怎么做租房网站哈尔滨优化推广公司
长期以来Scikit-Learn 一直作为表格数据机器学习的主流框架,它提供了丰富的算法、预处理工具和模型评估功能。尽管 Scikit-Learn 功能完备,但随着技术的发展,新兴框架 PyTabKit 正逐渐崭露头角。该框架专为表格数据的分类和回归任务设计,集成了 RealMLP 等先进技术以及优化的梯度提升决策树(GBDT)超参数配置,为表格数据处理提供了新的技术选择。
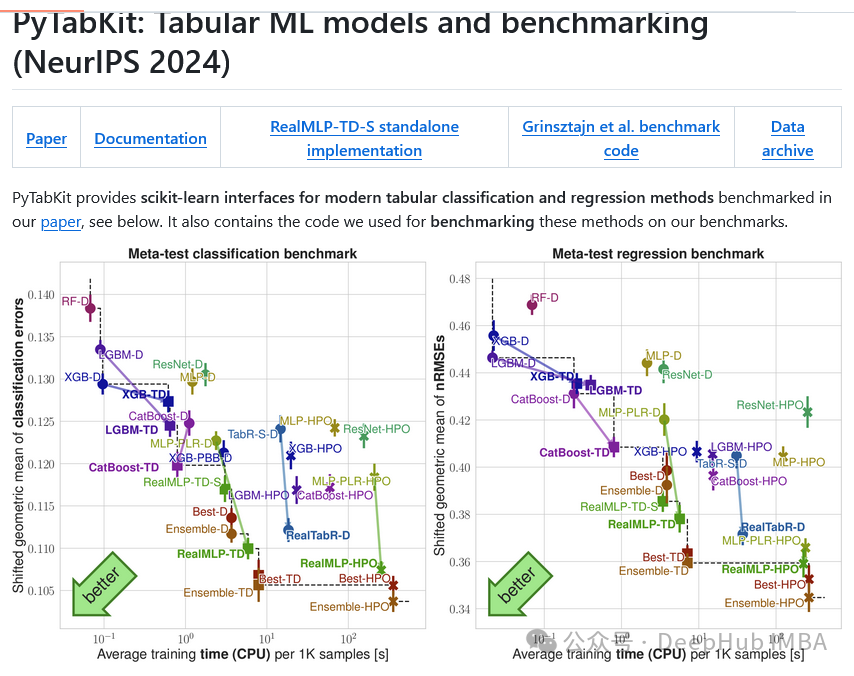
Scikit-Learn 的局限与突破
Scikit-Learn 为机器学习模型开发奠定了坚实基础,但在深度学习方法的优化和超参数自动调整方面存在不足。
传统上应用于表格数据的深度学习模型往往需要繁复的超参数调整过程,限制了其实用性和效率。RealMLP 作为一种经过优化的多层感知器,通过在118个数据集上的基准测试和精细调优,已在中等至大型数据集(1,000-500,000样本)上展现出与GBDT相当的性能表现。RealMLP引入的诸多技术改进,包括鲁棒缩放机制、数值特征嵌入以及优化的权重初始化策略,使其成为传统模型的有效替代方案。
实践表明,相较于经过精细调整的模型,Scikit-Learn的默认超参数配置在性能上通常存在差距。PyTabKit针对XGBoost、LightGBM和CatBoost等主流算法提供了经过**元级调优(meta-tuned)**的默认参数设置,无需手动进行超参数优化(HPO)即可超越Scikit-Learn的基准实现。这些默认配置通过元训练基准进行了系统性优化,并在90个独立数据集上验证了其有效性和泛化能力。
超参数调优,尤其是针对深度学习模型的调优,往往耗费大量计算资源。PyTabKit通过优化的默认配置使得用户能在多数应用场景下无需进行超参数优化,即可获得优异性能。这一特性使PyTabKit尤其适用于AutoML系统,在这类系统中计算效率与预测精度的平衡至关重要。
RealMLP: 表格数据深度学习的技术突破
虽然梯度提升方法长期在结构化数据处理领域占据主导地位,但经过精心设计的深度学习架构正在逐渐缩小这一差距。RealMLP架构引入了多项关键技术创新:
预处理技术优化
RealMLP对数值特征实施鲁棒缩放和平滑裁剪处理,有效减轻异常值影响。同时,对基数有限的分类特征采用独热编码,提高特征表达能力。
架构创新
RealMLP引入对角权重层以增强表示学习能力,设计了优于传统特征转换的数值嵌入方法,并采用更为高效的初始化策略加速模型收敛过程。
性能提升
基准测试结果显示,RealMLP在多种应用场景中不仅能够匹敌GBDT的性能,有时甚至能够超越。将RealMLP与优化配置的GBDT结合使用,可以在不进行昂贵的超参数优化的情况下,获得最先进的预测性能。
大规模数据优化
对于需要处理中等到大规模数据集的用户,PyTabKit提供了显著的优势:训练速度更快、预测精度具有竞争力、调优工作量大幅降低,这使其成为现代机器学习工作流程的理想技术选择。
代码实践:PyTabKit中的RealMLP与树模型应用
PyTabKit保持了与Sklearn相似的API设计,确保了使用的便捷性。
使用以下命令安装
pytabkit
和
openml
库:
!pip install pytabkit!pip install openml
本文使用OpenML提供的Covertype数据集,并将其限制为15,000个样本:
importopenml
fromsklearn.model_selectionimporttrain_test_split
importnumpyasnp# 从OpenML加载Covertype数据集
task=openml.tasks.get_task(361113) # Covertype任务ID
dataset=openml.datasets.get_dataset(task.dataset_id, download_data=False)
X, y, categorical_indicator, attribute_names=dataset.get_data(dataset_format='dataframe',target=task.target_name
)
# 限制为15,000个样本
index=np.random.choice(range(len(X)), 15_000, replace=False)
X=X.iloc[index]
y=y.iloc[index]
# 划分训练集和测试集X_train, X_test, y_train, y_test=train_test_split(X, y, random_state=0)
基础RealMLP模型训练
%%time
frompytabkitimportRealMLP_TD_Classifier
fromsklearn.metricsimportaccuracy_score# 训练RealMLP模型
model=RealMLP_TD_Classifier()
model.fit(X_train, y_train)
# 进行预测并评估准确率
y_pred=model.predict(X_test)
acc=accuracy_score(y_test, y_pred)print(f"Accuracy of RealMLP: {acc}")
预期输出:
Accuracy of RealMLP: 0.8770666666666667
RealMLP通过
n_cv=5
参数支持基于5折交叉验证的集成学习。得益于向量化计算,该方法仍保持高效的训练速度:
