网站建设找a金手指珠海网站建设
题目:
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
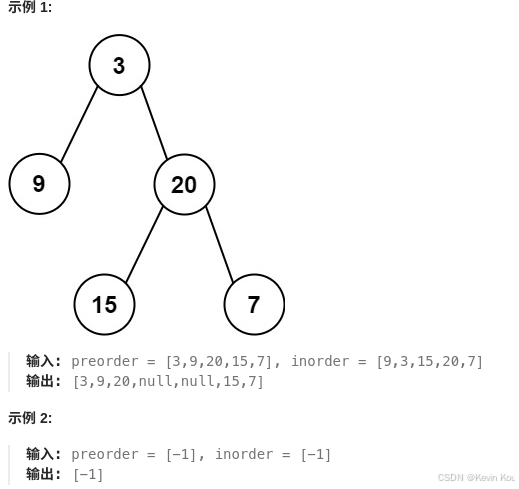
提示:
-
preorder和inorder均 无重复 元素
解法一(递归):
在「递归」地遍历某个子树的过程中,我们也是将这颗子树看成一颗全新的树。在中序遍历中定位到根节点,就可以分别知道左子树和右子树中的节点数目。由于同一颗子树的前序遍历和中序遍历的长度显然是相同的,因此我们可以对应到前序遍历的结果中。
在中序遍历中对根节点进行定位时,一种简单的方法是直接扫描整个中序遍历的结果并找出根节点,但这样做的时间复杂度较高。我们可以考虑使用哈希表来帮助我们快速地定位根节点。对于哈希表映射中的每个键值对,键表示一个元素(节点的值),值表示其在中序遍历中的出现位置。在构造二叉树的过程之前,我们可以对中序遍历的列表进行一遍扫描,就可以构造这个哈希映射。在此后构造二叉树的过程中,我们就只需要O(1)的时间对根节点进行定位了。如下为实现代码:
class Solution {
private:unordered_map<int, int> index;public:TreeNode* myBuildTree(const vector<int>& preorder, const vector<int>& inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right){if(preorder_left>preorder_right){return nullptr;}// 前序遍历中的第一个节点就是根节点int preorder_root = preorder_left;// 在中序遍历中定位根节点int inorder_root = index[preorder[preorder_root]];// 先把根节点建立起来TreeNode* root = new TreeNode(preorder[preorder_root]);// 得到左子树中的节点数目int size_left_subtree = inorder_root - inorder_left;// 递归地构造左子树,并连接到根节点// 先序遍历中【从左边界+1开始的size_left_subtree】个元素就对应了中序遍历中【从左边界开始到根节点定位-1】的元素root->left = myBuildTree(preorder, inorder, preorder_left+1, preorder_left + size_left_subtree, inorder_left, inorder_root-1);// 递归地构造右子树,并连接到根节点root->right = myBuildTree(preorder,inorder,preorder_left+1+size_left_subtree, preorder_right, inorder_root+1,inorder_right);return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {int n = preorder.size();// 构造哈希映射,帮助我们快速定位根节点for (int i = 0; i < n; ++i) {index[inorder[i]] = i;}return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);}
};时间复杂度:O(n),其中n是树中的节点个数。空间复杂度:O(n),除去返回的答案需要的O(n)空间之外,我们还需要使用O(n)的空间存储哈希映射,以及O(h)(其中h是树的高度)的空间表示递归时栈空间。这里h<n,所以总空间复杂度为O(n)。
解法二(迭代):
对于前序遍历中的任意两个连续节点u和v,根据前序遍历的流程,我们可以直到u和v只有两种可能的关系:
1、v是u的左儿子。这是因此在遍历之后,下一个遍历的节点就是u的左儿子,即v;
2、u没有左儿子,并且v是u的某个祖先节点(或者u本身)的右儿子,如果u没有左儿子,那么下一个遍历的节点就是u的右儿子。如果u没有右儿子,我们就会向上回溯,直到遇到第一个有右儿子(且u不在它的右儿子的子树中)的节点ua,那么v就是ua的右儿子。

我们用一个栈stack来维护「当前节点的所有还没有考虑过右儿子的祖先节点」,栈顶就是当前节点。也就是说,只有在栈中的节点才可能连接一个新的右儿子。同时,我们用一个指针index指向中序遍历的某个位置,初始值为0。index对应的节点是「当前节点不断往左走达到的最终节点」,这也是符合中序遍历的,它的作用在下面的过程中会有所体现。
首先我们将根节点3入栈,再初始化index所指向的节点为4,随后对于前序遍历中的每个节点,我们依次判断它是栈顶节点的左儿子,还是栈中某个节点的右儿子。
我们遍历9。9一定是栈顶节点3的左儿子。我们使用反证法,假设9是3的右儿子,那么3没有左儿子,index应该恰好指向3,但实际上为4,因此产生了矛盾。所以我们将9作为3的左儿子,并将9入栈。
