网站建设与维护怎么学平台开发
目录
1.多分类--定义
2.多分类--原理
2.1.OVO(一对一)
2.1.1.手写代码
2.1.2.调包侠
2.2.OVR(一对多)
2.2.1.手写代码
2.2.2.调包侠
OVO和OVR的区别
2.3.Error Correcting纠错编码(多对多)
3.多分类--实战
1.数据导入
2.数据可视化
3.数据合并
4.数据处理
5.测试--机器学习
6.测试-- 多层感知机(MLP)
7.测试--卷积神经网络(CNN)
1.多分类--定义
单标签多分类问题其实是指待预测的label标签只有一个,但是label标签的取值可能有多种情况;直白来讲就是每个实例的可能类别有K种![]() 。
。
常见算法:Softmax、KNN、决策树等。
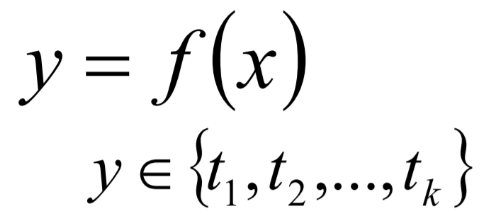
2.多分类--原理
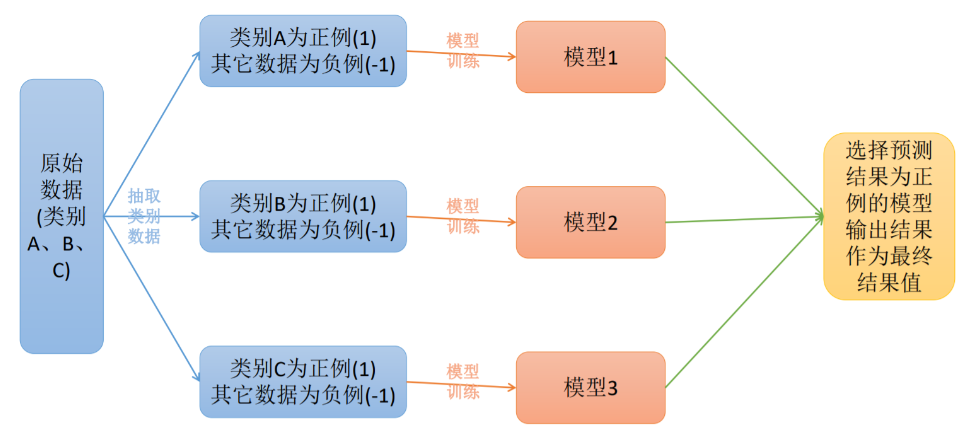
在实际的工作中,如果是一个多分类的问题,我们可以将这个待求解的问题转换 为二分类算法的延伸,即将多分类任务拆分为若干个二分类任务求解,具体的策略如下:
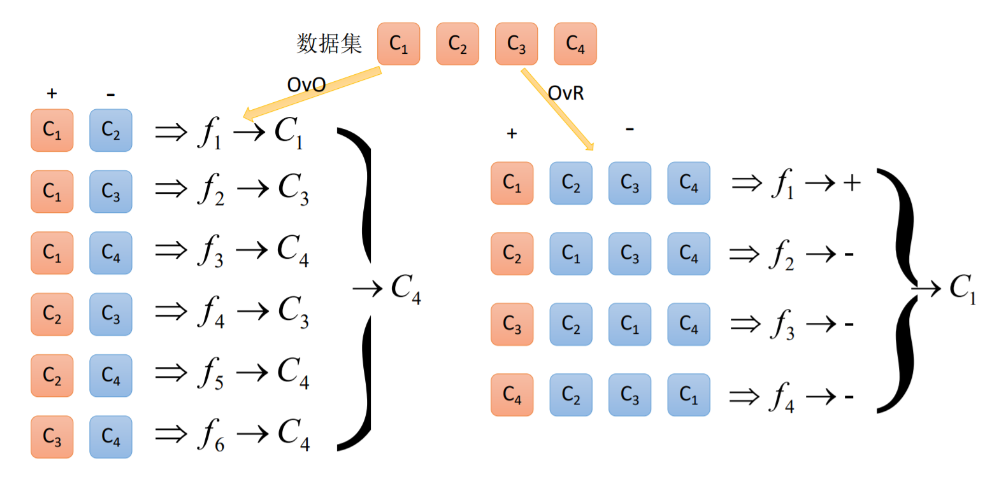
- One-Versus-One(ovo):一对一
- One-Versus-All / One-Versus-the-Rest(ova/ovr): 一对多
- Error Correcting Output codes(纠错码机制):多对多

2.1.OVO(一对一)
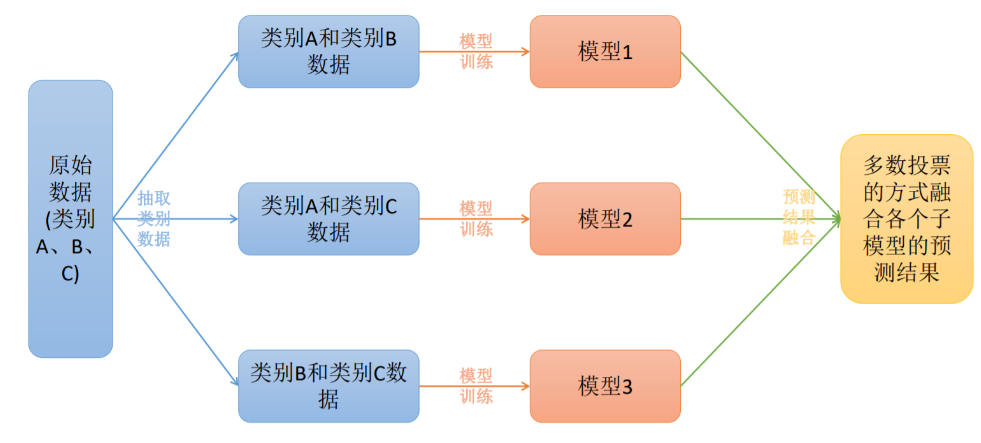
将K个类别中的两两类别数据进行组合,然后使用组合后的数据训练出来一个模型,从而产生K(K−1)/2个分类器,将这些分类器的结果进行融合,并将分类器的预测结果使用多数投票的方式输出最终的预测结果值。
2.1.1.手写代码
def ovo(datas,estimator):'''datas[:,-1]为目标属性'''import numpy as npY = datas[:,-1]X = datas[:,:-1]y_value = np.unique(Y)#计算类别数目k = len(y_value)modles = []#将K个类别中的两两类别数据进行组合,并对y值进行处理for i in range(k-1):c_i = y_value[i]for j in range(i+1,k):c_j = y_value[j]new_datas = []for x,y in zip(X,Y):if y == c_i or y == c_j:new_datas.append(np.hstack((x,np.array([2*float(y==c_i)-1]))))new_datas = np.array(new_datas)algo = estimator()modle = algo.fit(new_datas)modles.append([(c_i,c_j),modle])return modles
def argmaxcount(seq):'''计算序列中出现次数最多元素''''''超极简单的方法'''# from collections import Counter# return Counter(seq).values[0]'''稍微复杂的'''# dict_num = {}# for item in seq:# if item not in dict_num.keys():# dict_num[item] = seq.count(item)# # 排序# import operator# sorted(dict_num.items(), key=operator.itemgetter(1))'''字典推导'''dict_num = dict_num = {i: seq.count(i) for i in set(seq)}def ovo_predict(X,modles):import operatorresult = []for x in X:pre = []for cls,modle in modles:pre.append(cls[0] if modle.predict(x) else cls[1])d = {i: pre.count(i) for i in set(pre)} #利用集合的特性去重result.append(sorted(d.items(),key=operator.itemgetter(1))[-1][0])return result
2.1.2.调包侠
class sklearn.multiclass.OneVsOneClassifier(estimator, n_jobs=1)
estimator:
- 类型:对象
- 这是用于一对一比较的基估计器对象,它必须是一个二分类器。换句话说,estimator是你在每个类别对上训练的实际模型。例如,你可以使用支持向量机(SVM)、逻辑回归、决策树等。
n_jobs:
- 类型:int, 可选,默认为1
- 这个参数指定了用于拟合和预测的CPU核心数量。如果
n_jobs设为-1,那么所有的CPU核心都会被使用。如果设置为1,则不进行并行计算。如果设置为大于1的整数,那么就是在指定使用的核心数。这个参数对于大型数据集和复杂模型特别有用,因为它可以显著减少计算时间。
