哈尔滨做网站哪好html简单网页设计作品
python读取word文档 | AI应用开发
RAG中python读取word文档
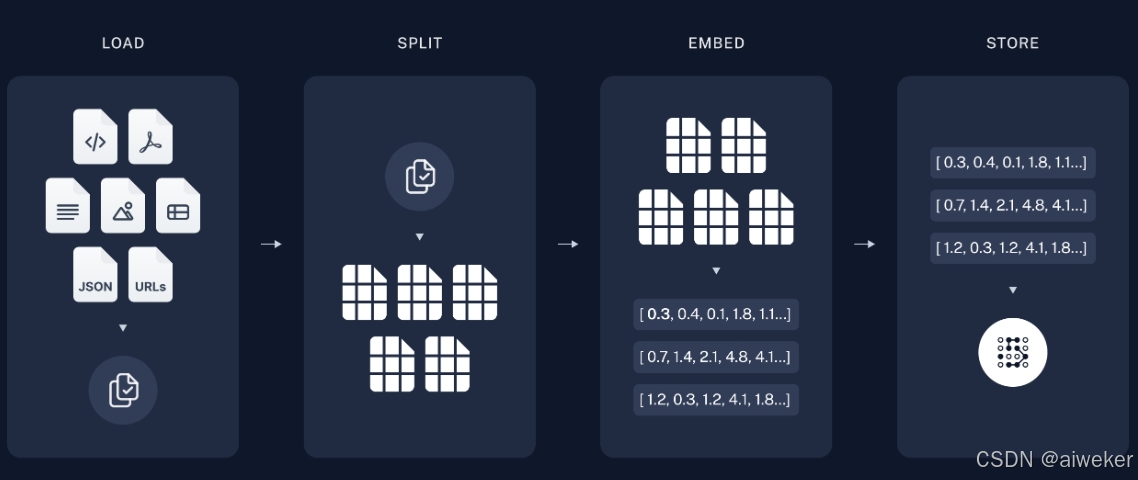
RAG系统中构建知识库流程中重要的一个步骤是读取外挂的知识文档,为word是其中比较常见的文件。
另一个值得注意的是,RAG在读取文档后需要对文档进行分割,而良好的分割需要有一定结构上支持,比如标题,段落,表格以及图片信息等。
因此,本次分享针对这些结构信息来分别读取word文档,希望对你有帮助。
利用python-docx库解析word文档
在Python中读取Word文件(.docx格式),并提取其中的标题、段落、表格、图片等内容,可以使用python-docx库。这个库提供了丰富的接口来操作Word文档。不过,需要注意的是,python-docx库目前主要支持文本、表格和图片的读取,对于Word中的样式(如标题样式)的识别,需要基于文本格式或自定义逻辑来推断。
安装python-docx
首先,你需要安装python-docx库。可以通过pip安装:
pip install python-docx
读取Word文档
以下是一个基本的示例,展示如何使用python-docx来读取Word文档中的文本、表格和图片。
读取文本和段落
from docx import Documentdef read_docx(file_path):doc = Document(file_path)for para in doc.paragraphs:print(para.text)# 使用示例
file_path = 'your_word_file.docx'
read_docx(file_path)
识别标题
由于python-docx不直接识别Word中的标题样式(如“标题1”、“标题2”等),你需要根据文本的样式或特定的格式来推断。以下是一个简单的示例,假设标题使用了特定的字体大小或加粗:
from docx.shared import Ptdef read_titles(file_path):doc = Document(file_path)for para in doc.paragraphs:if para.runs[0].font.size == Pt(24) and para.runs[0].bold: # 假设标题字体大小为24且加粗print("Title:", para.text)else:print(para.text)# 使用示例
file_path = 'your_word_file.docx'
read_titles(file_path)
注意:这个示例非常基础,实际应用中标题的识别可能需要更复杂的逻辑。
读取表格
def read_tables(file_path):doc = Document(file_path)for table in doc.tables:for row in table.rows:for cell in row.cells:print(cell.text, end=' | ')print() # 换行# 使用示例
file_path = 'your_word_file.docx'
read_tables(file_path)
读取图片
from docx.shared import Inchesdef read_images(file_path):doc = Document(file_path)for relation in doc.part.rels.values():if "image" in relation.target_ref:print(relation.target_ref) # 图片的URI# 注意:这只会给出图片的URI,不会直接加载图片。
# 若要加载图片,你可能需要额外的库(如Pillow)来根据URI下载或加载图片。# 使用示例
file_path = 'your_word_file.docx'
read_images(file_path)
注意:python-docx库对于图片的读取相对有限,它主要提供了图片的URI,而不是直接加载图片。如果你需要处理图片,可能需要结合其他库(如Pillow)来实现。
总结
python-docx库为Python提供了操作Word文档的强大功能,但需要注意的是,它并不直接识别Word中的样式(如标题样式),需要开发者根据具体情况编写逻辑来推断。此外,对于图片的读取,它主要提供图片的URI,而不直接加载图片。