南京网站建设网seo销售是做什么的
启动命令

主要脚本是datax.py。可以简单看一下。添加 _**print(startCommand)� **_在指定的地方。
在bin目录下面执行_python3 datax.py …/job/job.json_打印出完整的java启动命令
java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/log -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/log -Dloglevel=info -Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax -Dlogback.configurationFile=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/conf/logback.xml -classpath /Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/lib/*:. -Dlog.file.name=x_datax_job_job_json com.alibaba.datax.core.Engine -mode standalone -jobid -1 -job /Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/job/job.json
可以看到程序的入口类是com.alibaba.datax.core.Engine
执行参数是-mode standalone -jobid -1 -job /Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/job/job.json
jvm参数是-server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/log -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/log -Dloglevel=info -Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax -Dlogback.configurationFile=/Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/conf/logback.xml -classpath /Users/xiaonaibao/Documents/upupup/DataX-master/target/datax/datax/lib/*:. -Dlog.file.name=x_datax_job_job_json
将上面的参数配置到idea的里面,就可以开始debug了

debug开始

生成任务参数

主要代码:
public static Configuration parse(final String jobPath) {//解析job配置Configuration configuration = ConfigParser.parseJobConfig(jobPath);//合并框架配置core.json,出现配置重复情况不覆盖configuration.merge(ConfigParser.parseCoreConfig(CoreConstant.DATAX_CONF_PATH),false);// todo config优化,只捕获需要的pluginString readerPluginName = configuration.getString(CoreConstant.DATAX_JOB_CONTENT_READER_NAME);String writerPluginName = configuration.getString(CoreConstant.DATAX_JOB_CONTENT_WRITER_NAME);String preHandlerName = configuration.getString(CoreConstant.DATAX_JOB_PREHANDLER_PLUGINNAME);String postHandlerName = configuration.getString(CoreConstant.DATAX_JOB_POSTHANDLER_PLUGINNAME);Set<String> pluginList = new HashSet<String>();pluginList.add(readerPluginName);pluginList.add(writerPluginName);if(StringUtils.isNotEmpty(preHandlerName)) {pluginList.add(preHandlerName);}if(StringUtils.isNotEmpty(postHandlerName)) {pluginList.add(postHandlerName);}try {//合并plugin相关配置configuration.merge(parsePluginConfig(new ArrayList<String>(pluginList)), false);}catch (Exception e){//吞掉异常,保持log干净。这里message足够。LOG.warn(String.format("插件[%s,%s]加载失败,1s后重试... Exception:%s ", readerPluginName, writerPluginName, e.getMessage()));try {Thread.sleep(1000);} catch (InterruptedException e1) {//}configuration.merge(parsePluginConfig(new ArrayList<String>(pluginList)), false);}return configuration;}
最终生成参数如下:

job来自 job/job.json
core、common、entry来自 conf/core.json
plugin来自对应读写插件的plugin.json
配置优先级:job.json>core.json>plugin.json
开始启动


主要代码:
/*** jobContainer主要负责的工作全部在start()里面,包括init、prepare、split、scheduler、* post以及destroy和statistics*/@Overridepublic void start() {LOG.info("DataX jobContainer starts job.");boolean hasException = false;boolean isDryRun = false;try {this.startTimeStamp = System.currentTimeMillis();isDryRun = configuration.getBool(CoreConstant.DATAX_JOB_SETTING_DRYRUN, false);if(isDryRun) {LOG.info("jobContainer starts to do preCheck ...");this.preCheck();} else {userConf = configuration.clone();LOG.debug("jobContainer starts to do preHandle ...");this.preHandle();LOG.debug("jobContainer starts to do init ...");this.init();LOG.info("jobContainer starts to do prepare ...");this.prepare();LOG.info("jobContainer starts to do split ...");this.totalStage = this.split();LOG.info("jobContainer starts to do schedule ...");this.schedule();LOG.debug("jobContainer starts to do post ...");this.post();LOG.debug("jobContainer starts to do postHandle ...");this.postHandle();LOG.info("DataX jobId [{}] completed successfully.", this.jobId);this.invokeHooks();}} catch (Throwable e) {...} finally {...}
jobContainer主要负责的工作全部在start()里面,包括init、prepare、split、scheduler、post以及destroy和statistics。是最主要的组件。
插件加载




