口碑好的广州做网站东莞百度搜索网站排名
DeepResearcher:通过强化学习在真实环境中扩展深度研究
- 一、引言
- 二、技术原理
- (一)强化学习与深度研究代理
- (二)认知行为的出现
- (三)模型架构
- 三、实战运行方式
- (一)环境搭建
- (二)启动Ray
- (三)运行后端处理器
- (四)模型训练
- (五)模型评估
- 四、重要逻辑代码
- (一)模型训练代码
- (二)后端处理器代码
- 五、执行报错及解决方法
- (一)环境依赖问题
- (二)Ray启动失败
- (三)后端处理器连接失败
- 六、相关论文信息
- 七、总结
一、引言
在当今快速发展的科技时代,人工智能(AI)和机器学习(ML)技术正在不断改变我们的生活和工作方式。其中,自然语言处理(NLP)领域的发展尤为引人注目。随着大型语言模型(LLMs)的出现,如GPT系列、LLaMA等,我们看到了AI在理解和生成人类语言方面的巨大潜力。然而,这些模型在实际应用中仍然面临一些挑战,尤其是在处理复杂的、需要多步骤推理和信息检索的任务时。DeepResearcher项目正是为了解决这些问题而诞生的。
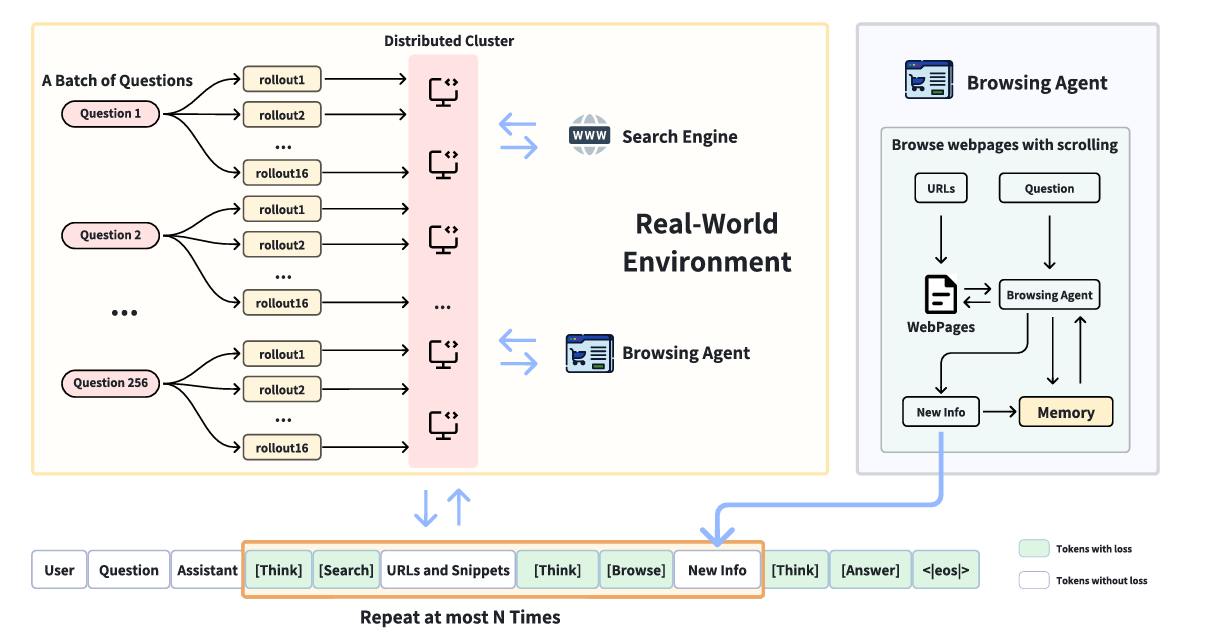
DeepResearcher是一个开创性的框架,旨在通过强化学习(RL)在真实世界环境中训练基于LLM的深度研究代理。这个项目的目标是让AI代理能够像人类研究人员一样,通过互联网搜索、信息验证和自我反思来完成复杂的任务。本文将详细介绍DeepResearcher项目的各个方面,包括其技术原理、实战运行方式、重要逻辑代码以及可能遇到的问题和解决方法。
二、技术原理
(一)强化学习与深度研究代理
强化学习是一种让智能体通过与环境的交互来学习最优行为策略的方法。在DeepResearcher中,强化学习被用来训练深度研究代理,使其能够在真实世界环境中进行有效的信息检索和任务完成。具体来说,代理通过与搜索引擎交互,获取信息,并根据反馈调整自己的行为策略。
(二)认知行为的出现
DeepResearcher的一个重要特点是它能够展示出一些类似人类的认知行为。这些行为包括:
- 制定计划:代理能够根据任务目标制定出合理的行动步骤。
- 信息交叉验证:从多个来源获取信息,并验证信息的准确性。
- 自我反思:在任务执行过程中,代理能够根据结果反思自己的行为,并调整策略。
- 诚实回答:当无法找到确切答案时,代理能够诚实地表示不知道,而不是给出错误的答案。
这些行为的出现表明,通过强化学习训练的代理不仅能够完成任务,还能够以一种更加智能和灵活的方式进行操作。
(三)模型架构
DeepResearcher目前提供了7B参数的模型版本,名为DeepResearcher-7b。这个模型基于Transformer架构,并通过强化学习进行了微调,使其能够更好地适应复杂的任务需求。
三、实战运行方式
(一)环境搭建
在开始使用DeepResearcher之前,我们需要先搭建好运行环境。以下是详细的步骤:
-
克隆项目仓库:
git clone https://github.com/GAIR-NLP/DeepResearcher.git -
创建并激活虚拟环境:
conda create -n deepresearcher python=3.10 conda activate deepresearcher -
安装依赖:
cd DeepResearcher pip3 install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu124 pip3 install flash-attn --no-build-isolation pip3 install -e . pip3 install -r requirements.txt
(二)启动Ray
Ray是一个用于分布式计算的框架,DeepResearcher使用它来进行模型训练。在开始训练之前,我们需要启动Ray。以下是启动Ray的步骤:
-
设置环境变量:
export PET_NODE_RANK=0 -
启动Ray:
ray start --head
(三)运行后端处理器
后端处理器是DeepResearcher与搜索引擎交互的关键组件。以下是运行后端处理器的步骤:
-
修改配置文件:
- 修改
./scrl/handler/config.yaml中的serper_api_key或azure_bing_search_subscription_key和search_engine。 - 在
./scrl/handler/server_handler.py中添加qwen-plusAPI密钥。
- 修改
-
启动服务器处理器:
python ./scrl/handler/server_handler.py -
启动处理器:
