seo 公司长沙排名优化公司
上节我们介绍了空间转录组数据分析中常见的细胞邻域分析,CN计算过程中定义是否为细胞邻居的方法有两种,一种是上节我们使用固定K最近邻方法(fixed k-nearest neighbors)定义细胞Neighborhood,今天我们介绍另外一种固定半径范围内(fixed radius)内细胞的方法定义CN的方法。
计算方法
-
无监督邻域分析
-
邻近窗口构建:以每个细胞为中心,计算其一定半径范围(radius)内细胞的物理距离,形成局部窗口。
-
K-means聚类:将所有窗口的细胞类型组成进行聚类,识别出具有相似细胞类型组成的空间区域,即邻域。
-
富集分析:通过超几何检验(hypergeometric test)评估每个邻域中特定细胞类型的富集程度。公式如下:
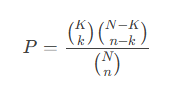
-
其中,N为总细胞数,K为某细胞类型的总数量,n为邻域内细胞数,k为邻域内该细胞类型的数量。通过Benjamini-Hochberg方法校正多重假设检验的p值。
-
-
邻域注释
根据富集的细胞类型和已知生物学知识(如动脉、内骨膜的位置),为每个聚类赋予生物学意义的名称(如“早期髓系-动脉邻域”)。
fixed radius neighbors
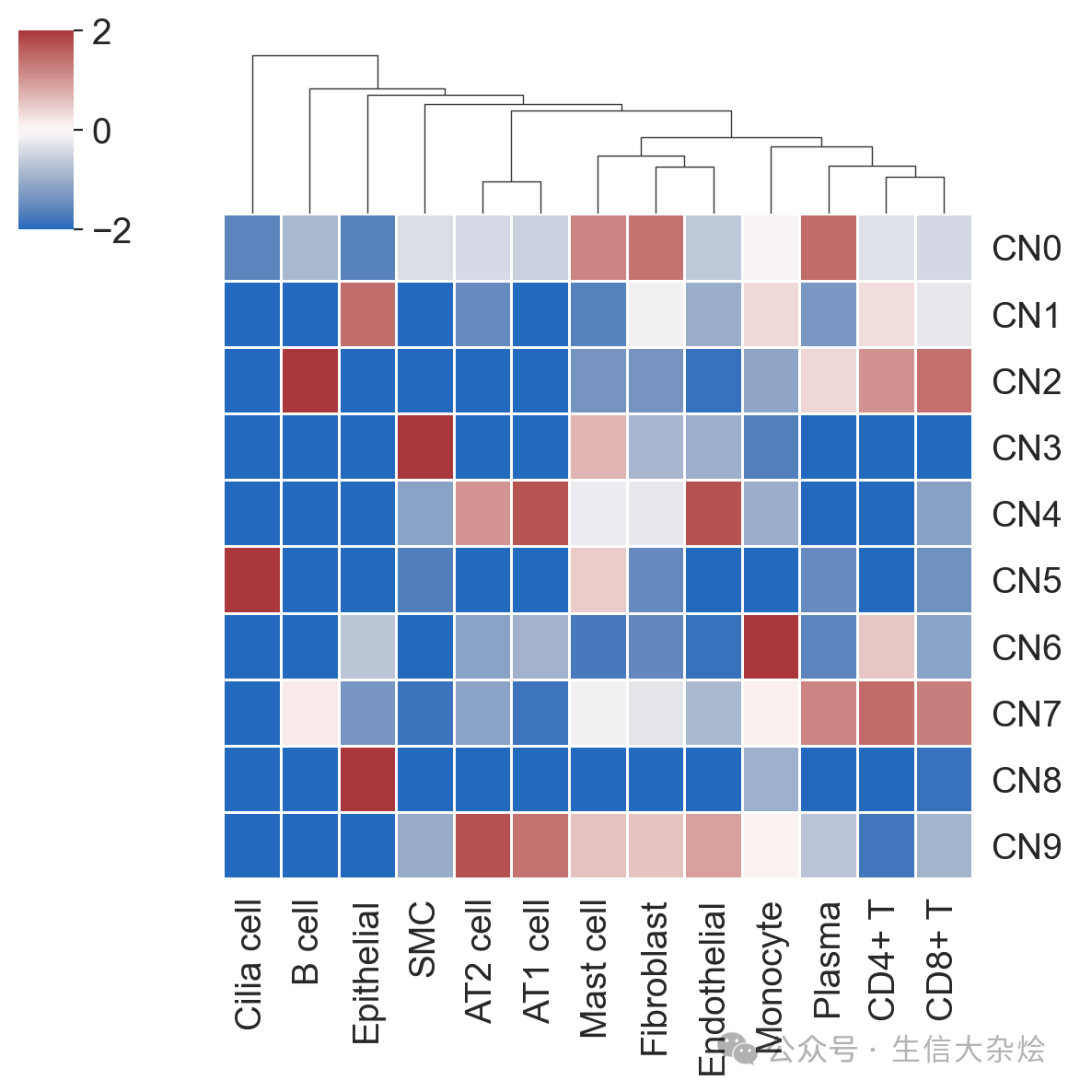
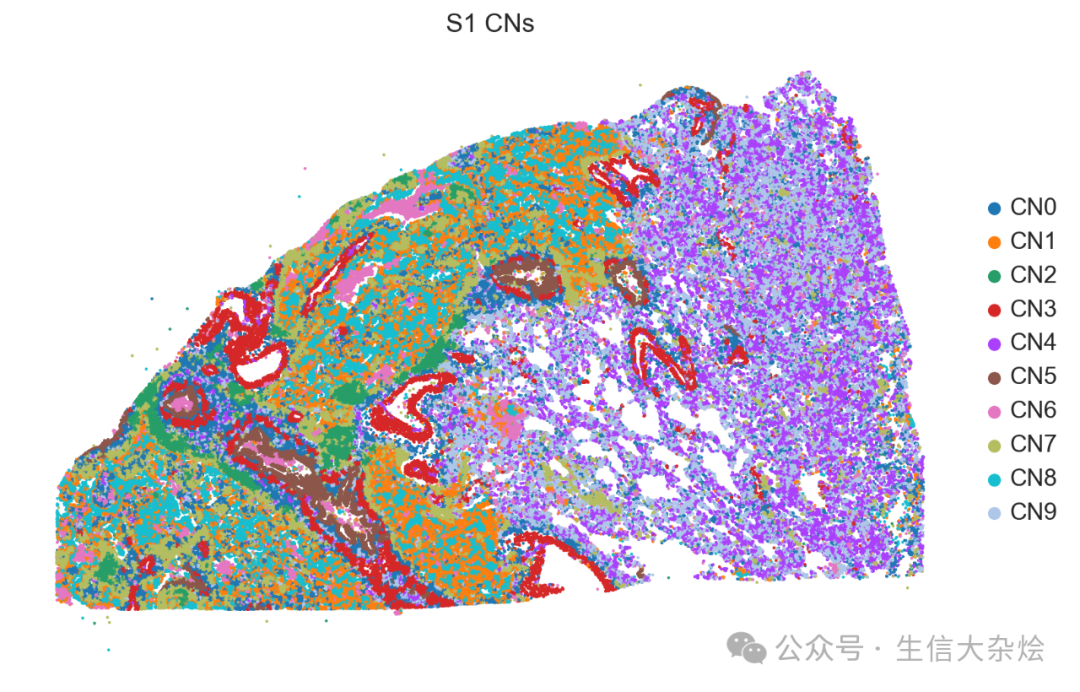
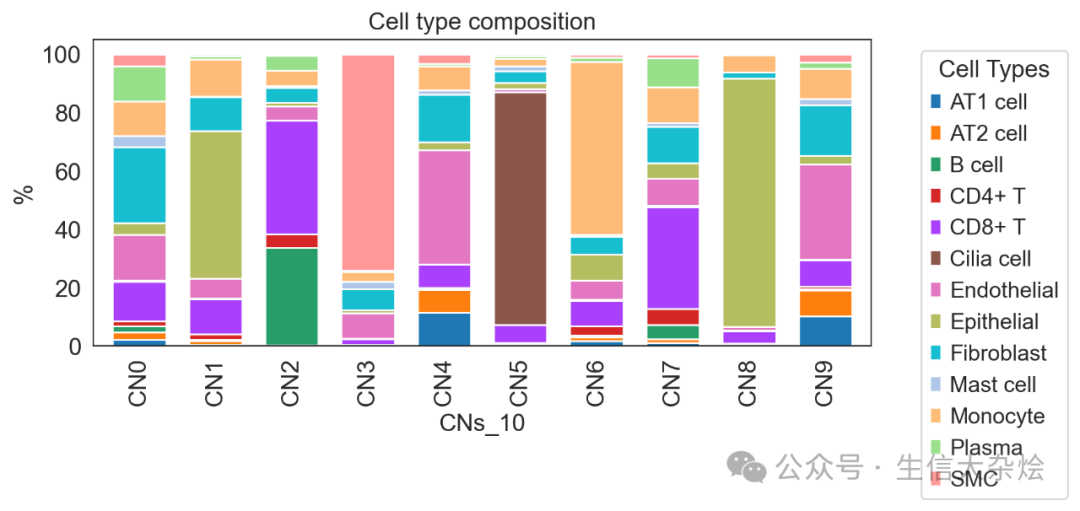
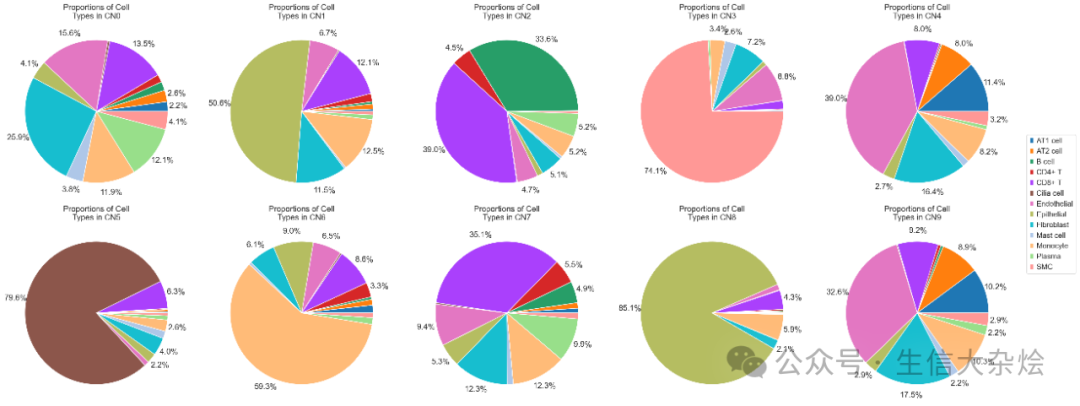
def cell_neighbors(adata, column, radius=20, n_clusters=10):"""基于半径搜索细胞邻域并聚类细胞邻域类型Parameters----------adata : AnnData包含空间转录组数据的对象column : str细胞类型或分组的列名(存储在 `adata.obs` 中)radius : float, default=10空间邻居搜索半径(单位需与坐标一致)n_clusters : int, default=10邻域聚类数量Returns-------adata : AnnData更新后的对象,邻域聚类结果存储在 `adata.obs[f'CNs_{n_clusters}']`"""# 