%%time
# 使用bagging训练RealMLP
model=RealMLP_TD_Classifier(n_cv=5)
model.fit(X_train, y_train)# 进行预测并评估准确率
y_pred=model.predict(X_test)
acc=accuracy_score(y_test, y_pred)print(f"Accuracy of RealMLP with bagging: {acc}")
预期输出:
Accuracy of RealMLP with bagging: 0.8930666666666667
通过
RealMLP_HPO_Classifier
可实现自动超参数优化。优化步骤数量可根据需要进行调整:
%%time
frompytabkitimportRealMLP_HPO_Classifiern_hyperopt_steps=3 # 用于演示的步骤数
model=RealMLP_HPO_Classifier(n_hyperopt_steps=n_hyperopt_steps)
model.fit(X_train, y_train)
# 进行预测并评估准确率
y_pred=model.predict(X_test)
acc=accuracy_score(y_test, y_pred)print(f"Accuracy of RealMLP with {n_hyperopt_steps} steps HPO: {acc}")
预期输出:
Accuracy of RealMLP with 3 steps HPO: 0.8605333333333334
比较调优后默认参数(TD)与原始默认参数(D)的性能差异:
%%time
frompytabkitimport (CatBoost_TD_Classifier, CatBoost_D_Classifier,LGBM_TD_Classifier, LGBM_D_Classifier,XGB_TD_Classifier, XGB_D_Classifier
)# 评估多种树模型
formodelin [CatBoost_TD_Classifier(), CatBoost_D_Classifier(),LGBM_TD_Classifier(), LGBM_D_Classifier(),XGB_TD_Classifier(), XGB_D_Classifier()]:model.fit(X_train, y_train)y_pred=model.predict(X_test)acc=accuracy_score(y_test, y_pred)print(f"Accuracy of {model.__class__.__name__}: {acc}")
预期输出:
Accuracy of CatBoost_TD_Classifier: 0.8685333333333334Accuracy of CatBoost_D_Classifier: 0.8464Accuracy of LGBM_TD_Classifier: 0.8602666666666666Accuracy of LGBM_D_Classifier: 0.8344Accuracy of XGB_TD_Classifier: 0.8544Accuracy of XGB_D_Classifier: 0.8472
通过集成多种优化模型可构建高性能预测基线:
%%time
frompytabkitimportEnsemble_TD_Classifier# 训练集成模型
model=Ensemble_TD_Classifier()
model.fit(X_train, y_train)
# 进行预测并评估准确率
y_pred=model.predict(X_test)
acc=accuracy_score(y_test, y_pred)print(f"Accuracy of Ensemble_TD_Classifier: {acc}")
预期输出:
Accuracy of Ensemble_TD_Classifier: 0.8962666666666667
总结
PyTabKit框架通过集成优化的深度学习和梯度提升技术,为表格数据处理提供了一套全新的解决方案。实验结果表明,该框架的主要优势包括:
性能提升:经过元级调优的模型默认配置在无需额外调优的情况下,显著优于传统实现,特别是在中等到大型数据集上。
开发效率:简化的API设计和优化的默认参数大幅减少了开发周期,使数据科学家能够将更多精力集中在业务理解与模型解释上。
资源节约:通过减少或消除繁重的超参数优化需求,PyTabKit有效降低了计算资源消耗,特别适合资源受限的环境。
多模型集成:如实验所示,集成多种优化模型能够进一步提升预测性能,为实际应用提供更可靠的结果。
随着表格数据在企业决策、风险管理和资源优化等领域的持续重要性,PyTabKit这类专为表格数据设计的现代框架将扮演越来越重要的角色。其简化的工作流程和卓越的性能使其成为连接传统机器学习和现代深度学习技术的重要桥梁。
对于数据科学从业者而言,掌握PyTabKit等新兴工具将是应对日益复杂的数据分析挑战的重要技能。无论是在高度竞争的预测建模比赛中,还是在要求快速部署的企业环境中,这些工具都能提供显著的竞争优势。
在未来的发展中,期待PyTabKit能够进一步整合自动化特征工程、可解释AI等新兴技术,为表格数据分析提供更全面的支持。
PyTabKit项目地址:
https://avoid.overfit.cn/post/90c45b2d4a464b33a966a43615b1406e