网站建设品牌推荐公众号开发
整理下全部逻辑的先后顺序,看看能不能制作出适合所有机器学习的通用pipeline
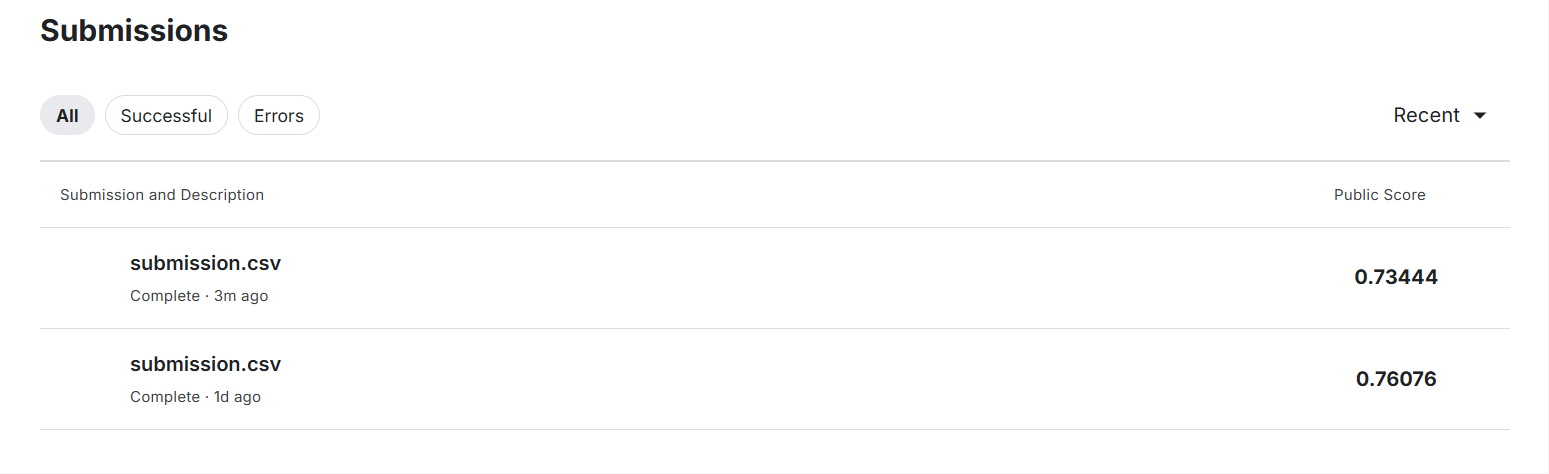
用昨天的Titanic又提交了一遍,也算是pipeline吧,换了个模型准确率下降了。。
import pandas as pd
import numpy as np
import re
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
import warningswarnings.filterwarnings("ignore")# 统一的预处理函数
def preprocess_data(df):# 1. 填充Age缺失值(用训练集中位数填充)median_age = preprocess_data.median_age if hasattr(preprocess_data, 'median_age') else df['Age'].median()df['Age'].fillna(median_age, inplace=True)preprocess_data.median_age = median_age # 记录中位数以便测试集使用# 2. 填充Embarked缺失值(用训练集众数填充)mode_embarked = preprocess_data.mode_embarked if hasattr(preprocess_data, 'mode_embarked') else df['Embarked'].mode()[0]df['Embarked'].fillna(mode_embarked, inplace=True)preprocess_data.mode_embarked = mode_embarked# 3. 新增Deck列(取Cabin首字母),缺失填'Unknown'df['Deck'] = df['Cabin'].str[0].fillna('Unknown')# 4. 新增Cabin_Missing列(Cabin是否缺失)df['Cabin_Missing'] = df['Cabin'].isnull().astype(int)# 5. 删除Cabin列df.drop(columns=['Cabin'], inplace=True)# 6. 性别转换为数字列 is_maledf['is_male'] = (df['Sex'] == 'male').astype(int)df.drop(columns=['Sex'], inplace=True)# 7. Embarked独热编码embarked_dummies = pd.get_dummies(df['Embarked'], prefix='Embarked', dtype=int)df = pd.concat([df, embarked_dummies], axis=1)df.drop(columns=['Embarked'], inplace=True)# 8. Ticket类型特征提取def ticket_type(ticket):if pd.isnull(ticket):return 'Unknown'elif ticket.isdigit():return 'Numeric'elif re.match(r'^[A-Za-z\. ]+', ticket):return 'Alphanumeric'else:return 'Other'df['TicketType'] = df['Ticket'].apply(ticket_type)ticket_counts = df['Ticket'].value_counts()df['sharing_number'] = df['Ticket'].map(ticket_counts)df.drop(columns=['Ticket'], inplace=True)ticket_dummies = pd.get_dummies(df['TicketType'], prefix='Ticket', dtype=int)df = pd.concat([df, ticket_dummies], axis=1)df.drop(columns=['TicketType'], inplace=True)# 9. Deck映射为序号,缺失用众数填充deck_order = {'A': 1, 'B': 2, 'C': 3, 'D': 4,'E': 5, 'F': 6, 'G': 7, 'T': 8, 'Unknown': 0}df['Deck_Ordinal'] = df['Deck'].map(deck_order)mode_deck = preprocess_data.mode_deck if hasattr(preprocess_data, 'mode_deck') else df['Deck_Ordinal'].mode()[0]df['Deck_Ordinal'].fillna(mode_deck, inplace=True)preprocess_data.mode_deck = mode_deckdf.drop(columns=['Deck'], inplace=True)# 10. 删除Name列(无用)if 'Name' in df.columns:df.drop(columns=['Name'], inplace=True)# 11. 删除PassengerId列(如果有,预测时用)# 这里不删,保留传外面return df# === 读取训练数据 ===
train_data = pd.read_csv('train.csv')# 记录训练集PassengerId(一般训练时不用)
if 'PassengerId' in train_data.columns:train_passenger_ids = train_data['PassengerId']# 预处理训练数据
train_processed = preprocess_data(train_data)# 准备训练特征和标签
X = train_processed.drop(columns=['Survived', 'PassengerId'], errors='ignore')
y = train_processed['Survived']# 划分训练/验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)# === 训练XGBoost模型 ===
xgb_model = xgb.XGBClassifier(random_state=42, use_label_encoder=False, eval_metric='logloss')
xgb_model.fit(X_train, y_train)# 验证集预测和评估
y_val_pred = xgb_model.predict(X_val)
print("验证集分类报告:")
print(classification_report(y_val, y_val_pred))
print("验证集混淆矩阵:")
print(confusion_matrix(y_val, y_val_pred))# === 读取测试数据 ===
test_data = pd.read_csv('test.csv')
passenger_ids = test_data['PassengerId'] # 保留乘客ID用于提交# 预处理测试数据(用训练集统计量填充)
test_processed = preprocess_data(test_data)# 确保预测数据列与训练特征一致,删除PassengerId列
test_processed = test_processed.drop(columns=['PassengerId'], errors='ignore')# 对测试数据的列补齐(训练集里有,测试集没的列补0)
for col in X.columns:if col not in test_processed.columns:test_processed[col] = 0# 测试数据列顺序对齐训练集
test_processed = test_processed[X.columns]# 预测测试集
test_preds = xgb_model.predict(test_processed)# 保存预测结果到csv
submission = pd.DataFrame({'PassengerId': passenger_ids,'Survived': test_preds
})
submission.to_csv('submission.csv', index=False)
print("预测结果已保存到 submission.csv")
@浙大疏锦行