做时时彩网站赚钱吗国内真正的免费建站
SAM-Decoding: 后缀自动机助力大模型推理加速!
大语言模型(LLMs)的推理效率一直是研究热点。本文介绍的SAM-Decoding方法,借助后缀自动机(Suffix Automaton,SAM)实现推测解码,在提升推理速度上成果显著,为大模型推理加速开辟新路径。快来一探究竟吧!
论文标题
SAM Decoding: Speculative Decoding via Suffix Automaton
来源
arXiv:2411.10666v3 [cs.CL] 16 Dec 2024 https://arxiv.org/abs/2411.10666
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
如今,Transformer架构的大语言模型(LLMs)在各领域广泛应用,展现出强大能力。但因其参数规模不断增大,在以逐词自回归方式生成文本时效率较低,严重影响应用体验。为提升效率,推测解码(SD)技术兴起,它能在保证解码准确性的同时降低推理延迟。SD技术分为基于模型和无模型两类,基于模型的方法常因训练和预测问题难以生成较长draft tokens;无模型的检索式SD方法虽有优势,但存在检索源单一、检索技术效率低以及适用领域窄等问题,限制了大语言模型推理效率的进一步提升,亟待新的解决方案。
研究问题
-
现有基于检索的推测解码方法检索源单一,如PLD依赖当前文本,REST依赖文本语料库,限制了检索覆盖范围。
-
检索技术效率有限,像PLD的n - gram匹配计算复杂度高,REST使用的后缀数组虽有改进但仍非最优。
-
这些方法适用领域狭窄,在总结、检索增强生成(RAG)等特定领域效果较好,但在其他领域加速效果不明显。
主要贡献
1. 创新检索源利用:利用通用文本语料库和当前文本序列作为检索源,拓宽了检索覆盖范围,增强了检索全面性。
2. 引入后缀自动机优化检索:采用后缀自动机解决最长后缀匹配问题,相比n-gram匹配,能找到更精确的匹配位置和长度,且平均时间复杂度为$ O(1) $ ,检索效率和准确性大幅提升。
3. 自适应策略集成:可与现有方法集成,根据匹配长度自适应选择draft token生成策略,在不同领域均能有效提升文本生成效率。
方法论精要
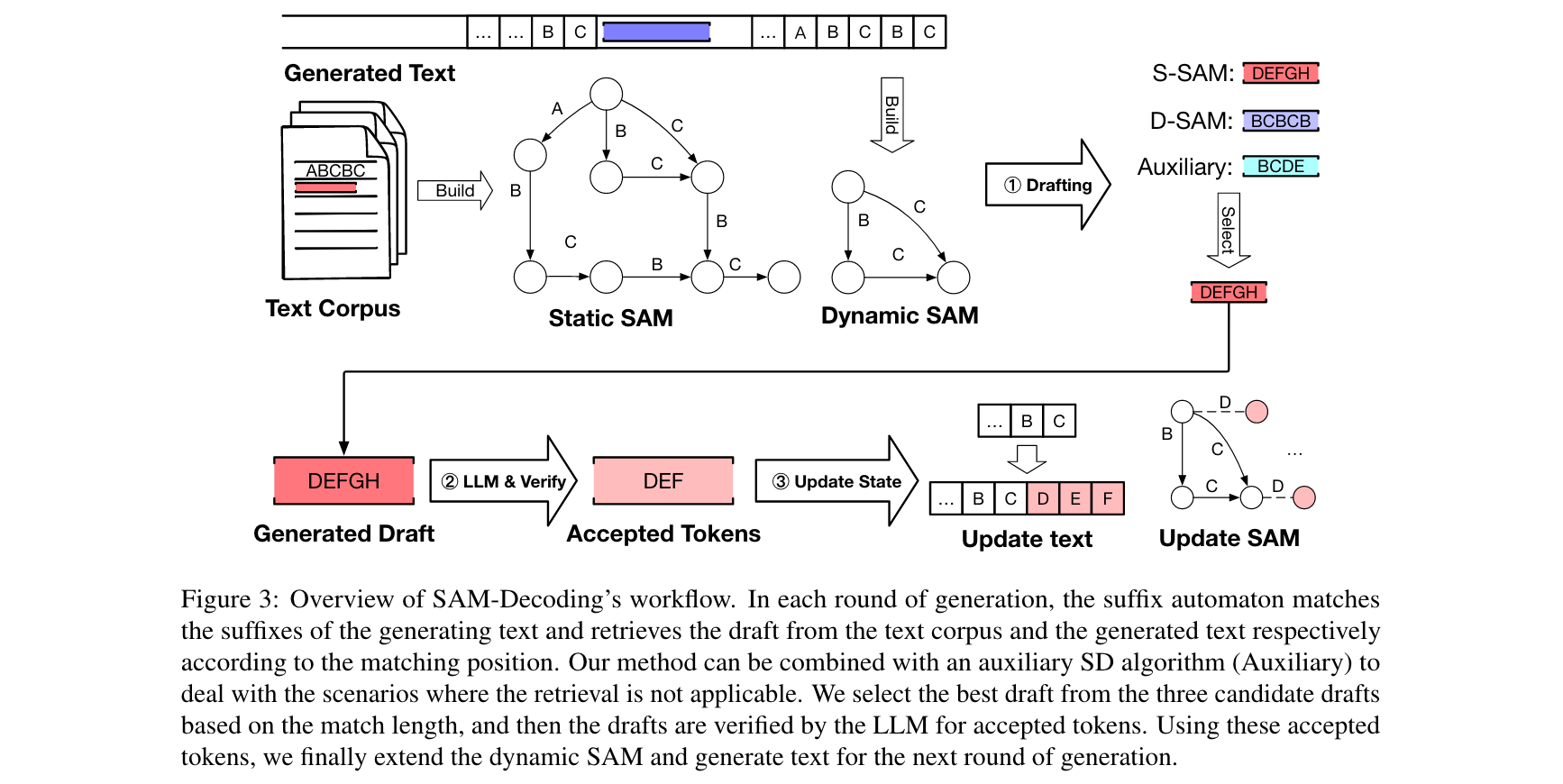
1. 核心算法/框架:SAM-Decoding方法的核心在于利用后缀自动机(Suffix Automaton,SAM)构建静态和动态后缀自动机。静态后缀自动机基于通用文本语料库离线构建,为模型提供广泛的文本参考;动态后缀自动机则依据当前文本序列(包含用户输入和已生成的文本)实时构建并扩展。在文本生成过程中,这两个自动机通过匹配文本后缀,快速检索并生成draft,为后续的验证和文本生成提供基础。
