招商网网站建设方案网络市场调研的五个步骤
该博客将详细介绍Java当中Map和Set是什么、Map和Set是怎么工作的、Map和Set的实现模拟以及Map和Set的使用说明。我们的重点在工作原理以及实现模拟的讲解,废话不多说,我们开始吧!
ps:别担心,其实原理很简单、朴素,不用怕看不懂,慢慢理解就好了!
一.Map和Set是什么
1.Map
Map是一种用键值对(Key-Value)存储数据的数据结构。其中value是可以重复的数据,而key则不可重复,一个键只能对应一个值。
可以这么理解,Map是一种特殊的数组,key就是他的索引,value则是他的值。
2.Set
Set则是一种用纯Key模型来维护变量唯一性的数据结构,即一个Set中的所有对象都是唯一的。
3.分类
- 基于搜索树:TreeMap、TreeSet
- 基于Hash表(稍后讲解):HashMap、HashSet
4.设计初衷
Map的设计初衷:为了存储关联性数据,例如,我们根据id来快速锁定对象、存储苹果这一对象的数量......
Set的设计初衷:存在性检查,例如,查找一篇文章中没有出现哪些单词、查找用户是否存在......
使用以上数据结构时,它们都是相当高效的,而传统遍历则要花更多时间。
二.Map和Set是怎么工作的
Set是基于Map的,所以我们先讲Map,二者都是差不多的,另外,我们的重点在hash表的原理和理解上,TreeMap和TreeSet无论是难度还是使用频率都不及HashMap和HashSet的。
1.基于红黑树的Map
我们来简单了解下红黑树,红黑树其实就是用特殊规则(红边和黑边)实现的几乎完全平衡二叉树,即根节点的左右两边节点数几乎相等,而Map的节点就按顺序存储在这一树中:

当我们要查找key的value时,例如key = 4,那他就会进行二分查找,直到找到key = 4的节点,然后返回其value。
其实和二分查找树类似。
添加、删除元素其实和二分查找树的添加、删除元素类似,涉及到节点的比较以及上浮和下沉,不过多介绍了。
重点理解他是基于有序的、平衡的二叉树实现的即可。
2.基于Hash表实现的Map
我们不急介绍hash表和hash值(HashCode),先回顾一下Map的设计初衷,根据key来快速锁定对象,像搜索树那样的实现它的时间复杂度终究是O(log2N),有没有办法把复杂度降到O(1)呢?
有的兄弟,有的!
要是我们能像数组那样,把key转换成索引不就行了吗,没错,hash地址就是这个索引,而hash地址要通过hash函数计算得来,其参数就是hash值,而这个列表就是hash表(散列表)。