from sklearn import datasets
from sklearn.multiclass import OneVsOneClassifier
from sklearn.svm import LinearSVC
from sklearn.neighbors import KNeighborsClassifier# 加载数据
iris = datasets.load_iris()# 获取X和y
X, y = iris.data, iris.target
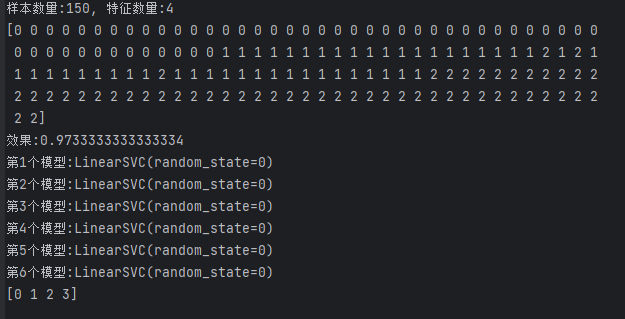
print("样本数量:%d, 特征数量:%d" % X.shape)
# 设置为3,只是为了增加类别,看一下ovo和ovr的区别
y[-1] = 3# 模型构建
clf = OneVsOneClassifier(LinearSVC(random_state=0))
# clf = OneVsOneClassifier(KNeighborsClassifier())
# 模型训练
clf.fit(X, y)# 输出预测结果值
print(clf.predict(X))
print("效果:{}".format(clf.score(X, y)))# 模型属性输出
k = 1
for item in clf.estimators_:print("第%d个模型:" % k, end="")print(item)k += 1
print(clf.classes_)
2.2.OVR(一对多)
原理:
- 将每一个类别作为正例,其它剩余的样例作为反例分别来训练K 个模型;
- 在预测的时候,如果在这K个模型中,只有一个模型输出为正例,那么最终的预测结果就是属于该分类器的这个类别;
- 如果产生多个正例,那么则可以选择根据分类器的置信度作为指标,来选择置信度最大的分类器作为最终结果,常见置信度:精确度、召回率。
2.2.1.手写代码
def ovr(datas,estimator):'''datas[:,-1]为目标属性'''import numpy as npY = datas[:,-1]X = datas[:,:-1]y_value = np.unique(Y)#计算类别数目k = len(y_value)modles = []#准备K个模型的训练数据,并对y值进行处理for i in range(k):c_i = y_value[i]new_datas = []for x,y in zip(X,Y):new_datas.append(np.hstack((x,np.array([2*float(y==c_i)-1]))))new_datas = np.array(new_datas)algo = estimator()modle = algo.fit(new_datas)confidence = modle.score(new_datas) #计算置信度modles.append([(c_i,confidence),modle])return modlesdef ovr_predict(X,modles):import operatorresult = []for x in X:pre = []cls_confi = []for cls,modle in modles:cls_confi.append(cls)pre.append(modle.predict(x))pre_res = []for c,p in zip(cls_confi,pre):if p == 1:pre_res.append(c)if not pre_res:pre_res = cls_confiresult.append(sorted(pre_res,key=operator.itemgetter(1))[-1][0])return result
2.2.2.调包侠
sklearn.multiclass.OneVsRestClassifier
参数同上。
from sklearn import datasets
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score# 数据获取
iris = datasets.load_iris()
X, y = iris.data, iris.target
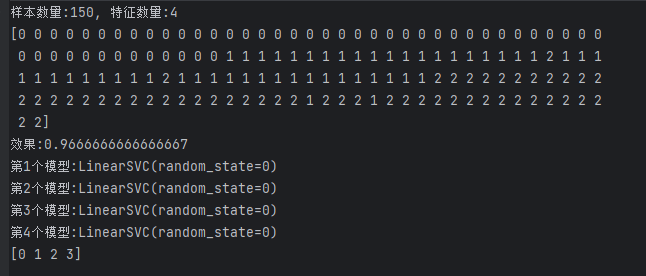
print("样本数量:%d, 特征数量:%d" % X.shape)
# 设置为3,只是为了增加类别,看一下ovo和ovr的区别
y[-1] = 3# 模型创建
clf = OneVsRestClassifier(LinearSVC(random_state=0))
# 模型构建
clf.fit(X, y)# 预测结果输出
# 输出预测结果值
print(clf.predict(X))
print("效果:{}".format(clf.score(X, y)))# 模型属性输出
k = 1
for item in clf.estimators_:print("第%d个模型:" % k, end="")print(item)k += 1
print(clf.classes_)
OVO和OVR的区别
2.3.Error Correcting纠错编码(多对多)
原理:将模型构建应用分为两个阶段:编码阶段和解码阶段。