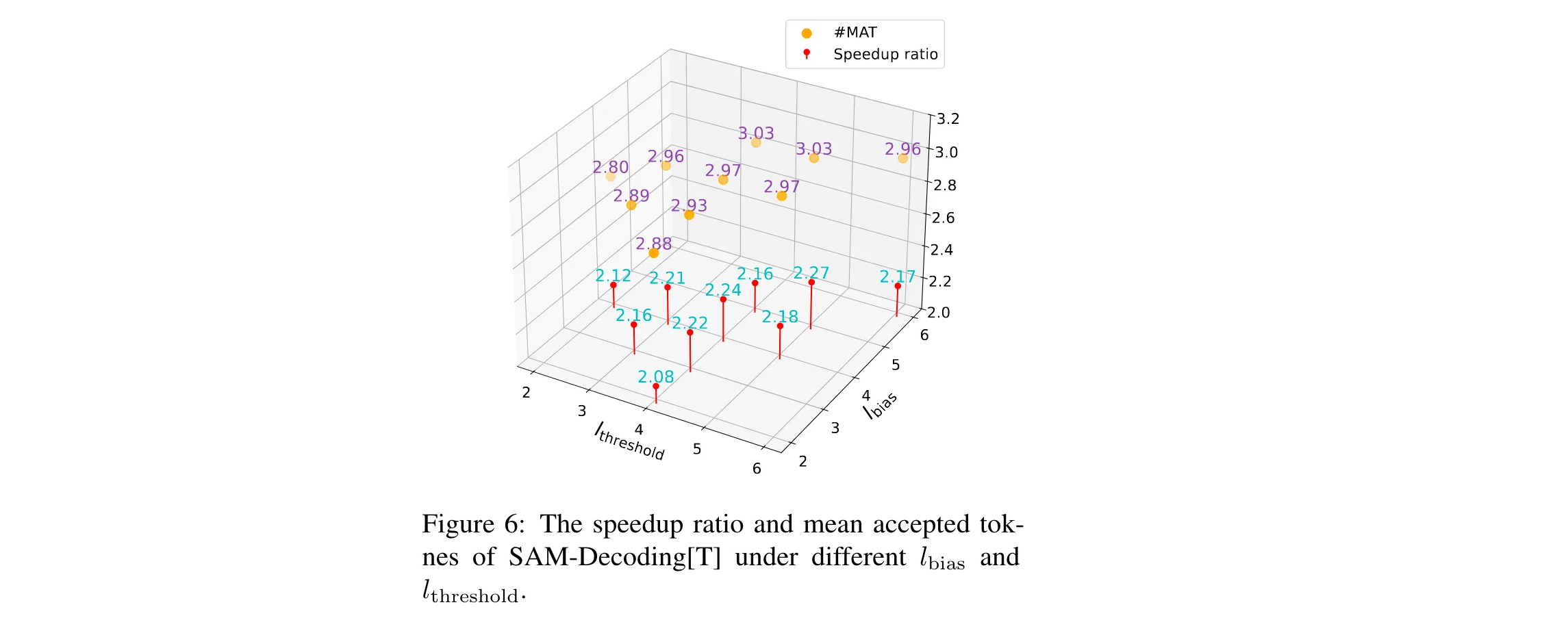
2. 关键参数设计原理:为优化draft生成策略,SAM-Decoding设置了 l b i a s l_{bias} lbias和 l t h r e s h o l d l_{threshold} lthreshold两个关键参数。 l b i a s l_{bias} lbias用于平衡从当前文本和文本语料库中生成draft的优先级。当 l b i a s l_{bias} lbias取值合理时,模型能更好地利用动态文本信息,提高draft质量。 l t h r e s h o l d l_{threshold} lthreshold则控制着后缀自动机与辅助推测解码方法之间的选择偏好。通过实验发现,将这两个参数设为5时,模型在多种任务中的表现较为出色,这一设置在不同的数据集和模型规模下都展现出了较好的适应性。
3. 创新性技术组合:该方法创新性地将后缀自动机与多种辅助推测解码技术相结合,如模型无关的Token Recycling和基于模型的EAGLE-2。在生成draft时,根据后缀匹配长度来动态选择使用自动机生成的draft还是辅助方法生成的draft。若匹配长度较长,表明从自动机获取的draft质量较高,优先使用;反之,则启用辅助方法。这种灵活的策略充分发挥了不同方法的优势,提升了整体的文本生成效率。