获取空间坐标和细胞类型 one-hot 编码spatial_coords = adata.obsm['spatial']onehot_encoding = pd.get_dummies(adata.obs[column])cluster_cols = adata.obs[column].unique()values = onehot_encoding[cluster_cols].values# Step 1: 使用半径搜索邻居nbrs = NearestNeighbors(radius=radius, metric='euclidean').fit(spatial_coords)distances, indices = nbrs.radius_neighbors(spatial_coords, return_distance=True)# Step 2: 处理邻居索引(按距离排序 + 排除自身)sorted_indices = []for i in range(len(indices)):if len(indices[i]) == 0:sorted_indices.append(np.array([]))continue# 按距离排序并排除自身sorted_order = np.argsort(distances[i])neigh_indices = indices[i][sorted_order]mask = (neigh_indices != i)filtered_indices = neigh_indices[mask]sorted_indices.append(filtered_indices)# Step 3: 计算窗口和(处理稀疏区域)def compute_window_sums(sorted_indices, values):windows = []for idx in range(len(sorted_indices)):neighbors = sorted_indices[idx]if len(neighbors) == 0:# 稀疏区域处理:使用自身类型填充window_sum = values[idx] # 自身类型else:window_sum = values[neighbors].sum(axis=0)# 归一化为比例分布window_sum_norm = window_sum / (window_sum.sum() + 1e-6) # 