- 编码阶段:对K个类别中进行M次划分,每次划分将一部分数据分为正类,一部分数据分为反类,每次划分都构建出来一个模型,模型的结果是在空间中对于每个类别都定义了一个点;
- 解码阶段中使用训练出来的模型对测试样例进行预测,将预测样本对应的点和类别之间的点求距离,选择距离最近的类别作为最终的预测类别。
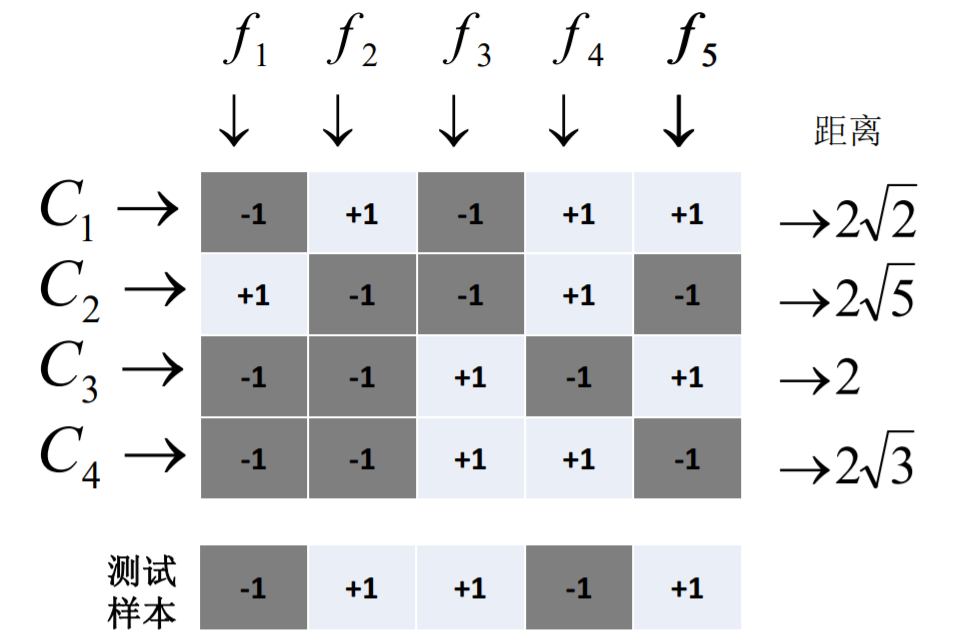
class sklearn.multiclass.OutputCodeClassifier(estimator, code_size=1.5, random_state=None, n_jobs=1)
estimator:
- 类型:对象
- 这是用于训练的基本估计器对象,它必须是一个二分类器。这个估计器将被用于训练多个二分类器,每个分类器对应于编码中的一个位。
code_size:
- 类型:浮点数,可选,默认为 1.5
- 这个参数控制了输出代码的密度。较小的值意味着更少的二分类器将被训练,而较大的值则意味着更多的二分类器将被训练。代码的大小会影响分类器的性能和计算成本。
random_state:
- 类型:int, RandomState 实例或 None,可选,默认为 None
- 控制随机数生成器的种子,用于输出代码的生成。在需要可重复的结果时,这个参数很有用。
n_jobs:
- 类型:int, 可选,默认为 1
- 这个参数指定了用于拟合和预测的 CPU 核心数量。
from sklearn import datasets
from sklearn.multiclass import OutputCodeClassifier
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score# 数据获取
iris = datasets.load_iris()
X, y = iris.data, iris.target
print("样本数量:%d, 特征数量:%d" % X.shape)# 模型对象创建
# code_size: 指定最终使用多少个子模型,实际的子模型的数量=int(code_size*label_number)
# code_size设置为1,等价于ovr子模型个数;
# 设置为0~1, 那相当于使用比较少的数据划分,效果比ovr差;
# 设置为大于1的值,那么相当于存在部分模型冗余的情况
clf = OutputCodeClassifier(LinearSVC(random_state=0), code_size=30, random_state=0)
# 模型构建
clf.fit(X, y)# 输出预测结果值
print(clf.predict(X))
print("准确率:%.3f" % accuracy_score(y, clf.predict(X)))# 模型属性输出
k = 1
for item in clf.estimators_:print("第%d个模型:" % k, end="")print(item)k += 1
print(clf.classes_)
3.多分类--实战
DDoS 2019 | Datasets | Research | Canadian Institute for Cybersecurity | UNB (页面最下端)是某DDoS攻击产生的数据,分为正常和异常。CIC-DDOS2019数据的分类。
请基于该数据设计并实现检测DDoS攻击的算法模型。
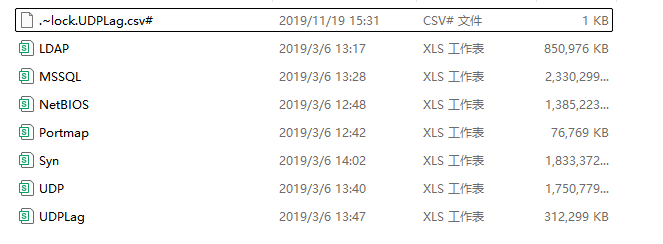
| 文件名 | 攻击类型 | 说明 |
| .~lock.UDPLag.csv# | UDP泛洪攻击 | 记录了UDP协议的延迟数据,可能用于分析UDP泛洪攻击。 |
| LDAP | LDAP放大攻击 | 包含LDAP协议相关的数据,可能用于检测LDAP放大攻击。 |
| MSSQL | SQL注入攻击 | 包含MSSQL数据库相关的数据,可能用于检测针对SQL服务器的攻击。 |
| NetBIOS | NetBIOS放大攻击 | 包含NetBIOS协议相关的数据,可能用于检测NetBIOS放大攻击。 |
| Portmap | 端口扫描/映射攻击 | 包含端口映射相关的数据,可能用于检测端口扫描或映射攻击。 |
| Syn | SYN洪水攻击 | 包含TCP SYN包相关的数据,用于分析SYN洪水攻击。 |
| UDP | UDP泛洪攻击 | 包含UDP协议相关的数据,可能用于检测UDP泛洪攻击。 |
| udplog | UDP泛洪攻击日志 | 记录了与UDP泛洪攻击相关的数据,可能用于攻击分析和检测。 |
1.数据导入
#1.加载数据
import os
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime# 设置路径和时间戳
directory = r'D:\桌面文件\CSV-03-11\03-11'
current_time = datetime.now().strftime("%Y-%m-%d %H:%M") # 2025-03-28 14:49# 收集数据
file_names = []
row_counts = []
