岫岩做网站如何做推广和引流
1.集成学习概述
1.1. 什么是集成学习
集成学习是一种通过组合多个模型来提高预测性能的机器学习方法。它类似于:
-
超级个体 vs 弱者联盟
-
单个复杂模型(如9次多项式函数)可能能力过强但容易过拟合
-
组合多个简单模型(如一堆1次函数)可以增强能力而不易过拟合
-
集成学习通过生成多个分类器/模型,将它们的预测结果组合起来,通常能获得优于任何单一分类器的预测性能。
1.2. 机器学习的两个核心任务
-
如何优化训练数据 - 主要用于解决欠拟合问题——booting
-
如何提升泛化性能 - 主要用于解决过拟合问题——bagging
1.3. 集成学习的两种主要方法
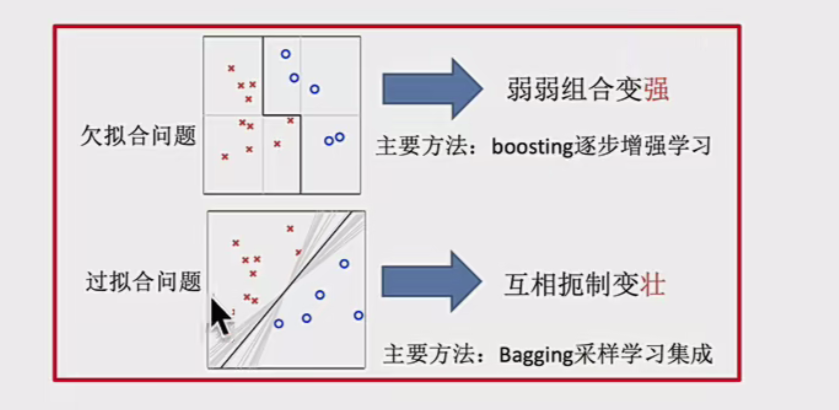
Boosting方法
-
逐步增强学习
-
通过序列化方式构建模型,每个新模型都更关注前序模型处理不好的样本(错误数据增强)
-
典型算法:AdaBoost, Gradient Boosting, XGBoost
Bagging方法
-
采样学习集成
-
通过并行方式构建多个模型,每个模型基于数据的随机子集
-
典型算法:随机森林
集成学习的关键优势是:只要单分类器的表现不太差,集成后的结果通常优于单分类器。这种方法能有效平衡模型的偏差和方差,提高泛化能力
2.Bagging和随机森林
2.1Bagging集成原理
先看一个图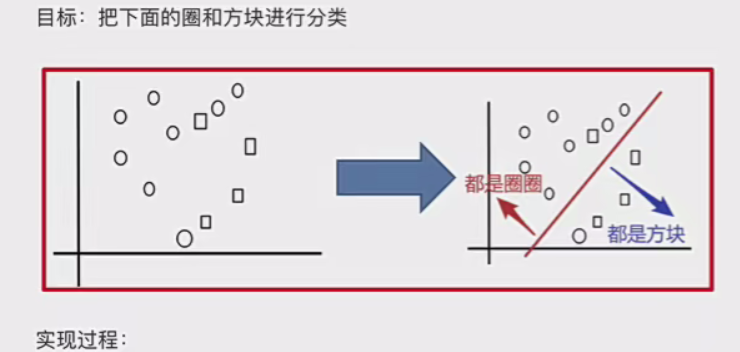
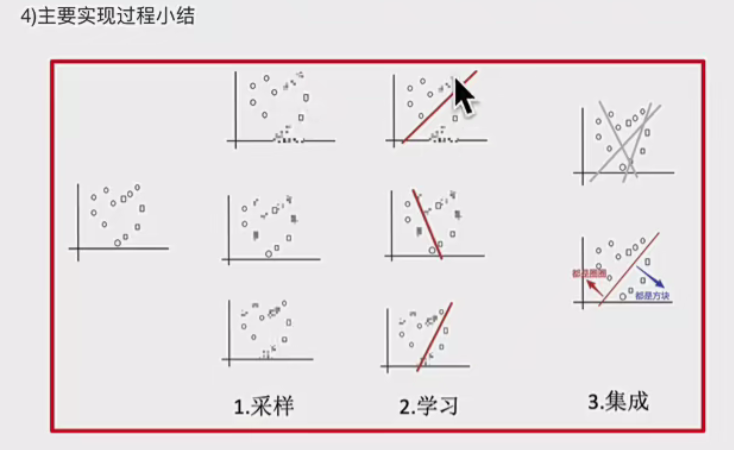
2.1.1. Bagging 基本概念
Bagging(Bootstrap Aggregating,自助聚合)是一种并行式集成学习方法,通过构建多个相互独立的基学习器,并综合它们的预测结果来提高模型的泛化能力。