stack = [3, 9]
index -> inorder[0] = 4
我们遍历8,5和4。同理可得它们都是上一个节点(栈顶节点)的左儿子,所以它们会依次入栈。
stack = [3, 9, 8, 5, 4]
index -> inorder[0] = 4
我们遍历10,这时情况就不一样了。我们发现index恰好指向当前的栈顶节点4,也就是说4没有左儿子,那么10必须为栈中某个节点的右儿子。那么如何找到这个节点呢?栈中的节点的顺序和它们在前序遍历中出现的顺序是一致的,而且每一个节点的右儿子都还没有被遍历过,那么这些节点的顺序和它们在中序遍历中出现的顺序一定是相反的。
这是因为栈中的任意两个相邻的节点,前者都是后者的某个祖先。并且我们知道,栈中的任意一个节点的右儿子还没有被遍历过,说明后者一定是前者左儿子的子树中的节点,那么后者就先于前者出现在中序遍历中。
因此我们可以把index不断向右移动,并与栈顶节点进行比较。如果index对应的元素恰好等于栈顶节点,那么说明我们在中序遍历中找到了栈顶节点,所以将index增加1并弹出栈顶节点,直到index对应的元素不等于栈顶节点。按照这样的过程,我们弹出的最后一个节点x就是10的双亲节点,这是因为10出现在了x与x在栈中的下一个节点的中序遍历之间,因此10就是x的右儿子。
回到我们的例子,我们会依次从栈顶弹出4,5和8,并且将index向右移动了三次。我们将10作为最后弹出的节点8的右儿子,并将10入栈。
stack = [3, 9, 10]
index -> inorder[3] = 10
我们遍历20。同理,index恰好指向当前栈顶节点10,那么我们会依次从栈顶弹出10,9和3,并且将index向右移动了三次。我们将20作为最后弹出的节点3的右儿子,并将20入栈。
stack = [20]
index -> inorder[6] = 15
我们遍历15,将15作为栈顶节点20的左儿子,并将15入栈。
stack = [20, 15]
index -> inorder[6] = 15
我们遍历7。index恰好指向当前栈顶节点15,那么我们会依次从栈顶弹出15和20,并且将index向右移动了两次。我们将7作为最后弹出的节点20的右儿子,并将7入栈。
stack = [7]
index -> inorder[8] = 7
此时遍历结束,我们就构造出了正确的二叉树。我们归纳出上述例子中的算法流程:
我们用一个栈和一个指针辅助进行二叉树的构造。初始时栈中存放了根节点(前序遍历的第一个节点),指针指向中序遍历的第一个节点;
我们依次枚举前序遍历中除了第一个节点以外的每个节点。如果index恰好指向栈顶节点,那么我们不断地弹出栈顶节点并向右移动index,并将当前节点作为最后一个弹出的节点的右儿子;如果index和栈顶节点不同,我们将当前节点作为栈顶节点的左儿子;
无论是哪一种情况,我们最后都将当前的节点入栈。
最后得到的二叉树即为答案。如下为实现代码:
class Solution {
public:TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {if (!preorder.size()) {return nullptr;}TreeNode* root = new TreeNode(preorder[0]);stack<TreeNode*> stk;stk.push(root);int inorderIndex = 0;for (int i = 1; i < preorder.size(); ++i) {int preorderVal = preorder[i];TreeNode* node = stk.top();if (node->val != inorder[inorderIndex]) {node->left = new TreeNode(preorderVal);stk.push(node->left);}else {while (!stk.empty() && stk.top()->val == inorder[inorderIndex]) {node = stk.top();stk.pop();++inorderIndex;}node->right = new TreeNode(preorderVal);stk.push(node->right);}}return root;}
};笔者小记:
1、掌握二叉树前序遍历和中序遍历的过程;
2、掌握二叉树构建时,通过递归和迭代的方式添加二叉树新节点的代码书写思路。
3、通过递归方式添加二叉树新节点时有两种方式,第一种:通过TreeNode*& root,引用的方式,root=new TreeNode(value),以及递归调用root->left和root->right传入到void的递归嵌套函数中,并返回return。第二种:return返回值的形式,root->left=递归嵌套返回值,root->rigth=递归嵌套函数返回值,其中嵌套函数返回值类型为TreeNode。
4、前序遍历和中序遍历都可以通过栈来实现迭代方法,栈的作用是在遍历过程中显示地模拟递归调用的行为(显示的递归栈)。