errors = []for file in os.listdir(directory):if file.endswith('.csv'):try:data = pd.read_csv(os.path.join(directory, file))file_names.append(file)row_counts.append(len(data))print(f"{file}: {len(data)} 行")except Exception as e:errors.append(f"{file}: {str(e)}")
数据统计:
import matplotlib.pyplot as plt
from matplotlib import rcParams# 1. 字体全局设置(适配Windows/macOS/Linux)
rcParams['font.sans-serif'] = ['Microsoft YaHei', 'Arial Unicode MS', 'SimHei'] # 多字体备选
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
rcParams['font.size'] = 12 # 全局字体基准大小# 2. 创建画布与柱状图
plt.figure(figsize=(14, 7), dpi=100) # 增大画布尺寸和分辨率
bars = plt.bar(range(len(file_names)), # 用数字序号代替文件名(解决拥挤问题)row_counts,color='#4CAF50',edgecolor='grey',width=0.6 # 调窄柱宽增加间距
)# 3. 横坐标优化方案
ax = plt.gca()
ax.set_xticks(range(len(file_names))) # 设置刻度位置
ax.set_xticklabels([f[:10]+'...' if len(f)>10 else f for f in file_names], # 超长文件名截断rotation=30, # 适度旋转角度ha='right',fontsize=10, # 调大字体fontweight='bold' # 加粗显示
)# 4. 其他美化设置
plt.title("CSV文件行数统计\n"f"生成时间:2025年3月28日 15:15(农历乙巳年二月廿九)",fontsize=14,pad=20
)
plt.xlabel(" 文件名", fontsize=12, labelpad=10) # 增加标签间距
plt.ylabel(" 行数", fontsize=12)
plt.grid(axis='y', linestyle=':', alpha=0.4) # 更淡的网格线# 5. 数据标注与平均线
mean_rows = sum(row_counts) / len(row_counts)
for idx, bar in enumerate(bars):height = bar.get_height()ax.text(idx, height + max(row_counts)*0.01, # 文字位置微调f'{int(height)}',ha='center',va='bottom',fontsize=9,bbox=dict(facecolor='white', alpha=0.7, edgecolor='none') # 文字背景框)
plt.axhline(mean_rows,color='red',linestyle='--',linewidth=1.5,label=f'平均行数: {int(mean_rows)}'
)
plt.legend(loc='upper right') # 增加图例
plt.tight_layout(pad=2) # 增加布局边距
plt.show()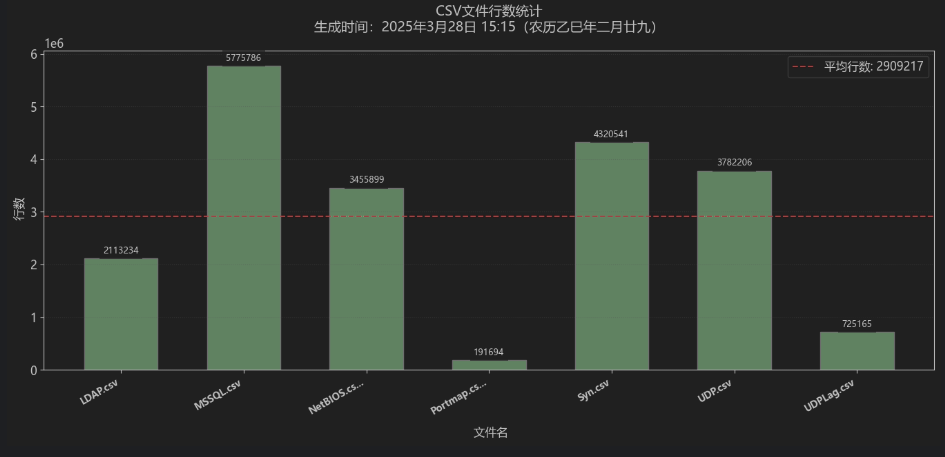
特征提取:
#获取特征名称
import pandas as pd
from tabulate import tabulate# 读取Portmap.csv 首行(假设文件存在)
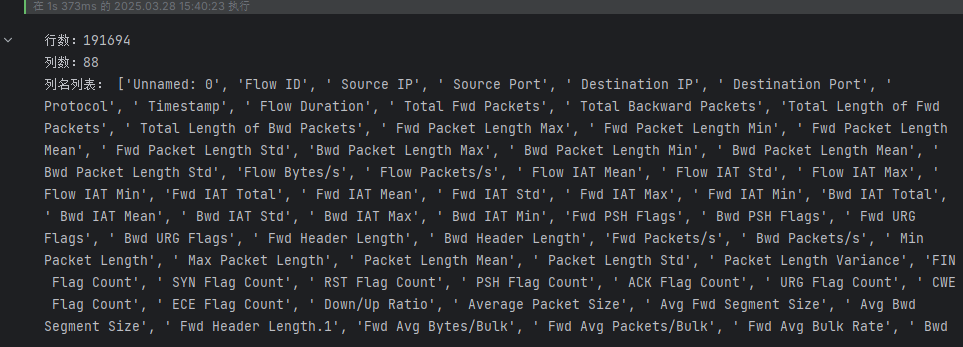
try:# 读取CSV文件(处理可能的编码和类型警告)df = pd.read_csv(r"D:\桌面文件\CSV-03-11\03-11\Portmap.csv")#输出行,列print(f"行数:{len(df)}")print(f"列数:{len(df.columns)}")# 查看第一行数据column_names = df.columns.tolist()print("列名列表:", column_names)#输出表格# print(tabulate(df, headers='keys', tablefmt='psql'))
except Exception as e:print(f"读取文件失败:{str(e)}")
2.数据可视化
#2.数据可视化import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
file_path = r'D:\桌面文件\CSV-03-11\03-11\LDAP.csv'
data = pd.read_csv(file_path)# 设置绘图样式
sns.set(style="whitegrid")# 创建一个图形框架
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(16, 6))# 散点图:流持续时间与前向数据包数量