核心思想:
-
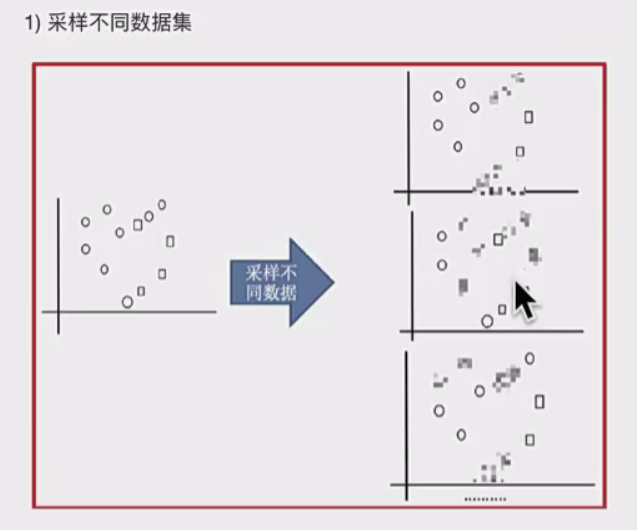
Bootstrap(自助采样):从训练数据中有放回地随机抽取多个子集,每个子集用于训练一个基学习器。
-
Aggregating(聚合):所有基学习器的预测结果通过投票(分类)或平均(回归)进行集成,得到最终预测。
📌 关键特点:
适用于高方差、低偏差的模型(如决策树、神经网络)。
能有效降低方差,减少过拟合风险。(可以理解因为你随机选取数据)
2.1.2. Bagging 算法流程
-
自助采样(Bootstrap Sampling)
-
从原始训练集 DD 中有放回地随机抽取 mm 个样本,构成一个子集 DiDi。
-
重复该过程 TT 次,得到 TT 个不同的训练子集。
-
-
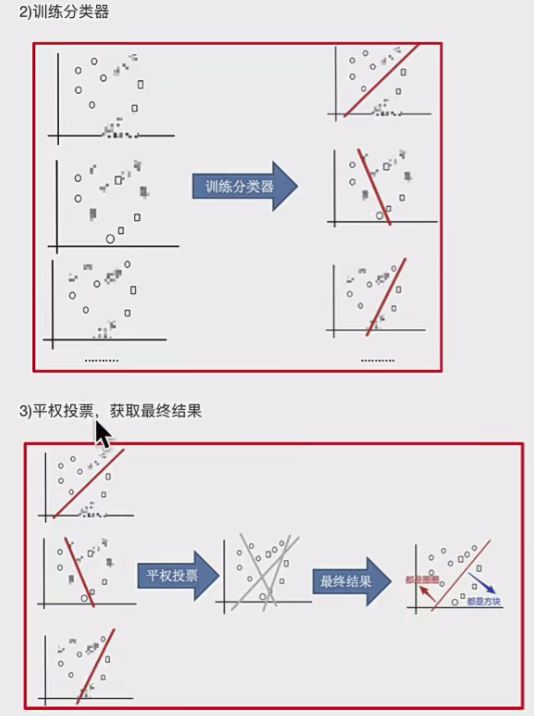
基学习器训练
-
每个子集 DiDi 训练一个基学习器(如决策树)。
-
基学习器之间相互独立(可并行训练)。
-
-
集成预测
-
分类任务:采用投票法(多数表决)
-
回归任务:采用平均法(取均值)
-
2.1.3. Bagging 的典型算法:随机森林(Random Forest)
-
改进点:不仅对样本进行自助采样,还对特征进行随机选择(进一步降低相关性)。
-
优势:
-
比普通 Bagging 更鲁棒,抗过拟合能力更强。
-
能处理高维数据,适用于分类和回归任务。
-
2.1.4. Bagging 的优缺点
✅ 优点
-
有效减少方差,防止过拟合。
-
适用于高噪声数据,鲁棒性强。
-
可并行训练,计算效率高。
❌ 缺点
-
对低偏差、高方差的模型(如线性回归)提升有限。
-
如果基学习器本身偏差较大,Bagging 可能无法显著提升性能。
2.2随机森林
2.2.1. 随机森林的核心概念