不急,可能有点绕,我们来理一下,
Map建立原理如下:
我们的测试类为people,测试用例为[[Alice,20],[Bob,20],[Peter,21],[Lee,19],[Gen,25],[Xing,20]]
step1:hash值的生成
Java为每个创建的对象都设定了一个hash值,这是对象自带的属性,如果print对象时没有重写toString方法,那就会输出对象的Hash值:


例如我们的例子:
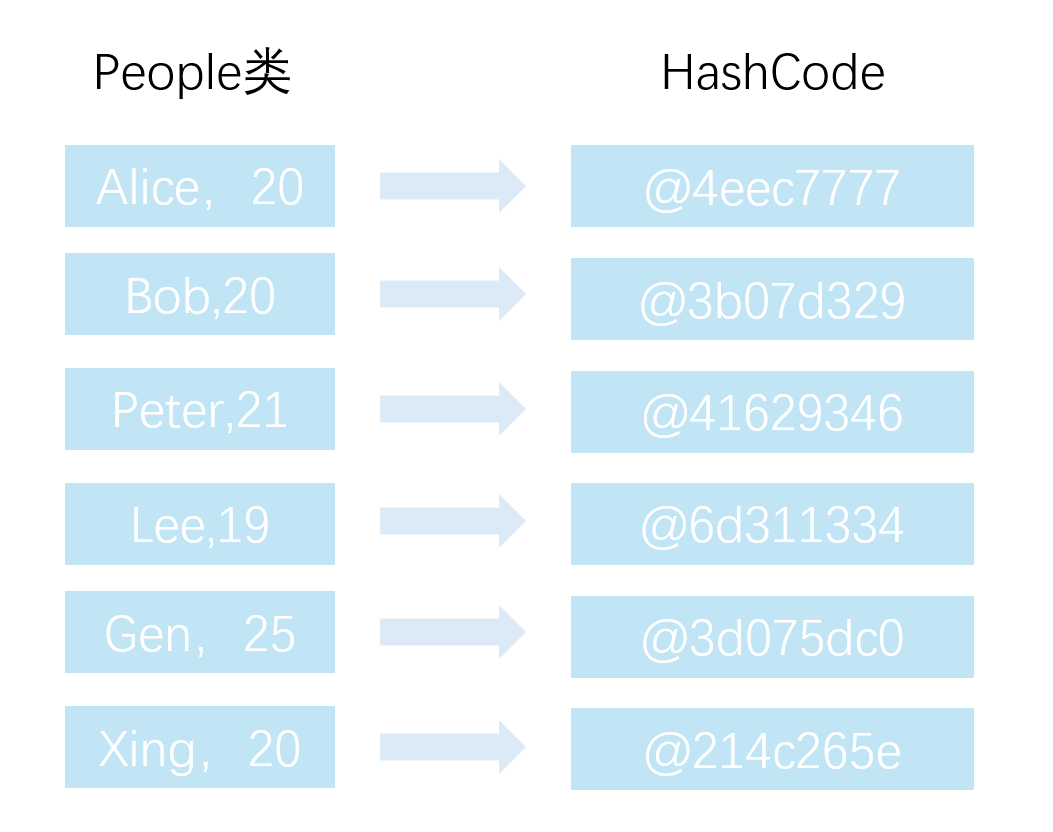
很多人以前觉得是c/c++中的地址,其实是不一样的哈。
这个值是一个16进制的32位数,理论上是完全够用的,能表示42亿个不同对象的hash值。
step2:通过hash函数建立映射关系
我们的目的是把hash值转换成数组的索引,例如通过某些运算(如整除数组容量取余),得出的索引我们称为hash地址,“某些运算”我们称为hash函数,存储的特殊数组成为hash表。
例如以上的@4eec7777,我们有个10容量的数组(哈希表),整除取余运算(哈希函数)后为7(哈希地址),于是映射关系就确认了。


但是,很明显有大问题啊!!!
假如我们有个新同学Liu,hashcode为@6dfa4577,那他的hash地址不就重叠了吗?

是的,这一现象叫哈希冲突(哈希碰撞),这是无法避免的,我们要做的就是设计合理的算法(哈希函数)来让冲突发生的可能性降到最低,并且想办法就算冲突也能正常访问存储数据。
于是大佬们想了很多措施:
其一,引入负载因子α,通过控制负载因子在合理的范围内,降低冲突发生(负载因子的概念其实很简单:α = 表中元素数/总容量,越高表示冲突率越大),如上,负载因子为0.7;
其二,改善哈希表的存储结构,引入哈希桶(HashBuck)的概念,即把数组的单元格改造为正确存放相同hash地址的"桶",实际上用到的是数组+链表的方式,把节点改造为链式,哈希地址相同的链接到一起;
其三,链表的自动树化,为了保证查询速度,当哈希值相同的节点链接程度过大,通常是8层链接,那么就会把链表转换为平衡的二叉树(红黑树);
其四,自动扩容,当α过高并且有节点的层数过高,那么就会自动扩容,并且完全对所有节点重排列,即重新确定hash地址,重新建立链接关系。
......
真实的Map的实现肯定要复杂得多,但是这些就是核心思想了。
请看改善后的存储结构:

step3:愉快地查询
以上问题解决好后,就是愉快的、令人兴奋的、查询时间复杂度近似为O(1)的高效数据结构了!我们只需要使用key就可以瞬间找到对应的值了!
