网站设计项目明细曹操博客seo
预备工作
文件 = 内容 + 属性
访问文件之前,都必须先打开它,因为文件在磁盘上。访问文件时是进程在访问
我们把文件内容写完了不是打开文件,把文件编译成可执行程序也不是打开文件,只有把可执行程序执行了,打开fopen才是打开文件
进程在内存中,进程中的代码加载到内存里面,由CPU来执行,CPU读取内存,进程读取文件操作,而文件又是在磁盘中,CPU不能直接访问磁盘,所以得到结论文件必须加载到内存中!
打开文件本质就是将文件(内容或属性)从磁盘加载到内存中
OS要管理加载到内存的文件,先描述在组织,在内核中,文件 = 文件的内核数据结构+文件内容
结论:我们研究打开的文件,是在研究进程和文件的关系
文件系统 : 被打开的文件 -- 内存 没有被打开的文件 -- 磁盘
C语言的文件接口
#include<stdio.h>int main()
{FILE* fp = fopen("log.txt","w");if(fp == NULL){perror("fopen");return 1;}const char* message = "hello file\n";int i = 0;while(i < 10){fputs(message,fp);i++;}fclose(fp);return 0;
}
w:如果文件里有内容先清空,再写入
a:追加
进程默认会打开三个默认输入输出流
stdin(标准输入--键盘),stdout(标准输出--显示器),stderr(标准错误--显示器)

我们用到的C文件接口,底层必须要封装对应的文件类系统调用接口
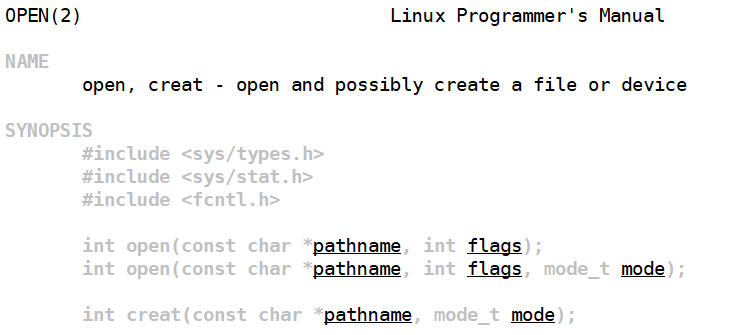
flags标志位:32bit位
O_EDONLY(只读) O_WEONLY(只写) O_EDWE(读写) O_CREAT(创建) O_APPEND(追加)
O_TRUNC(清空) 这些本质是宏,只有一个比特位为1的宏
C语言接口:fopen/fclose/fread/fwrite
系统调用接口:open/close/read/write

文件描述符fd
以下代码结果看出,open的返回值fd为3

多打印几次,发现我们的文件描述符fd是从3开始的,那0,1,2去哪里了?

进程启动时,默认打开了三个标准的输入输出流。0,1,2就被三个标准输入输出流占用了
我们用write证明一下文件描述符 1 被stdout占用了,写以下代码

调用write函数message被写到了文件描述符为1的文件中, 运行结果为message被打印在显示器中
证明了 fd=1 是 stdout . 下面代码同理:fd = 0 是 stdin

fd究竟是什么?--- "数组下标"
IO的基本过程
文件内核级缓冲区
什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输⼊设备还是输出设备,分为输⼊缓冲区和输出缓冲区
为什么要引入缓冲区机制
读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。?
为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作⼤⼤快于对磁盘的操作,故应⽤缓冲区可⼤⼤提⾼计算机的运⾏速度。
⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区是⼀块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和⾼速的CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作
C语言中的write函数,本质是拷贝函数,从用户拷贝到内核(内核文件缓冲区)

重定向
printf是向显示器打印内容,但是我们把文件描述符1关闭了,我们发现,本来应该输出到显示器上的内容,输出到了⽂件 log1.txt当中,其中,fd=1。这种现象叫做输出重定向


原理:
printf是C库当中的IO函数,⼀般往stdout中输出,但是stdout底层访问文件的时候,找的还是fd:1,但此时,fd:1下标所表示内容,已经变成log1.txt的地址,不再是显示器文件的地址,所以,输出的任何消息都会往文件中写入,进而完成输出重定向
dup2系统调用


追加重定向
![]()
输入重定向

C库函数与系统调用的区别
看以下代码:


创建子进程后,直接运行结果发现每个接口都打印了一次
把运行结果重定向到test.txt文件中,发现C库函数打印了两次,系统调用接口打印了一次
缓冲机制差异 :
C 标准库函数会用到 用户态缓冲区(属于 FILE 结构体内部实现)。默认情况下,向终端(stdout)输出时是行缓冲(遇到 \n 刷新),但如果重定向到文件,会变成全缓冲(满了才刷新)
系统调用 write:是 直接陷入内核 的系统调用,数据直接写入内核缓冲区(跳过用户态缓冲),不存在 “延迟缓冲” 的问题。
结合 fork 的行为分析
fork() 会复制整个进程的地址空间(包括用户态缓冲区里的内容)。执行流程是:
程序先执行 printf/fprintf/fwrite,由于重定向到文件是 “全缓冲”,数据没真正写入文件,而是存在父进程的用户态缓冲区里。
执行 fork(),此时子进程复制了父进程的地址空间(包括那些没刷新的缓冲区数据)。
父进程、子进程后续退出时,C 标准库会自动刷新缓冲区(把用户态缓冲的数据真正写入文件)。
所以:C库函数,重定向到文件中时,父子进程各有一份未刷新的缓冲区,退出时都会重新写入,所以最终文件里有两份输出, 直接运行时,按行刷新,父进程的缓冲区没有内容,子进程也没有
write 系统调用:它直接写内核缓冲区,fork 复制时不会带 “已写入内核的数据”(内核缓冲区不属于进程地址空间),所以不管有没有 fork,只会写入一次。