随机森林是一种基于 Bagging + 决策树(基学习器是决策树) 的集成学习方法,通过构建多棵决策树并综合它们的预测结果来提高模型的泛化能力。
2.2.2核心特点:
双重随机性:样本随机(自助采样),特征随机(随机选择部分特征)
投票机制:分类任务:众数投票(多数表决),回归任务:均值预测
2.2.3构造过程:
2.2.4关键问题解答
Q1:为什么要随机抽样训练集?
-
如果所有树使用相同的训练数据,会导致所有树高度相似,失去集成的意义。
-
随机抽样 保证每棵树学习到数据的不同方面,提高多样性。
Q2:为什么要有放回地抽样?
-
无放回抽样会导致每棵树的训练数据完全不同,可能引入偏差。
-
有放回抽样 使不同树的数据分布相似但不相同,平衡偏差与方差。
2.3包外估计(之前讲的自助法)

5. 实际应用示例
(1)随机森林的 OOB 误差计算
from sklearn.ensemble import RandomForestClassifier# 启用 OOB 估计
model = RandomForestClassifier(n_estimators=100, oob_score=True)
model.fit(X_train, y_train)# 输出 OOB 准确率
print("OOB Score:", model.oob_score_)(2)特征重要性可视化
import matplotlib.pyplot as plt# 获取特征重要性
importances = model.feature_importances_# 可视化
plt.barh(range(X.shape[1]), importances)
plt.yticks(range(X.shape[1]), X.columns)
plt.show()6. 关键问题
包外数据能完全替代验证集吗?