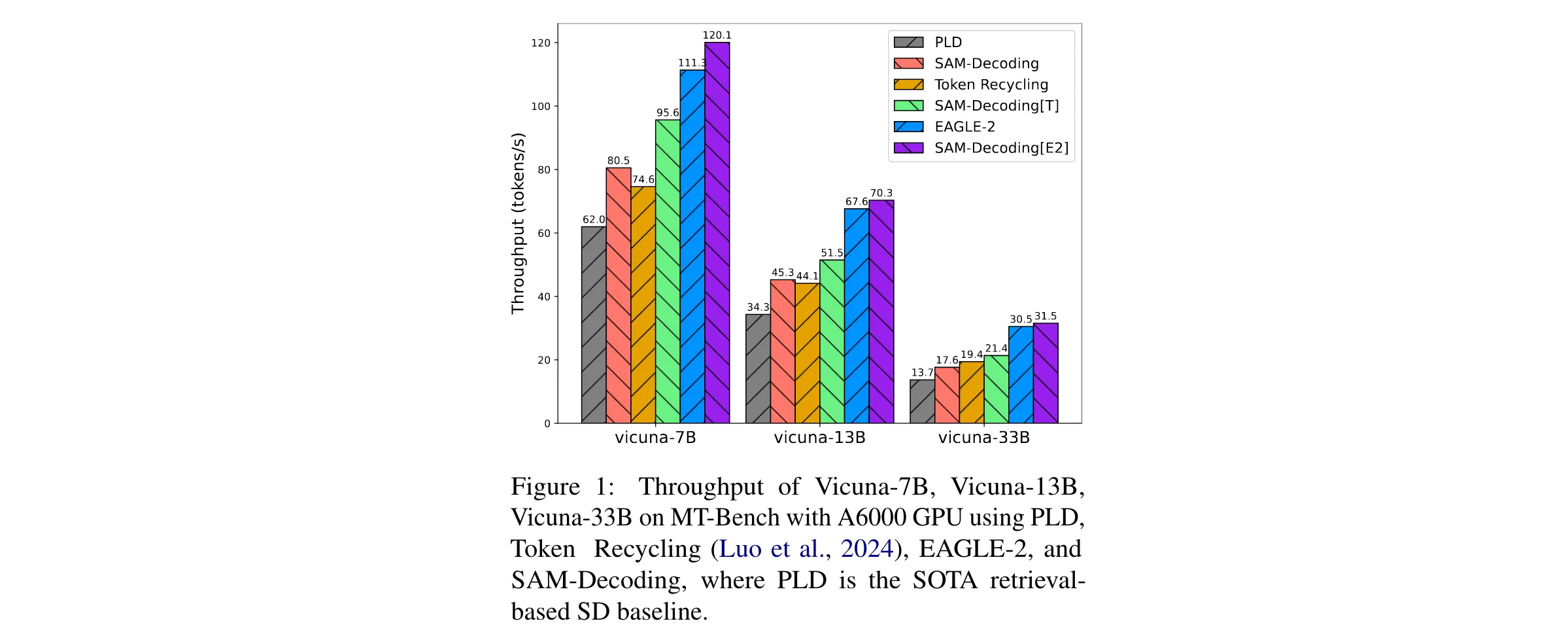
4. 实验验证方式:为全面评估SAM-Decoding的性能,研究选用了多种模型进行实验,包括Vicuna-7B-v1.3、Llama3-8B-instruct、Vicuna-13B-v1.3和Vicuna-33B-v1.3等。使用的数据集涵盖了Spec-Bench、HumanEval和HARGID等,这些数据集包含了多轮对话、翻译、总结、问答、数学推理和检索增强生成等多种任务场景。对比基线选择了当前具有代表性的方法,如模型基于的EAGLE-2、模型无关的Token Recycling以及其他检索式方法Lookahead Decoding、PIA、PLD和REST等。通过在不同模型、数据集和任务上与这些基线方法进行对比,全面且细致地评估了SAM-Decoding的性能表现。
实验洞察
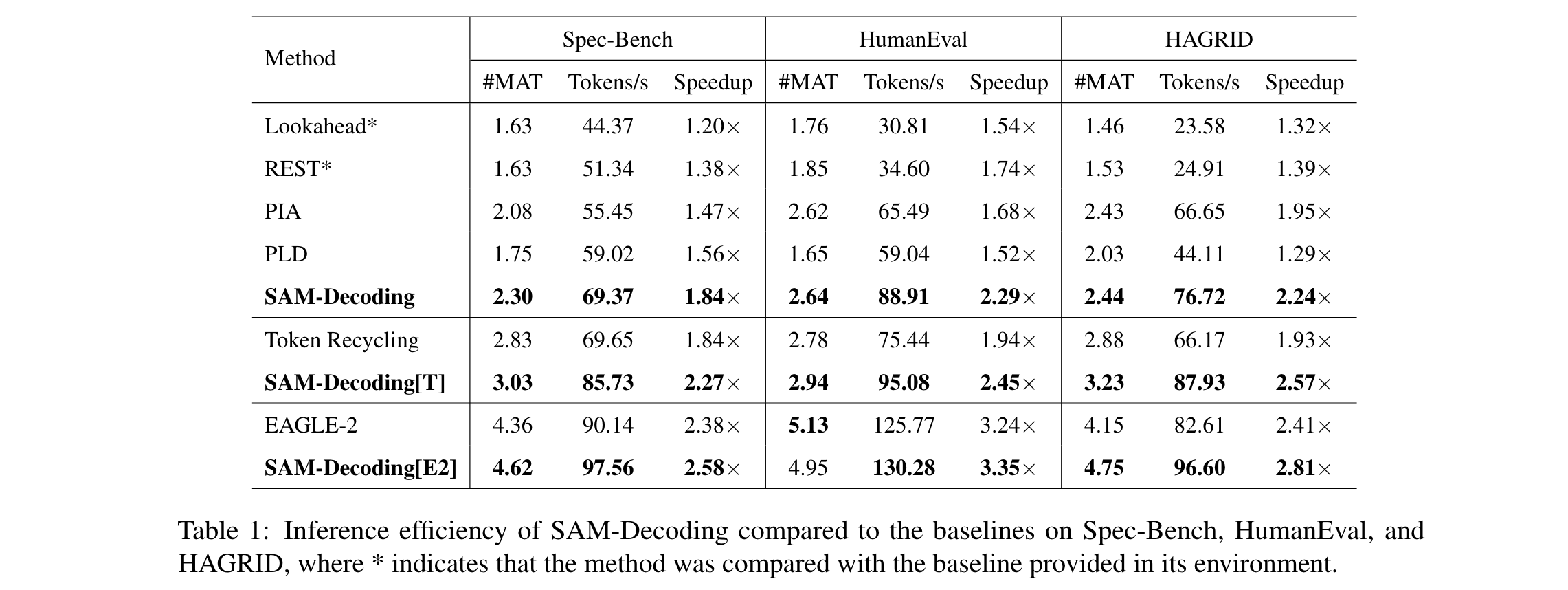
1. 性能优势:在Spec - Bench数据集上,SAM - Decoding比基于检索的基线方法快18%以上,加速比达到1.84倍;在HumanEval数据集上,加速比为2.29倍;在HAGRID数据集上,加速比为2.24倍。与EAGLE - 2结合后,在MT - Bench上针对不同LLM骨干模型,可额外实现3.28% - 11.13%的加速。