sns.scatterplot(ax=axes[0], x=data[' Flow Duration'], y=data[' Total Fwd Packets'], color='blue')
axes[0].set_title('Flow Duration vs Total Fwd Packets')
axes[0].set_xlabel('Flow Duration')
axes[0].set_ylabel('Total Fwd Packets')# 箱线图:前向和后向数据包的分布
sns.boxplot(data=data[[' Total Fwd Packets', ' Total Backward Packets']], ax=axes[1])
axes[1].set_title('Distribution of Packet Counts')
axes[1].set_ylabel('Packet Counts')plt.tight_layout()
plt.show()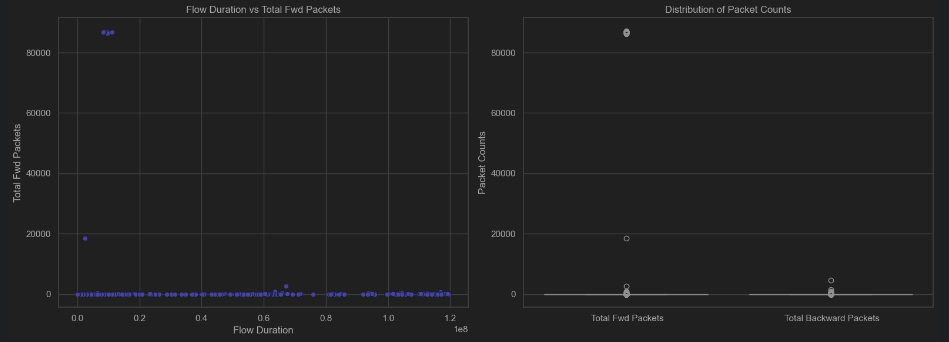
3.数据合并
#3.数据合并
import pandas as pd
import os# 文件目录
directory = r'D:\桌面文件\CSV-03-11\03-11'# 文件列表
files = ['LDAP.csv', 'MSSQL.csv', 'NetBIOS.csv', 'Portmap.csv','Syn.csv', 'UDP.csv', 'UDPLag.csv'
]# 创建空的DataFrame
combined_data = pd.DataFrame()# 对每个文件进行处理
for file in files:file_path = os.path.join(directory, file)# 加载数据data = pd.read_csv(file_path)# 随机选取500条数据sample_data = data.sample(n=500, random_state=1)# 将数据加入到总的DataFrame中combined_data = pd.concat([combined_data, sample_data], ignore_index=True)# 保存到新的CSV文件
combined_data.to_csv('./combined_data.csv', index=False)print("数据合并完成,已保存到combined_data.csv")4.数据处理
import pandas as pd
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
import numpy as np# 加载数据
data = pd.read_csv('./combined_data.csv')# 删除不需要的列,例如时间戳或IP地址(假设你的数据集中有这些列)
data.drop([' Timestamp','Flow ID',' Source IP',' Destination IP'], axis=1, inplace=True)# 类型转换,将分类标签编码
label_encoder = LabelEncoder()
data[' Label'] = label_encoder.fit_transform(data[' Label'])# 1. 强制类型转换(全表处理)
data = data.apply(pd.to_numeric, errors='coerce')
# 检查并处理无穷大和非常大的数值
data.replace([np.inf, -np.inf], np.nan, inplace=True) # 将inf替换为NaN
data.fillna(data.median(), inplace=True) # 使用中位数填充NaN,确保之前中位数计算不包括inf# 特征标准化
scaler = StandardScaler()
X = scaler.fit_transform(data.drop(' Label', axis=1)) # 确保标签列不参与标准化
y = data[' Label']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)print("数据预处理完成,准备进行模型训练和测试。")
5.测试--机器学习
#机器学习算法
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, classification_report# 初始化模型
logreg = LogisticRegression(max_iter=1000)
rf = RandomForestClassifier(n_estimators=100)
svm = SVC()
xgb = XGBClassifier(use_label_encoder=False, eval_metric='mlogloss')# 训练逻辑回归模型
logreg.fit(X_train, y_train)
y_pred_logreg = logreg.predict(X_test)
