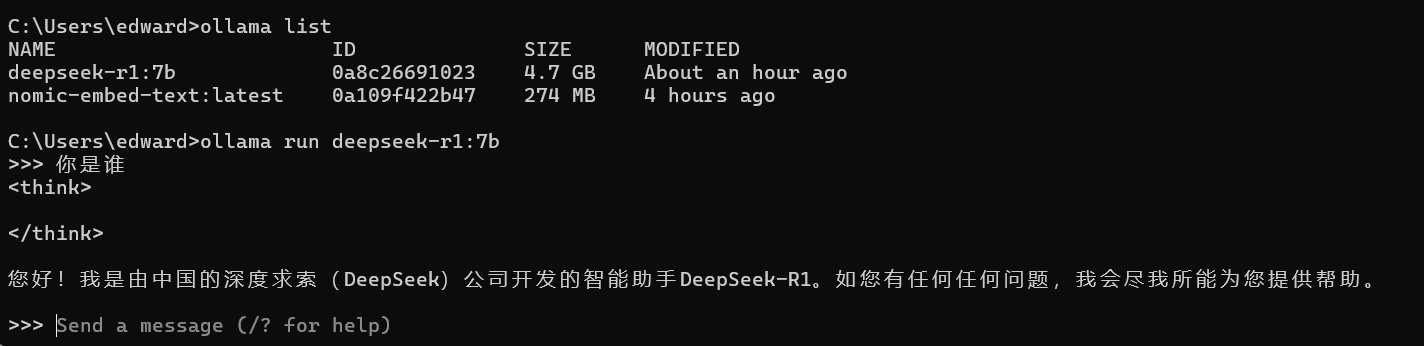
import uuid
import chromadb
import requestsdef file_chunk_list():# 1.读取文件内容with open("E:\py_project\\rag\中医v1.txt", encoding='utf-8', mode='r') as fp:data = fp.read()# 2.根据换行切割chunk_list = data.split("\n\n")return [chunk for chunk in chunk_list if chunk]def ollama_embedding_by_api(text):res = requests.post(url="http://127.0.0.1:11434/api/embeddings",json={"model": "nomic-embed-text","prompt": text})embedding = res.json()['embedding']return embeddingdef ollama_generate_by_api(prompt):response = requests.post(url="http://127.0.0.1:11434/api/generate",json={"model": "deepseek-r1:7b","prompt": prompt,"stream": False,'temperature': 0.1})res = response.json()['response']return resdef initial():client = chromadb.PersistentClient(path="db/chroma_demo")# 创建集合,先删除之前存储,再创建,防止频繁存储数据client.delete_collection("collection_v2")collection = client.get_or_create_collection(name="collection_v2")# 构造数据documents = file_chunk_list()ids = [str(uuid.uuid4()) for _ in range(len(documents))]embeddings = [ollama_embedding_by_api(text) for text in documents]# 插入数据collection.add(ids=ids,documents=documents,embeddings=embeddings)def run():# 关键字搜索qs = "风热感冒"qs_embedding = ollama_embedding_by_api(qs)client = chromadb.PersistentClient(path="db/chroma_demo")collection = client.get_collection(name="collection_v2")res = collection.query(query_embeddings=[qs_embedding, ], query_texts=qs, n_results=2)result = res["documents"][0]context = "\n".join(result)prompt = f"""你是一个中医问答机器人,任务是根据参考信息回答用户问题,如果参考信息不足以回答用户问题,请回复不知道,不要去杜撰任何信息,请用中文回答。参考信息:{context},来回答问题:{qs},"""result = ollama_generate_by_api(prompt)print(result)if __name__ == '__main__':initial()run()
注意 client.delete_collection("collection_v2") 是每次存入数据前,删除上一次存入的数据,第一次运行得先注释掉,不然会报错,因为第一次数据库中并没有数据。