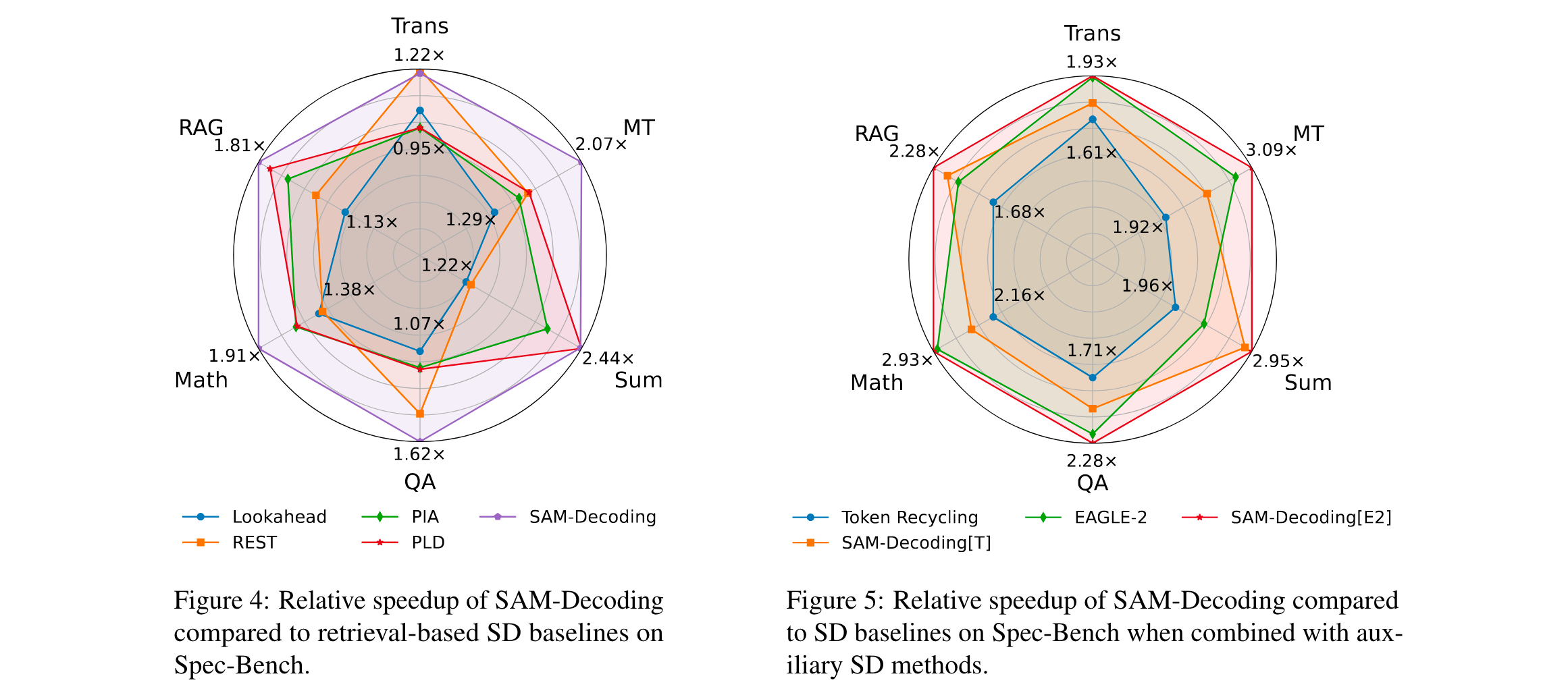
2. 效率突破:相比现有检索式方法,如PLD时间复杂度为 O ( n 2 L ) O(n^{2}L) O(n2L) ,REST时间复杂度为 O ( n 2 log L ) O(n^{2}\log L) O(n2logL) ,SAM - Decoding平均时间复杂度为 O ( 1 ) O(1) O(1) ,在draft生成速度上有显著提升。在实际实验中,不同模型和数据集下,结合SAM - Decoding的方法都能提升推理速度,如在Spec - Bench数据集上,Token Recycling结合SAM - Decoding后加速比从1.84倍提升到2.27倍。
3. 消融研究:研究 l b i a s l_{bias} lbias和 l t h r e s h o l d l_{threshold} lthreshold对推理速度的影响,发现二者在取值为5之前,MAT和加速比随其增大而增加,超过5后则下降。研究draft长度对推理速度影响时,发现draft大小为40时吞吐量最高,超过40性能会下降。去除静态或动态后缀自动机模块实验表明,两个模块都对解码加速有贡献,且动态后缀自动机作用更显著。