Set其实就是去掉了节点中的value属性,其他内核基本相同。
三.HashMap的模拟实现
你已经简单了解了HashMap的原理了,现在来实现一个HashMap吧!(doge.jpg)
1.明确思路
我们要什么?
- 一个HashMap的模拟实现的类(忽略泛型,便于理解,用int存储key和value)
我们的类中要有那些属性?
- 一个数组
- 一个节点类(内部类实现,写在外部更好,此处方便演示)
- 默认初始容量
- 当前容量
- 元素数量
- 负载因子α
- 扩容阈值
我们要什么样的数组?
- 能动态扩容
- 存储的元素为链表的头结点
我们要什么的节点?
- 含next指向下一个节点
- 存储了key和value
我们要那些方法?
- 两个构造方法,使用默认容量/自定义容量
- 哈希函数(直接对哈希值取模)
- 自动扩容机制
- 插入
- 查找
- 删除
2.属性及构造方法
public class MyHashMap {private static class Node {int key;int value;Node next;public Node(int key, int value) {this.key = key;this.value = value;}}private Node[] table;private int capacity; // 当前容量private int size = 0; // 元素数量private final float loadFactor = 0.75f; // 负载因子private int threshold; // 扩容阈值(capacity * loadFactor)//当 size >= threshold时扩容// 默认初始容量为8public MyHashMap() {this(8);}// 自定义初始容量public MyHashMap(int initialCapacity) {capacity = initialCapacity;threshold = (int)(capacity * loadFactor);table = new Node[capacity];}......3.哈希函数
private int hash(int key) {return key % capacity;
}4.扩容并全部重排序
private void resize() {int newCapacity = capacity * 2;Node[] newTable = new Node[newCapacity];// 遍历旧表所有节点for (int i = 0; i < capacity; i++) {Node Node = table[i];while (Node != null) {Node next = Node.next; // 保存下一个节点int newIndex = Node.hash(); // 重新计算哈希// 头插法插入新表Node.next = newTable[newIndex];newTable[newIndex] = Node;Node = next;}}// 更新容量和阈值table = newTable;capacity = newCapacity;threshold = (int)(capacity * loadFactor);
}5.插入
public void put(int key, int value) {// 检查扩容if (size >= threshold) {resize();}int index = hash(key);Node Node = table[index];// 空桶直接插入if (Node == null) {table[index] = new Node(key, value);size++;return;}// 遍历链表查找KeyNode prev = null;while (Node != null) {if (Node.key == key) {Node.value = value; // 更新值return;}prev = Node;Node = Node.next;}// 添加到链表末尾prev.next = new Node(key, value);size++;
}6.查找
public int get(int key) {int index = hash(key);Node Node = table[index];while (Node != null) {if (Node.key == key) {return Node.value;}Node = Node.next;}return -1;
}7.删除
public void remove(int key) {int index = hash(key);Node Node = table[index];Node prev = null;while (Node != null) {if (Node.key == key) {if (prev == null) {table[index] = Node.next; // 删除头节点} else {prev.next = Node.next; // 删除中间或尾节点}size--;return;}prev = Node;Node = Node.next;}
}8.完整代码及测试用例
public class MyHashMap {private static class Node {int key;int value;Node next;public Node(int key, int value) {this.key = key;this.value = value;}}private Node[] table;private int capacity; // 当前容量private int size = 0; // 元素数量private final float loadFactor = 0.75f; // 负载因子private int threshold; // 扩容阈值(capacity * loadFactor)// 默认初始容量为8public MyHashMap() {this(8);}// 自定义初始容量public MyHashMap(int initialCapacity) {capacity = initialCapacity;threshold = (int)(capacity * loadFactor);table = new Node[capacity];}/*** 哈希函数(直接取模)*/private int hash(int key) {return key % capacity;}/*** 插入键值对(自动扩容)*/public void put(int key, int value) {// 检查扩容if (size >= threshold) {resize();}int index = hash(key);Node Node = table[index];// 