可以:在随机森林中,OOB 估计已被证明是无偏的。但:对于超参数调优,建议结合交叉验证。
2.4随机森林API和案例
还是和以前一样,先实例化后使用


案例:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.datasets import load_breast_cancer # 示例数据集# 1. 加载数据(这里使用sklearn自带的乳腺癌数据集作为示例)
data = load_breast_cancer()
X = data.data
y = data.target# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 初始化随机森林分类器(启用OOB估计)
rf = RandomForestClassifier(oob_score=True, random_state=42)# 4. 定义超参数网格
param_grid = {"n_estimators": [120, 200, 300, 500, 800, 1200],"max_depth": [5, 8, 15, 25, 30],"max_features": ["sqrt", "log2"] # 添加特征选择方式
}# 5. 使用GridSearchCV进行超参数调优
gc = GridSearchCV(estimator=rf,param_grid=param_grid,cv=5, # 使用5折交叉验证n_jobs=-1, # 使用所有CPU核心verbose=2 # 显示详细日志
)# 6. 训练模型
gc.fit(X_train, y_train)# 7. 输出最佳参数和模型评估结果
print("\n=== 最佳参数组合 ===")
print(gc.best_params_)print("\n=== 模型评估 ===")
print(f"测试集准确率: {gc.score(X_test, y_test):.4f}")# 8. 获取最佳模型并输出OOB得分
best_rf = gc.best_estimator_
print(f"包外估计(OOB)得分: {best_rf.oob_score_:.4f}")3.通过一个案例,来看一下我们拿到一个数据如何分析:
3.1题目介绍
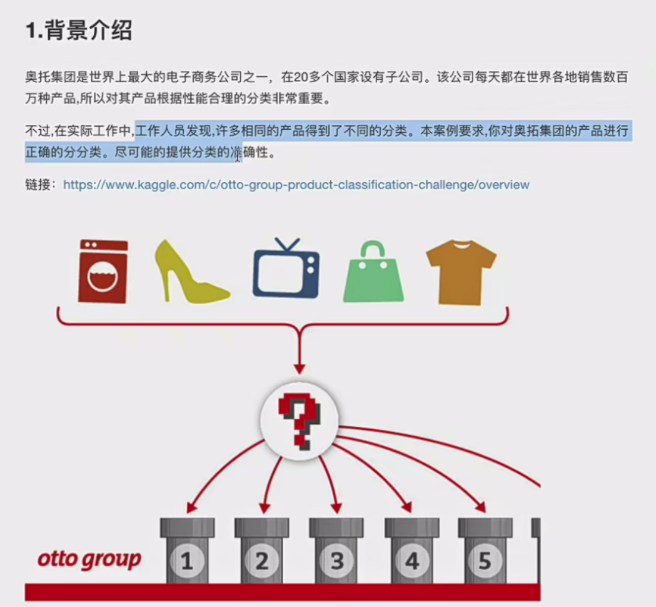
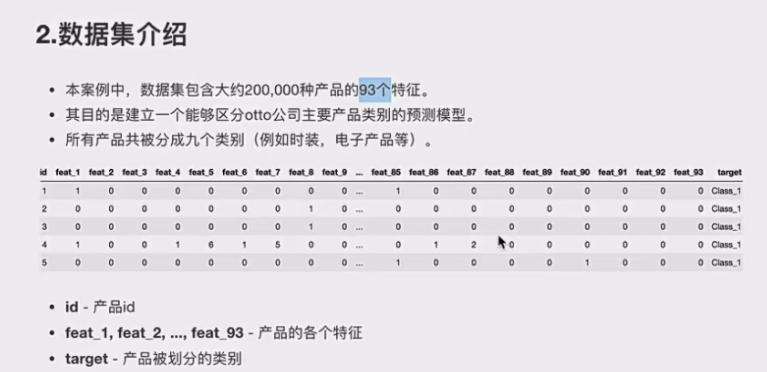
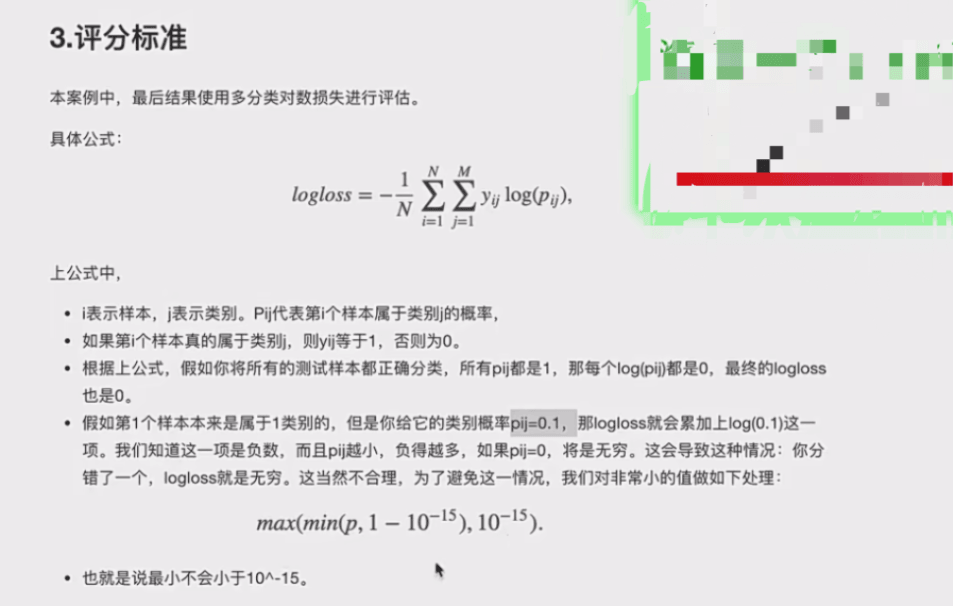 3.2题目分析:我说一下目前了解到的各个部分
3.2题目分析:我说一下目前了解到的各个部分
3.1获取数据
数据描述,可视化