print("Logistic Regression Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_logreg) * 100))# 训练随机森林模型
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print("Random Forest Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_rf) * 100))# 训练支持向量机模型
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)
print("SVM Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_svm) * 100))# 训练XGBoost模型
xgb.fit(X_train, y_train)
y_pred_xgb = xgb.predict(X_test)
print("XGBoost Accuracy: {:.2f}%".format(accuracy_score(y_test, y_pred_xgb) * 100))# 打印分类报告(以XGBoost为例)
print("\nClassification Report for XGBoost:")
print(classification_report(y_test, y_pred_xgb))
# 混淆矩阵
from sklearn.metrics import confusion_matrix
cm_logreg = confusion_matrix(y_test, y_pred_logreg)
cm_rf = confusion_matrix(y_test, y_pred_rf)
cm_svm = confusion_matrix(y_test, y_pred_svm)# 绘制混淆矩阵的热图
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(18, 6))
sns.heatmap(cm_logreg, annot=True, fmt="d", ax=axes[0], cmap='Blues')
axes[0].set_title('Logistic Regression Confusion Matrix')
axes[0].set_xlabel('Predicted labels')
axes[0].set_ylabel('True labels')sns.heatmap(cm_rf, annot=True, fmt="d", ax=axes[1], cmap='Blues')
axes[1].set_title('Random Forest Confusion Matrix')
axes[1].set_xlabel('Predicted labels')
axes[1].set_ylabel('True labels')sns.heatmap(cm_svm, annot=True, fmt="d", ax=axes[2], cmap='Blues')
axes[2].set_title('SVM Confusion Matrix')
axes[2].set_xlabel('Predicted labels')
axes[2].set_ylabel('True labels')plt.tight_layout()
plt.savefig("confusion.png")
plt.show()
 6.测试-- 多层感知机(MLP)
6.测试-- 多层感知机(MLP)
#5.深度学习算法
#MLP--多层感知机
import torch
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim# 转换数据为torch张量
X_train_tensor = torch.tensor(X_train.astype(np.float32)) # 确保数据类型为 float32
y_train_tensor = torch.tensor(y_train.values.astype(np.int64)) # 先获取values再转换类型为 long (int64)
X_test_tensor = torch.tensor(X_test.astype(np.float32))
y_test_tensor = torch.tensor(y_test.values.astype(np.int64))# 创建数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 定义模型
class NeuralNetwork(nn.Module):def __init__(self, input_size, num_classes):super(NeuralNetwork, self).__init__()self.layer1 = nn.Linear(input_size, 64)self.relu = nn.ReLU()self.layer2 = nn.Linear(64, 64)self.output_layer = nn.Linear(64, num_classes)def forward(self, x):x = self.relu(self.layer1(x))x = self.relu(self.layer2(x))x = self.output_layer(x)return x# 初始化模型
