做移动端网站软件下载学开网店哪个培训机构好正规
随机森林(Random Forest)是一种基于决策树的集成学习算法,它通过构建多个决策树并将它们的预测结果进行综合,从而提高模型的准确性和稳定性。
1.基本原理
随机森林属于集成学习中的“Bagging”方法。其核心思想是通过构建多个决策树,并将它们的预测结果进行投票或平均,从而得到最终的预测结果。
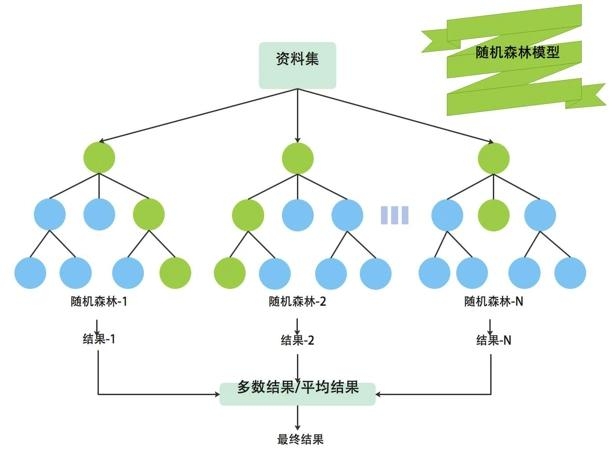
具体步骤如下:
数据采样:从原始训练数据集中随机有放回地抽取多个子样本(Bootstrap Sampling),每个子样本的大小与原始数据集相同。
特征选择:在构建每个决策树时,每次分裂节点时随机选择一部分特征(通常是总特征数的平方根个),而不是使用所有特征。这增加了决策树之间的多样性。
构建决策树:对每个子样本使用随机选择的特征构建决策树,决策树的构建过程通常不需要剪枝(即树可以生长到最大深度)。
集成预测:对于分类问题,通过多数投票法确定最终预测类别;对于回归问题,通过取平均值确定最终预测值。
2.参数调整
随机森林的主要参数包括:
决策树的数量(n_estimators):决策树的数量越多,模型的性能通常越好,但同时也会增加训练和预测的时间和空间开销。一般需要通过交叉验证来选择合适的数量。
最大深度(max_depth):限制决策树的最大深度,可以防止过拟合,但过小的深度可能会导致欠拟合。
最大特征数(max_features):每次分裂节点时随机选择的特征数量,通常设置为总特征数的平方根或对数。
最小叶节点样本数(min_samples_leaf):叶节点所需的最小样本数量,用于控制决策树的生长,防止过拟合。
最小分裂节点样本数(min_samples_split):分裂内部节点所需的最小样本数量,同样用于防止过拟合。
通过合理调整这些参数,可以优化随机森林模型的性能,使其在不同的数据集和应用场景中表现出色。
3.模型应用
- 引入必要模块
import numpy as np import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report - 首先通过
numpy的随机数生成函数编造了包含学生平时作业成绩、模拟考成绩、出勤天数这几个特征的数据,一共 100 条记录,并根据这些特征计算出一个虚拟的总分,依据总分设定了是否通过考试的目标标签(target)。# 编造数据集,假设包含学生的平时作业成绩、模拟考成绩、出勤天数等特征,共100条数据 np.random.seed(42) n_samples = 100 homework_scores = np.random.randint(0, 100, n_samples) mock_exam_scores = np.random.randint(0, 100, n_samples) attendance_days = np.random.randint(0, 100, n_samples)# 假设总分大于等于60分算通过考试,生成目标标签 total_scores = homework_scores + mock_exam_scores + attendance_days target = np.where(total_scores >= 60, 1, 0) - 然后将数据整理成
pandas的DataFrame格式,划分出特征矩阵X和目标向量y。# 构建DataFrame data = pd.DataFrame({'homework_scores': homework_scores,'mock_exam_scores': mock_exam_scores,'attendance_days': attendance_days,'target': target }) - 接着使用
train_test_split函数将数据划分为训练集和测试集,按照 80% 训练、20% 测试的比例进行划分。# 划分特征和目标变量 X = data[['homework_scores','mock_exam_scores', 'attendance_days']] y = data['target']# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) - 之后构建了一个随机森林分类模型,设置了决策树数量为 100 棵,并传入随机种子保证可复现性,使用训练集数据对模型进行训练。
# 构建随机森林分类器 rf_model = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型 rf_model.fit(X_train, y_train) - 最后在测试集上进行预测,并通过计算准确率以及输出更详细的分类报告(包含精确率、召回率、F1 值等指标)来评估模型的性能。
# 在测试集上进行预测 y_pred = rf_model.predict(X_test)# 评估模型 accuracy = accuracy_score(y_test, y_pred) print("准确率:", accuracy) print("分类报告:") print(classification_report(y_test, y_pred))
4.模型评价
优点
高准确性:通过集成多个决策树,随机森林能够显著提高模型的预测性能,尤其在处理复杂数据集时表现优异。
抗过拟合能力:由于随机森林在构建过程中引入了样本和特征的随机性,相比单棵决策树,它对噪声和异常值的鲁棒性更强,不容易过拟合。
可处理多种类型的数据:随机森林可以处理数值型和分类型特征,无需对数据进行复杂的预处理。
特征重要性评估:随机森林能够计算特征的重要性,帮助识别对预测目标最有影响的特征,为特征选择和数据理解提供依据。
并行化处理:由于每个决策树的构建是独立的,随机森林可以并行化处理,大大提高了训练效率。
缺点
模型复杂度高:随机森林由多个决策树组成,模型结构复杂,训练和预测的时间和空间开销较大,尤其是当决策树的数量较多时。
可解释性差:虽然单棵决策树具有很好的可解释性,但随机森林由于是由多个决策树集成而成,整体的可解释性相对较弱,难以直观地理解模型的决策过程。
对数据不平衡敏感:在处理类别不平衡的数据集时,随机森林可能会偏向于多数类,导致对少数类的预测性能较差。