python ./scrl/handler/handler.py
(四)模型训练
模型训练是DeepResearcher的核心步骤。以下是训练模型的步骤:
- 准备训练数据:将训练数据放置在指定目录下。
- 运行训练脚本:使用以下命令启动训练:
python train.py
(五)模型评估
模型评估用于验证训练结果的有效性。以下是评估模型的步骤:
-
生成rollout文件:
- 在训练完成后,您可以在
./outputs/{project_name}/{experiment_name}/rollout/rollout_step_0.json中找到rollout文件。 - 将该文件重命名并复制到
./evaluate/{experiment_name}_result.json。
- 在训练完成后,您可以在
-
运行评估脚本:
python ./evaluate/cacluate_metrics.py {experiment_name} -
查看评估结果:评估结果将保存在
./evaluate/{experiment_name}_score.json中。
四、重要逻辑代码
(一)模型训练代码
以下是模型训练的核心代码片段:
# train.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from deepresearcher import DeepResearcherAgentdef train_model():# 加载预训练模型和分词器model_name = "DeepResearcher-7b"model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)# 初始化深度研究代理agent = DeepResearcherAgent(model, tokenizer)# 加载训练数据train_data = load_data("train.json")# 训练模型agent.train(train_data)if __name__ == "__main__":train_model()
(二)后端处理器代码
以下是后端处理器的核心代码片段:
# server_handler.py
from deepresearcher.handler import SearchHandlerdef start_server_handler():# 初始化搜索引擎处理器handler = SearchHandler(api_key="your_api_key", search_engine="your_search_engine")# 启动服务器handler.start_server()if __name__ == "__main__":start_server_handler()
五、执行报错及解决方法
(一)环境依赖问题
问题描述:在安装依赖时,可能会遇到某些包无法安装的问题。
解决方法:
- 确保您的网络连接正常,能够访问PyPI和conda仓库。
- 如果某些包无法安装,可以尝试使用
--pre选项安装预发布版本,或者从源代码安装。
(二)Ray启动失败
问题描述:在启动Ray时,可能会遇到错误。
解决方法:
- 确保您已经正确设置了
PET_NODE_RANK环境变量。 - 如果您使用的是多节点环境,请确保所有节点的配置正确,并且网络连接正常。
(三)后端处理器连接失败
问题描述:在运行后端处理器时,可能会遇到连接搜索引擎失败的问题。
解决方法:
- 确保您已经正确配置了API密钥和搜索引擎。
- 检查网络连接,确保您的服务器能够访问搜索引擎的API。
六、相关论文信息
DeepResearcher项目的相关论文是《DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments》。以下是论文的关键信息:
- 作者:Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu
- 年份:2025
- 论文链接:https://arxiv.org/abs/2504.03160
论文详细介绍了DeepResearcher的设计原理、技术实现和实验结果。通过阅读论文,您可以更深入地了解该项目的背景、目标和贡献。
七、总结
DeepResearcher项目通过强化学习在真实世界环境中训练基于LLM的深度研究代理,展示了AI在复杂任务处理方面的巨大潜力。通过本文的介绍,您应该对该项目的技术原理、实战运行方式、重要逻辑代码以及可能遇到的问题和解决方法有了全面的了解。希望DeepResearcher能够为您的研究和开发工作提供有价值的参考和帮助。
注意:本文中的代码片段和命令仅为示例,实际运行时可能需要根据项目文档和实际情况进行调整。在使用DeepResearcher项目时,请务必仔细阅读项目文档,以确保正确安装和使用。