wordpress首页轮换图片在哪里设置济南seo快速霸屏
1. Q_learning 算法
Q_learning 算法是最基础强化学习算法,适用于离散状态和动作
Q_laerning 算法的本质是维护一张Q_table 表,通过不断迭代,修正Q(s,a),然后根据s,推荐s 下最大的Q 对应的动作
核心:
更新公式:
Q(s, a) ← Q(s, a) + α [r + γ * max Q(s', a') - Q(s, a)]
-
s:当前状态
-
a:当前动作
-
r:执行动作a后获得的即时奖励
-
s':执行动作a后到达的新状态
-
α:学习率,控制新旧信息的融合程度
-
γ:折扣因子,权衡未来奖励的重要性
-
max Q(s', a'):在新状态s'下,所有可能动作a'的最大Q值,决定了朝着奖励值最大的方向执行。
2.ddpg 算法
ddpg 模型适用于处理连续动作和空间的强化学习模型
核心: Actor(基于当前状态推荐动作) 和 Critc (对s和a 进行打分)
Actor_target (基于next_state,计算next_action)
Critc_target(用于计算Q,对Critc 进行优化)
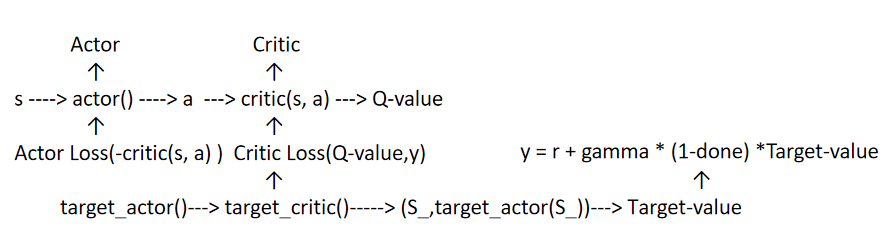
对于环境,如果存在高延迟的解决办法:
虽然传统的强化学习方法确实使用累计奖励来评估策略的好坏,但在面对延迟奖励时,这种方法可能会遇到挑战。例如,在某些任务中,关键的奖励可能只在很久之后才出现,这使得算法很难确定哪些早期的动作对最终的奖励产生了影响。这种情况被称为“信用分配问题”(credit assignment problem)。
为了解决这个问题,研究人员提出了RUDDER(Return Decomposition for Delayed Rewards)方法。RUDDER的核心思想是将延迟的奖励重新分配到那些对最终结果有关键影响的早期动作上,从而将原本延迟的奖励转化为即时奖励。这通过以下两个步骤实现:
-
回报预测:使用循环神经网络(如LSTM)对整个状态-动作序列进行建模,预测最终的总回报。
-
贡献分析:分析每个时间步的状态-动作对对最终回报的贡献程度。这可以通过技术如积分梯度(Integrated Gradients)来实现。
通过这种方式,RUDDER能够将延迟的奖励重新分配到那些关键的早期动作上,使得强化学习算法能够更有效地学习策略,尤其是在奖励稀疏或延迟的环境中。