空桶直接插入if (Node == null) {table[index] = new Node(key, value);size++;return;}// 遍历链表查找KeyNode prev = null;while (Node != null) {if (Node.key == key) {Node.value = value; // 更新值return;}prev = Node;Node = Node.next;}// 添加到链表末尾prev.next = new Node(key, value);size++;}/*** 扩容为原容量的两倍*/private void resize() {int newCapacity = capacity * 2;Node[] newTable = new Node[newCapacity];// 遍历旧表所有节点for (int i = 0; i < capacity; i++) {Node Node = table[i];while (Node != null) {Node next = Node.next; // 保存下一个节点int newIndex = Node.key % newCapacity; // 重新计算哈希// 头插法插入新表Node.next = newTable[newIndex];newTable[newIndex] = Node;Node = next;}}// 更新容量和阈值table = newTable;capacity = newCapacity;threshold = (int)(capacity * loadFactor);}/*** 获取值(不存在返回-1)*/public int get(int key) {int index = hash(key);Node Node = table[index];while (Node != null) {if (Node.key == key) {return Node.value;}Node = Node.next;}return -1;}public void remove(int key) {int index = hash(key);Node Node = table[index];Node prev = null;while (Node != null) {if (Node.key == key) {if (prev == null) {table[index] = Node.next; // 删除头节点} else {prev.next = Node.next; // 删除中间或尾节点}size--;return;}prev = Node;Node = Node.next;}}// 测试扩容public static void main(String[] args) {MyHashMap map = new MyHashMap(4); // 初始容量4,阈值3map.put(1, 10);map.put(2, 20);map.put(3, 30); // size=3,达到阈值3,触发扩容System.out.println("扩容前容量: 4");System.out.println("Key 1: " + map.get(1)); // 10System.out.println("Key 2: " + map.get(2)); // 20map.put(4, 40); // 触发扩容,容量变为8System.out.println("\n扩容后容量: 8");System.out.println("Key 4: " + map.get(4)); // 40}
}四.Map与Set的使用
Map请参考以下代码:
import java.util.HashMap;
import java.util.Map;public class MapExample {public static void main(String[] args) {// 1. 创建MapMap<String, Integer> map = new HashMap<>();// 2. 添加元素map.put("Apple", 10);map.put("Banana", 5);map.put("Orange", 8);//map.put("Orange", 9);再次添加则覆盖System.out.println("初始化Map: " + map); // {Apple=10, Banana=5, Orange=8}// 3. 获取元素int appleCount = map.get("Apple");System.out.println("Apple的数量: " + appleCount); // 10// 4. 检查Key是否存在boolean hasMango = map.containsKey("Mango");System.out.println("是否包含Mango? " + hasMango); // false// 5. 检查Value是否存在boolean hasCount5 = map.containsValue(5);System.out.println("是否有数量为5的商品? " + hasCount5); // true// 6. 删除元素map.remove("Banana");System.out.println("删除Banana后的Map: " + map); // {Apple=10, Orange=8}// 7. 获取所有Key和ValueSystem.out.println("所有水果: " + map.keySet()); // [Apple, Orange]System.out.println("所有数量: " + map.values()); // [10, 8]// 8. 遍历Map方式1:entrySet(推荐)System.out.println("\n遍历方式1: entrySet");for (Map.Entry<String, Integer> entry : map.entrySet()) {System.out.println(entry.getKey() + " => " + entry.getValue());}// 9. 遍历Map方式2:Java 8+ forEachSystem.out.println("\n遍历方式2: forEach");map.forEach((key, value) -> System.out.println(key + " -> " + value));// 10. 替换值map.replace("Orange", 15);System.out.println("\n替换Orange数量后的Map: " + map); // {Apple=10, Orange=15}// 11. 合并操作(Java 8+)map.merge("Apple", 3, Integer::sum); // 如果存在Apple,数量+3System.out.println("合并后的Apple数量: " + map.get("Apple")); // 13// 12. 获取或默认值(Java 8+)int mangoCount = map.getOrDefault("Mango", 0);System.out.println("Mango的默认数量: " + mangoCount); // 0// 13. 计算值(Java 8+)map.computeIfAbsent("Grape", key -> 7); // 如果不存在则添加Grape=7System.out.println("新增Grape后的Map: " + map); // {Apple=13, Grape=7, Orange=15}// 14. 清空Mapmap.clear();System.out.println("\n清空后的Map是否为空? " + map.isEmpty()); // true}