3.2数据基本处理:选取特征值(部分特征值无用,比如id),对于类别不平衡数据的处理(过采样和欠采样),缺失值和异常值的处理,分割数据,将标签值转化为数字(这个案例里会讲)只有进行数据的可视化才能看到数据是否平衡,有无异常值等,所以可视化很重要。
3.3特征处理:特征预处理(归一化,标准化),特征提取(字典特征提取,文本特征提取,图像特征提取),将类别特征转换为One-hot编码。
3.4模型训练:实际上涉及到参数调优,如果算力够强使用交叉验证和网格搜索即可,不行的话可以一个一个来,我们这个案例就是。
3.5模型评估
3.3代码实现
获取数据,以及数据描述:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.utils import class_weight# 加载数据
data = pd.read_csv('./data/otto/train.csv')# 查看数据形状
print(f"数据集形状: {data.shape}") # (61878, 95)# 查看数据概览
print(data.describe())# 可视化类别分布
plt.figure(figsize=(12, 6))
sns.countplot(x='target', data=data)
plt.title('类别分布情况')
plt.xticks(rotation=45)
plt.show()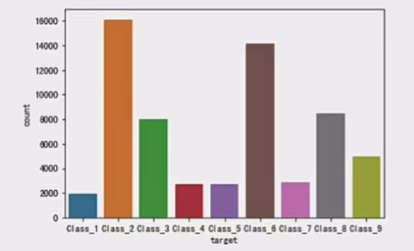
可以看到标签值是一个不平衡数据,所以需要进行处理。
数据预处理
(1)确定特征值和标签值
# 首先需要确定特征值\标签值
y = data["target"]
x = data.drop(["id", "target"], axis=1)(2)类别不平衡问题处理
# 欠采样获取数据
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_resampled, y_resampled = rus.fit_resample(x, y)# 图形可视化,查看数据分布
import seaborn as sns
sns.countplot(y_resampled)
plt.show() 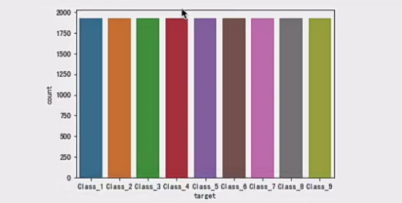
看到处理完毕,并且 类别平衡。
(3)标签值的转化
使用转换器即可
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_resampled = le.fit_transform(y_resampled)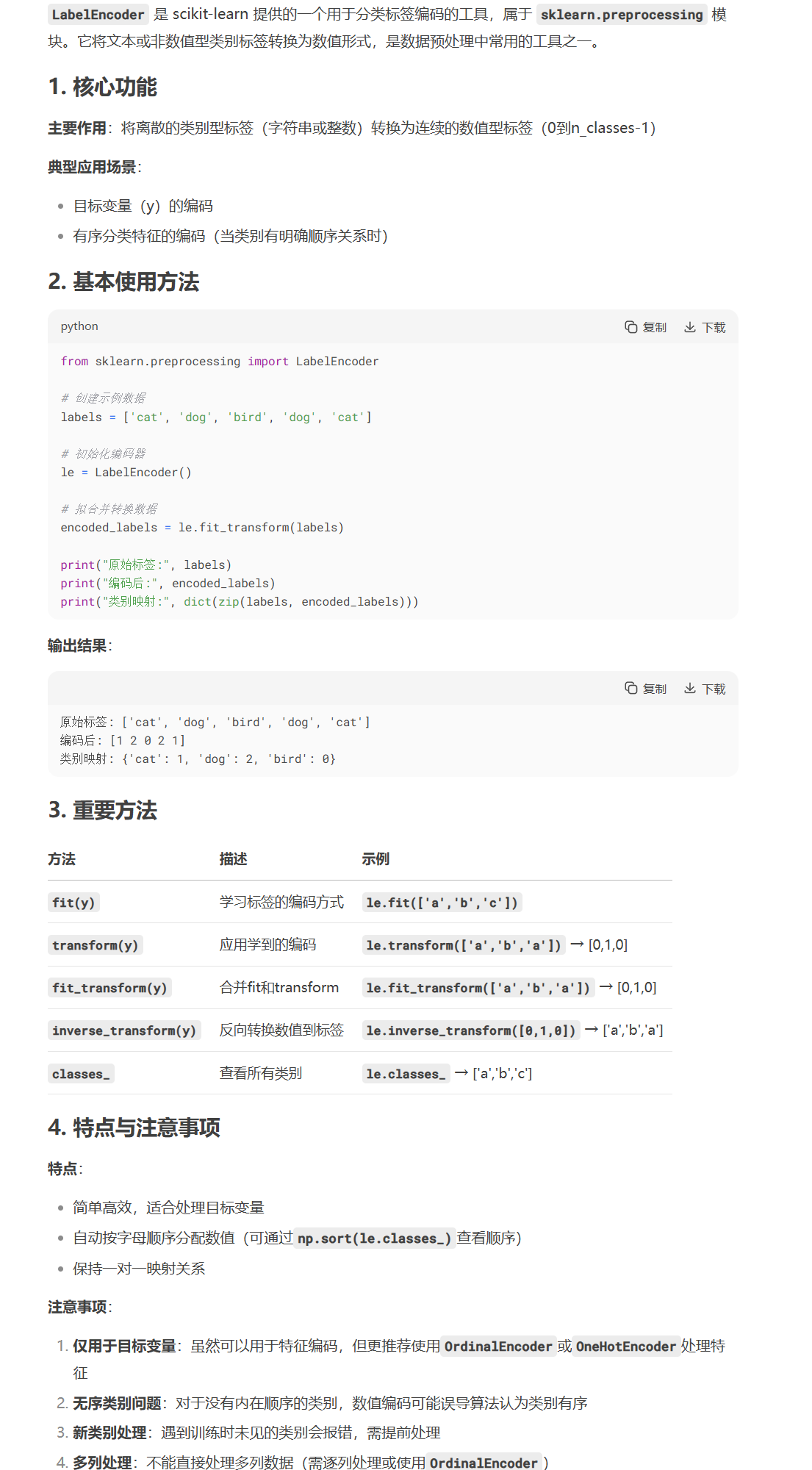