input_size = X_train.shape[1]
num_classes = len(np.unique(y))
model = NeuralNetwork(input_size, num_classes)# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)num_epochs = 200
train_acc = []
test_acc = []
all_preds = []
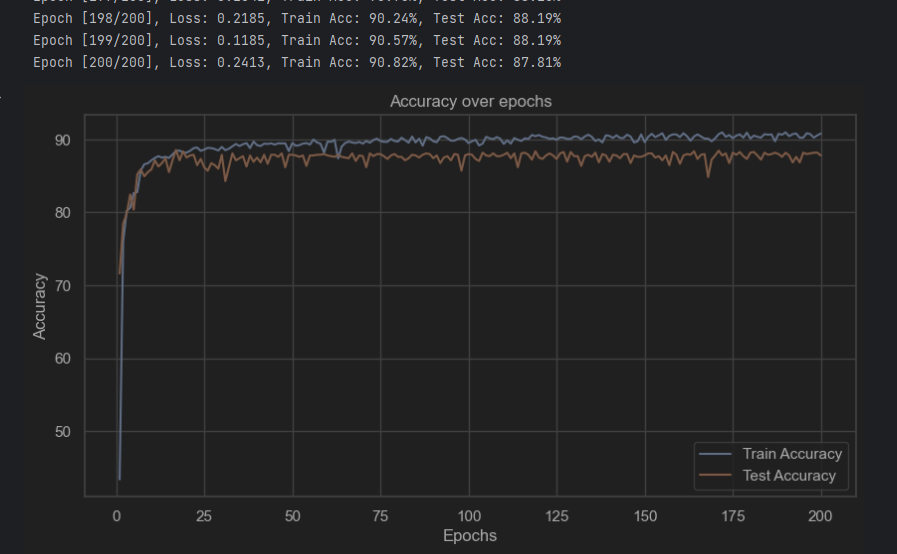
all_labels = []for epoch in range(num_epochs):model.train() # 确保模型在训练模式correct_train = 0total_train = 0for inputs, targets in train_loader:outputs = model(inputs)loss = criterion(outputs, targets)_, predicted = torch.max(outputs.data, 1)total_train += targets.size(0)correct_train += (predicted == targets).sum().item()# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 计算训练准确率train_accuracy = 100 * correct_train / total_traintrain_acc.append(train_accuracy)# 测试模型model.eval() # 设置模型为评估模式correct_test = 0total_test = 0with torch.no_grad():for inputs, labels in DataLoader(TensorDataset(X_test_tensor, y_test_tensor), batch_size=64):outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total_test += labels.size(0)correct_test += (predicted == labels).sum().item()all_preds.extend(predicted.numpy())all_labels.extend(labels.numpy())# 计算测试准确率test_accuracy = 100 * correct_test / total_testtest_acc.append(test_accuracy)# 每个epoch打印训练和测试的损失和准确率print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}, Train Acc: {train_accuracy:.2f}%, Test Acc: {test_accuracy:.2f}%')# 绘制训练和测试准确率图
plt.figure(figsize=(10, 5))
plt.plot(range(1, num_epochs+1), train_acc, label='Train Accuracy')
plt.plot(range(1, num_epochs+1), test_acc, label='Test Accuracy')
plt.title('Accuracy over epochs')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show()# 计算混淆矩阵
cm = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.show()
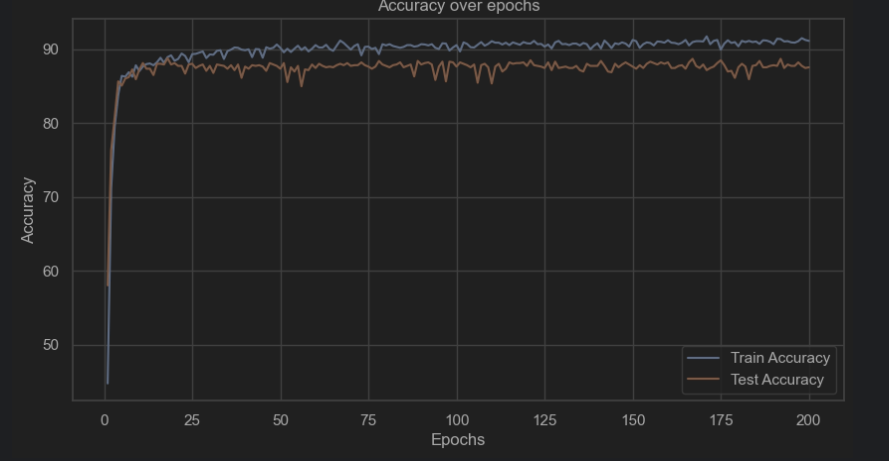
7.测试--卷积神经网络(CNN)
#CNN--卷积神经网络
import numpy as np# 转换数据为torch张量
X_train_tensor = torch.tensor(X_train.astype(np.float32)) # 确保数据类型为 float32
y_train_tensor = torch.tensor(y_train.values.astype(np.int64)) # 先获取values再转换类型为 long (int64)
X_test_tensor = torch.tensor(X_test.astype(np.float32))
y_test_tensor = torch.tensor(y_test.values.astype(np.int64))# 创建数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset# 定义模型
