市场部做网站工作职责seo算法是什么
1.机器学习
2.机器学习模型
3.模型评价方法
4.如何选择合适的模型
介绍
机器学习(Machine Learning, ML)是人工智能(AI)的核心分支,致力于通过数据和算法让计算机系统自动“学习”并改进性能,而无需显式编程。前一篇文章机器学习前言1介绍了机器学习和统计学关系、机器学习的发展、机器学习与深度学习的相同点与不同点、机器学习和深度学习优缺点。链接机器学习前言1,这篇主要介绍机器学习模型和算法方面,几种不同内容分类。常听到说机器学习是做预测和分类,其实还有很多其他内容,比如迁移学习、强化学习等。这里我们主要是以类型划分,具体内容可以参考链接深度学习之卷积神经网络CNN详细,这篇主要以说明深度学习与其他类型之间联系,比如说监督学习、半监督学习、无监督学习等,图展示如下: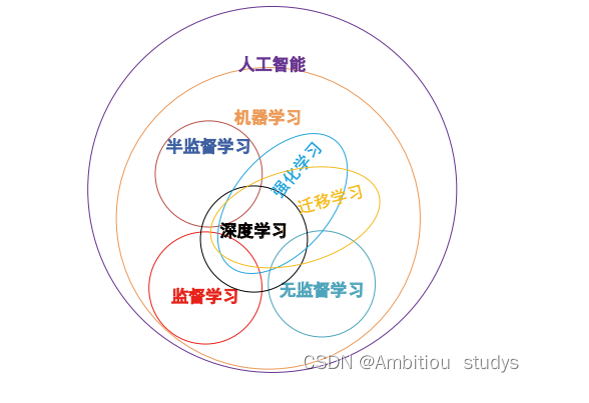
如果想了解更多深度学习模型文献可参考这链接卷积神经网络CNN进步史之分类领域小论文文章总结帮助初学者找文献
一、机器学习
1.基本定义
从数据中自动发现模式(规律),并利用这些模式进行预测或决策。核心思想是通过算法从历史数据中学习模型(数学模型或规则),泛化到新数据。机器学习算法是让计算机从数据中学习规律并做出预测或决策的核心工具。不同的算法适用于不同的问题类型(分类、回归、聚类等)和数据特征(线性/非线性、结构化/非结构化)。
2.步骤
(1)数据准备:数据清洗(处理缺失值、异常值)、特征工程(提取/选择有效特征)。
(2)模型选择:根据任务选择算法(如分类用随机森林,图像识别用CNN)。
(3)训练与评估:划分训练集/测试集,用交叉验证防止过拟合,评估指标(准确率、F1分数、RMSE等)。
(4)部署与迭代:模型上线后持续监控性能,反馈优化(如A/B测试)。
3.常用算法
(1)传统方法:逻辑回归、随机森林、梯度提升树(XGBoost)。
(2)深度学习:神经网络(CNN用于图像,RNN/LSTM用于时序数据,Transformer用于NLP)。
(3)新兴方向:图神经网络(GNN)、元学习(Learning to Learn)。
4.应用
(1)计算机视觉:人脸识别、医学影像分析。
(2)自然语言处理(NLP):机器翻译、聊天机器人。
(3)推荐系统:电商商品推荐(如协同过滤)。
(4)金融:信用评分、欺诈检测。
(5)工业:预测性维护、质量控制。
5.问题
(1)数据质量:噪声、偏差、数据量不足。
(2)过拟合:模型在训练集表现好,但泛化能力差。
(3)可解释性:深度学习模型常被视为“黑箱”。
(4)伦理问题:隐私、算法偏见。
二、机器学习模型
这里将根据三种不同的学习方式、结构和任务进行分类。
1.按学习方式分类
| 类型 | 特点 | 典型算法 |
|---|---|---|
| 监督学习模型 | 使用带标签数据训练,预测目标变量 | 线性回归、逻辑回归、SVM、决策树、神经网络 |
| 无监督学习模型 | 数据无标签,用于发现隐藏结构 | K-Means、DBSCAN、PCA、GAN(生成对抗网络) |
| 半监督学习模型 | 结合少量标签数据和大量无标签数据 | Label Propagation、Self-Training |
| 自监督学习模型 | 自动生成标签(如对比学习) | SimCLR、BERT(部分任务) |
| 强化学习模型 | 通过环境交互+奖励机制学习最优策略 | Q-Learning、Deep Q-Network (DQN)、Policy Gradients |
2.按模型结构分类
| 类型 | 特点 | 典型算法 |
|---|---|---|
| 线性模型 | 输入特征的线性组合 | 线性回归、逻辑回归、LDA |
| 非线性模型 | 捕捉复杂非线性关系 | 决策树、SVM(核方法)、神经网络 |
| 概率模型 | 基于概率分布进行预测 | 朴素贝叶斯、隐马尔可夫模型(HMM) |
| 集成模型 | 结合多个弱模型提升性能 | 随机森林、XGBoost、AdaBoost |
| 深度学习模型 | 多层神经网络,自动特征提取 | CNN(图像)、RNN/LSTM(时序)、Transformer(NLP) |
3.按任务类型分类
| 任务 | 目标 | 典型模型 |
|---|---|---|
| 回归(Regression) | 预测连续值(如房价) | 线性回归、XGBoost、神经网络 |
| 分类(Classification) | 预测离散类别(如垃圾邮件检测) | 逻辑回归、SVM、随机森林 |
| 聚类(Clustering) | 无监督数据分组(如用户分群) | K-Means、层次聚类、GMM |
| 降维(Dimensionality Reduction) | 减少特征数量,保留关键信息 | PCA、t-SNE、Autoencoder |
| 生成模型(Generative Model) | 生成新数据(如图像、文本) | GAN、VAE、Diffusion Models |
三、模型评价方法
1.分类任务
| 指标 | 说明 |
|---|---|
| 准确率(Accuracy) | 正确预测比例(适用于平衡数据) |
| 精确率(Precision) | 预测为正的样本中实际为正的比例 |
| 召回率(Recall) | 实际为正的样本中被正确预测的比例 |
| F1-Score | 精确率和召回率的调和平均 |
| AUC-ROC | 衡量分类器区分正负样本的能力 |
2.回归任务
| 指标 | 说明 |
|---|---|
| 均方误差(MSE) | 预测值与真实值的平方误差 |
| 均方根误差(RMSE) | MSE的平方根 |
| R²(决定系数) | 模型解释的方差比例 |
3.聚类任务
| 指标 | 说明 |
|---|---|
| 轮廓系数(Silhouette Score) | 衡量聚类紧密度和分离度 |
| Calinski-Harabasz指数 | 类内方差 vs 类间方差 |
四、如何选择合适的模型
(1)问题类型(分类/回归/聚类)决定模型类别。
(2)数据规模:小数据、大数据
(3)可解释性需求:高解释性、低解释性
(4)计算资源:轻量级、高计算需求