(4)分割数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2)特征工程 这个数据全是0-1数据,是被脱敏处理过后的数据,无需再进行处理
模型训练与评估(这里要使用要求的损失函数)
# 模型训练
rf = RandomForestClassifier(oob_score=True)#使用包外估计
rf.fit(x_train, y_train)# 模型预测
y_pre = rf.predict(x_test)# 计算模型准确率
accuracy = rf.score(x_test, y_test)
print(f"模型在测试集上的准确率: {accuracy}")# 查看袋外分数
oob_score = rf.oob_score_
print(f"模型的包外估计分数: {oob_score}")
按要求评估:
from sklearn.metrics import log_loss
log_loss(y_test, y_pre, eps=1e-15, normalize=True)
#normalize是将损失进行归一化但我们会发现这样会报错,因为 这个评估函数要求输入是一堆矩阵,y_test是一个one-hot编码矩阵,后面的也要求是相应的大小。于是我们更改方式:
from sklearn.preprocessing import OneHotEncoder
one_hot = OneHotEncoder(sparse=False)#不是密集矩阵y_test1 = one_hot.fit_transform(y_test.reshape(-1, 1))
y_pre1 = one_hot.fit_transform(y_pre.reshape(-1, 1))对于
y_test.reshape(-1, 1):y_test原本可能是一维数组,reshape(-1, 1)将其转换为二维列向量形式,因为OneHotEncoder要求输入数据是二维数组。
这样就可以了吗,但是我们可以通过将预测值的那个矩阵替换为概率矩阵,就是每一行代表一个样本,每一列是代表这个样本属于这个类别的概率:这样会降低特别大
# 改变预测值的输出模式,让输出结果为百分比概率
y_pre_proba = rf.predict_proba(x_test)# 再次查看袋外分数
oob_score = rf.oob_score_
print(f"模型的袋外分数: {oob_score}")# 第二次 logloss 模型评估
log_loss_value_2 = log_loss(y_test1, y_pre_proba, eps=1e-15, normalize=True)