class CNN(nn.Module):def __init__(self, input_size, num_classes):super(CNN, self).__init__()self.conv1 = nn.Conv1d(1, 16, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.pool = nn.MaxPool1d(kernel_size=2, stride=2)self.conv2 = nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=1)# 计算池化后的尺寸conv1_out_size = (input_size + 2 * 1 - 3) / 1 + 1 # Conv1pool1_out_size = conv1_out_size / 2 # Pool1conv2_out_size = (pool1_out_size + 2 * 1 - 3) / 1 + 1 # Conv2pool2_out_size = conv2_out_size / 2 # Pool2final_size = int(pool2_out_size) * 32 # conv2 的输出通道数 * 输出长度self.fc = nn.Linear(final_size, num_classes)def forward(self, x):x = x.unsqueeze(1) # Adding a channel dimensionx = self.relu(self.conv1(x))x = self.pool(x)x = self.relu(self.conv2(x))x = self.pool(x)x = torch.flatten(x, 1)x = self.fc(x)return x# 初始化模型
input_size = X_train.shape[1]
num_classes = len(np.unique(y))
model = CNN(input_size,num_classes)num_epochs = 200
train_acc = []
test_acc = []
all_preds = []
all_labels = []# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)for epoch in range(num_epochs):model.train() # 确保模型在训练模式correct_train = 0total_train = 0for inputs, targets in train_loader:outputs = model(inputs)loss = criterion(outputs, targets)_, predicted = torch.max(outputs.data, 1)total_train += targets.size(0)correct_train += (predicted == targets).sum().item()# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 计算训练准确率train_accuracy = 100 * correct_train / total_traintrain_acc.append(train_accuracy)# 测试模型model.eval() # 设置模型为评估模式correct_test = 0total_test = 0with torch.no_grad():for inputs, labels in DataLoader(TensorDataset(X_test_tensor, y_test_tensor), batch_size=64):outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total_test += labels.size(0)correct_test += (predicted == labels).sum().item()all_preds.extend(predicted.numpy())all_labels.extend(labels.numpy())# 计算测试准确率test_accuracy = 100 * correct_test / total_testtest_acc.append(test_accuracy)# 每个epoch打印训练和测试的损失和准确率print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}, Train Acc: {train_accuracy:.2f}%, Test Acc: {test_accuracy:.2f}%')# 绘制训练和测试准确率图
plt.figure(figsize=(10, 5))
plt.plot(range(1, num_epochs+1), train_acc, label='Train Accuracy')
plt.plot(range(1, num_epochs+1), test_acc, label='Test Accuracy')
plt.title('Accuracy over epochs')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show()# 计算混淆矩阵
cm = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.show()