}Set的使用请参考以下代码:
import java.util.*;public class SetExample {public static void main(String[] args) {// ==================== 基础操作 ====================// 1. 创建Set(默认使用HashSet)Set<String> fruits = new HashSet<>();// 2. 添加元素fruits.add("Apple");fruits.add("Banana");fruits.add("Orange");fruits.add("Apple"); // 重复元素会被忽略System.out.println("初始集合: " + fruits); // 输出: [Apple, Orange, Banana](顺序可能不同)// 3. 删除元素fruits.remove("Banana");System.out.println("删除Banana后: " + fruits); // 输出: [Apple, Orange]// 4. 检查元素是否存在System.out.println("是否包含Apple? " + fruits.contains("Apple")); // trueSystem.out.println("是否包含Mango? " + fruits.contains("Mango")); // false// 5. 集合大小System.out.println("集合大小: " + fruits.size()); // 2// 6. 清空集合fruits.clear();System.out.println("清空后是否为空? " + fruits.isEmpty()); // true// ==================== 集合运算 ====================Set<Integer> setA = new HashSet<>(Arrays.asList(1, 2, 3));Set<Integer> setB = new HashSet<>(Arrays.asList(2, 3, 4));// 并集(修改原集合)Set<Integer> union = new HashSet<>(setA);union.addAll(setB);System.out.println("并集: " + union); // [1, 2, 3, 4]// 交集(修改原集合)Set<Integer> intersection = new HashSet<>(setA);intersection.retainAll(setB);System.out.println("交集: " + intersection); // [2, 3]// 差集(A有B没有)Set<Integer> difference = new HashSet<>(setA);difference.removeAll(setB);System.out.println("差集(A-B): " + difference); // [1]// ==================== 遍历方式 ====================Set<String> colors = new LinkedHashSet<>(); // 保留插入顺序colors.add("Red");colors.add("Green");colors.add("Blue");// 方式1:增强for循环System.out.println("\n遍历方式1:");for (String color : colors) {System.out.print(color + " "); // Red Green Blue}// 方式2:迭代器System.out.println("\n\n遍历方式2:");Iterator<String> it = colors.iterator();while (it.hasNext()) {System.out.print(it.next() + " "); // Red Green Blue}// 方式3:Java 8+ forEachSystem.out.println("\n\n遍历方式3:");colors.forEach(color -> System.out.print(color + " ")); // Red Green Blue// ==================== 不同Set实现对比 ====================// 1. HashSet(无序)Set<Integer> hashSet = new HashSet<>(Arrays.asList(3, 1, 4, 2));System.out.println("\n\nHashSet顺序: " + hashSet); // [1, 2, 3, 4](顺序不保证)// 2. LinkedHashSet(保留插入顺序)Set<Integer> linkedHashSet = new LinkedHashSet<>(Arrays.asList(3, 1, 4, 2));System.out.println("LinkedHashSet顺序: " + linkedHashSet); // [3, 1, 4, 2]// 3. TreeSet(自然排序)Set<Integer> treeSet = new TreeSet<>(Arrays.asList(3, 1, 4, 2));System.out.println("TreeSet顺序: " + treeSet); // [1, 2, 3, 4]}
}其他请参考官方:
Map (Java Platform SE 8 )
Set (Java Platform SE 8 )
结语
好了,本博客就到这里了,觉得有帮助不妨点个赞吧,下次我们讲讲内部类和Lambda表达式,然后我们就开始网络编程与原理的分析了!写地很开心,下次见!(*゚∀゚*)