print(f"第二次计算的 log_loss 值: {log_loss_value_2}")参数调优 最好使用网格搜索的方法,当算力小的时候可以如下调优
# 确定n_estimators的取值范围
tuned_parameters = range(10, 200, 10)
# 创建添加存放accuracy的一个numpy数组
accuracy_t = np.zeros(len(tuned_parameters))
# 创建添加error的一个numpy数组(就是要求的损失函数数组)
error_t = np.zeros(len(tuned_parameters))
# 调优过程实现
for j, one_parameter in enumerate(tuned_parameters):rf2 = RandomForestClassifier(n_estimators=one_parameter,max_depth=10,max_features=10,min_samples_leaf=10,oob_score=True,random_state=0,n_jobs=-1)rf2.fit(x_train, y_train)# 输出accuracyaccuracy_t[j] = rf2.oob_score_# 输出log_lossy_pre = rf2.predict_proba(x_test)error_t[j] = log_loss(y_test, y_pre, eps=1e-15, normalize=True)print(error_t)# 优化结果过程可视化
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 4), dpi=100)
axes[0].plot(tuned_parameters, error_t)
axes[1].plot(tuned_parameters, accuracy_t)
axes[0].set_xlabel("n_estimators")
axes[0].set_ylabel("error_t")
axes[1].set_xlabel("n_estimators")
axes[1].set_ylabel("accuracy_t")
axes[0].grid(True)
axes[1].grid(True)
plt.show()for j, one_parameter in enumerate(tuned_parameters):相当于给原本的要调优的值加了一个从0开始的索引,方便把每个值存到数组里
注意我们并不是选取数组里最小的作为最优调参,而是通过绘图查看趋势,通常选取趋势平缓的转折点
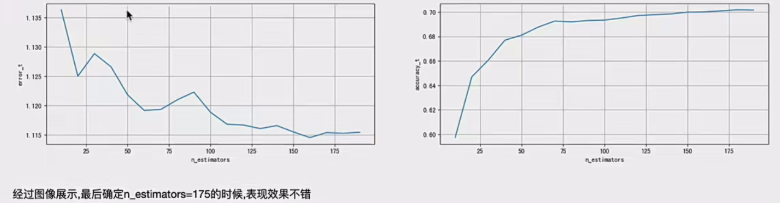
之后我们固定这个参数,继续进行调优,直到全部调优完毕!