根据插件的配置文件plugin.json中的class�,使用反射加载对应的类的

name是插件的唯一标识,不能跟别的插件重复。class的是对应的类名称。
init、prepare、post、destroy�都会调用对应插件的方法。

任务切分


通道(并发)、记录流、字节流三种流控模式。用来计算切分的任务数量。
"speed": {"channel": 5,"byte": 1048576,"record": 10000
}
private void adjustChannelNumber() {int needChannelNumberByByte = Integer.MAX_VALUE;int needChannelNumberByRecord = Integer.MAX_VALUE;boolean isByteLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 0) > 0);if (isByteLimit) {long globalLimitedByteSpeed = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 10 * 1024 * 1024);// 在byte流控情况下,单个Channel流量最大值必须设置,否则报错!// 默认Channel流量最大值为-1,在core.json中Long channelLimitedByteSpeed = this.configuration.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_BYTE);if (channelLimitedByteSpeed == null || channelLimitedByteSpeed <= 0) {throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数");}needChannelNumberByByte =(int) (globalLimitedByteSpeed / channelLimitedByteSpeed);needChannelNumberByByte =needChannelNumberByByte > 0 ? needChannelNumberByByte : 1;LOG.info("Job set Max-Byte-Speed to " + globalLimitedByteSpeed + " bytes.");}boolean isRecordLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 0)) > 0;if (isRecordLimit) {long globalLimitedRecordSpeed = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 100000);Long channelLimitedRecordSpeed = this.configuration.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_RECORD);// 在record流控情况下,单个Channel流量最大值必须设置,否则报错!// 默认Channel流量最大值为-1,在core.json中if (channelLimitedRecordSpeed == null || channelLimitedRecordSpeed <= 0) {throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"在有总tps限速条件下,单个channel的tps值不能为空,也不能为非正数");}needChannelNumberByRecord =(int) (globalLimitedRecordSpeed / channelLimitedRecordSpeed);needChannelNumberByRecord =needChannelNumberByRecord > 0 ? needChannelNumberByRecord : 1;LOG.info("Job set Max-Record-Speed to " + globalLimitedRecordSpeed + " records.");}// 取较小值this.needChannelNumber = Math.min(needChannelNumberByByte, needChannelNumberByRecord);// 如果从byte或record上设置了needChannelNumber则退出if (this.needChannelNumber < Integer.MAX_VALUE) {return;}boolean isChannelLimit = (this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL, 0) > 0);if (isChannelLimit) {this.needChannelNumber = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);LOG.info("Job set Channel-Number to " + this.needChannelNumber+ " channels.");return;}throw DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,"Job运行速度必须设置");}
优先获取byte和record方式计算的channel数量,取较小值。最后取通道(并发)
任务调度

- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
调度taskGroup

/*** schedule首先完成的工作是把上一步reader和writer split的结果整合到具体taskGroupContainer中,* 同时不同的执行模式调用不同的调度策略,将所有任务调度起来*/private void schedule() {/*** 这里的全局speed和每个channel的速度设置为B/s* channelsPerTaskGroup默认是5,在core.json中*/int channelsPerTaskGroup = this.configuration.getInt(CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);int taskNumber = this.configuration.getList(CoreConstant.DATAX_JOB_CONTENT).size();this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);PerfTrace.getInstance().setChannelNumber(needChannelNumber);/*** 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务* 公平分配,尽量均匀分配*/List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,this.needChannelNumber, channelsPerTaskGroup);LOG.info("Scheduler starts [{}] taskGroups.", taskGroupConfigs.size());ExecuteMode executeMode = null;AbstractScheduler scheduler;try {executeMode = ExecuteMode.STANDALONE;scheduler = initStandaloneScheduler(this.configuration);//设置 executeModefor (Configuration taskGroupConfig : taskGroupConfigs) {taskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, executeMode.getValue());}if (executeMode == ExecuteMode.LOCAL || executeMode == ExecuteMode.DISTRIBUTE) {if (this.jobId <= 0) {throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR,"在[ local | distribute ]模式下必须设置jobId,并且其值 > 0 .");}}LOG.info("Running by {} Mode.", executeMode);this.startTransferTimeStamp = System.currentTimeMillis();scheduler.schedule(taskGroupConfigs);this.endTransferTimeStamp = System.currentTimeMillis();} catch (Exception e) {LOG.error("运行scheduler 模式[{}]出错.", executeMode);this.endTransferTimeStamp = System.currentTimeMillis();throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR, e);}