防止零除windows.append(window_sum_norm)return np.array(windows)windows = compute_window_sums(sorted_indices, values)# Step 4: 聚类邻域类型km = MiniBatchKMeans(n_clusters=n_clusters, random_state=0)labels = km.fit_predict(windows)adata.obs[f'CNs_{n_clusters}'] = [f'CN{i}' for i in labels]# 可视化 Fold Changek_centroids = km.cluster_centers_tissue_avgs = values.mean(axis=0)fc = np.log2((k_centroids + 1e-6) / (tissue_avgs + 1e-6)) # 避免零除fc_df = pd.DataFrame(fc, columns=cluster_cols)fc_df.index = [f'CN{i}' for i in range(n_clusters)]sns.set_style("white")g = sns.clustermap(fc_df, vmin=-2, vmax=2, cmap="vlag", row_cluster=False, col_cluster=True, linewidths=0.5, figsize=(6, 6))g.ax_heatmap.tick_params(right=False, bottom=False)library_names = adata.obs['sample'].drop_duplicates()for library in library_names:with rc_context({'figure.figsize': (8, 8)}):sq.pl.spatial_scatter(adata[adata.obs['sample'] == library,:],library_id=library,color=[f'CNs_{n_clusters}'],title=f'{library} CNs',shape=None,size=1,img=True,img_alpha=0.5,use_raw=True,frameon=False)return adata