TaskGroupContainerRunner中启动了taskGroup:taskGroupContainer.start()

至此多个taskGroup已经成功启动,有多少个taskGroup就会立即启动多少个taskGroup。
调度task
task是由taskGroup进行调度的。同时运行的task数量不能超过channel的数量。
可以看到主要分成六步。

1.判断task状态

2.发现该taskGroup下taskExecutor的总状态失败则汇报错误

3.有任务未执行,且正在运行的任务数小于最大通道限制

4.任务列表为空,executor已结束, 搜集状态为success—>成功

5.如果当前时间已经超出汇报时间的interval,那么我们需要马上汇报
定时汇报,不能只有task报错或者全部完成才汇报。

6.最后还要汇报一次
确保所有任务的最终状态都汇报了。

Task执行
TaskExecutor是一个完整task的执行器,其中包括1:1的reader和writer
在构造器方法中分别创建读写线程。

在doStart方法中先启动writer线程,确保writer线程启动后再启动reader线程。因为reader可能很快结束,要是reader先启动,数据流动可能会乱掉,统计也不准确,channel会积压数据,

ReaderRunner读取消息
首先创建了Reader.Task(用户自己实现,用于读取的plugin),
下面就是对应的生命周期管理,init->prepare->read->post
其中在read对应是 taskReader.startRead(recordSender),使用recordSender发送消息,最后将读取完成后发送一个终止消息。

举例子:StreamReader,在startRead中是先创建一个record,再通过recordSender.sendToWriter发送消息。

recordSender发送消息
sendToWriter会先将消息缓存到buffer中,要是总条数或者总大小超过限制就发送出去。

flush是调用channel的pushAll,将消息全部写入channel。
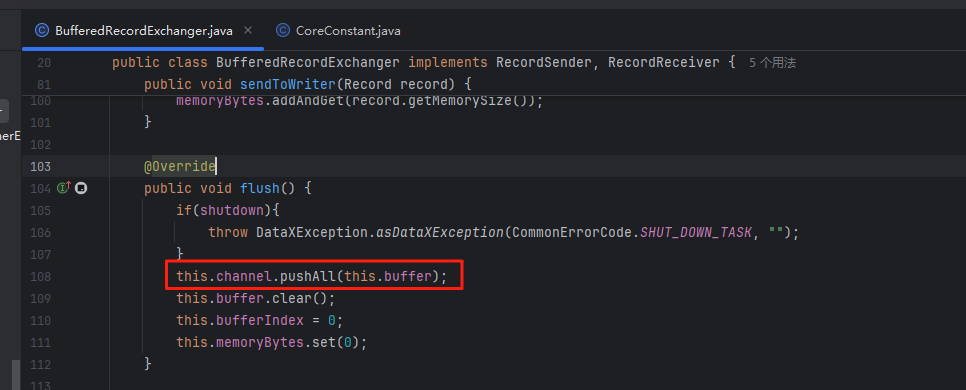
写入channel就是写入阻塞队列queue,判断队列是不是有足够空间,要是不够就阻塞。
queue已经是阻塞队列了,为什么还要在插入前判断空间不够就阻塞?
因为queue只能判断数量来阻塞,这里还需要判断消息的总字节大小来阻塞,同时这是一个批量插入操作,而addAll不是原子操作,它是一个一个插入的,插入过程就可能超过限制。


WriteRunner读取消息
跟ReaderRunner一样,但是核心方法是taskWriter.startWrite(recordReceiver);

举例子:StreamWriter
recordReceiver.getFromReader()循环获取消息

recordReceiver读取消息
从buffer中读取数据,要是buffer空了,就从channel中加载数据到buffer中。

channel从queue中获取数据,使用drainTo(批量获取,最多获取bufferSize条)

