东莞商城信阳seo
目录
前言
一、数据集:图像+文本,部分选取于DeepFashion
二、优化一,img2img
三、优化二,微调sd参数
四、优化三,dreamshaper优化
五、优化四,sdv1.5+contronet
六、问题探索历程
1. 从 SDXL 到轻量化模型:模型选择的权衡
2. LoRA 下载受阻:转向基础模型优化
3. ControlNet 约束:提升结构一致性
4. 指标评估:文件名匹配与全黑图处理
5. SSIM 计算错误:尺寸与数据范围问题
6. LPIPS 归一化调整
结果分析
总结
后续优化想法、可参考思路:
1. LoRA 微调
2. 超分辨率后处理
3. 自适应提示词
4. 损失函数优化
5. 多模型融合
由于sd v1.5生成效果一般,主要在人物面部、手部等细节上很差,于是我寻求各种优化,今天最成功的是加入contronet,这的确是一个妥妥提升质量的思路,我用的约束是轮廓图,想复现的思路除这个外,最近几天在基于 Stable Diffusion v1.5模型做优化,旨在优化图像生成质量,并通过 PSNR、SSIM 和 LPIPS 等指标对比评估不同优化方案的效果。在优化过程中,我遇到了一些技术问题,涉及模型选择、代码错误、指标计算等。以下是优化过程的详细记录,重点展示了技术问题、解决方案和实验结果。
✅ Stable Diffusion v1.5:不换模型优化人体细节的实用技巧-CSDN博客
Stable Diffusion+Pyqt5: 实现图像生成与管理界面(带保存 + 历史记录 + 删除功能)——我的实验记录(结尾附系统效果图)-CSDN博客
基于前面搭建的sd v1.5,深度学习项目记录·Stable Diffusion从零搭建、复现笔记-CSDN博客:
前言
最近围绕stable diffusion v1.5做了一系列实验,寻求各种优化,前面发的一篇是优化思路,这一篇是sd v1.5 + contronet(我采用的是边缘图,先安装opencv:pip install opencv-python依赖 cv2 来生成 Canny 边缘图),忙活几天才彻底完成各优化模型评价指标的测定,最终三个指标均有所提升。模型基于sd v1.5微调,接下来是项目思路的还原:
一、数据集:图像+文本,部分选取于DeepFashion
实验环境:python3.11 Pytorch12.1
GPU:RTX4070
二、优化一,img2img
基于原图的风格统一或提示词约束(添加细节提示)实现对生成图像再优化,上一篇提到了Strength参数作用,主要是控制实际迭代步数。
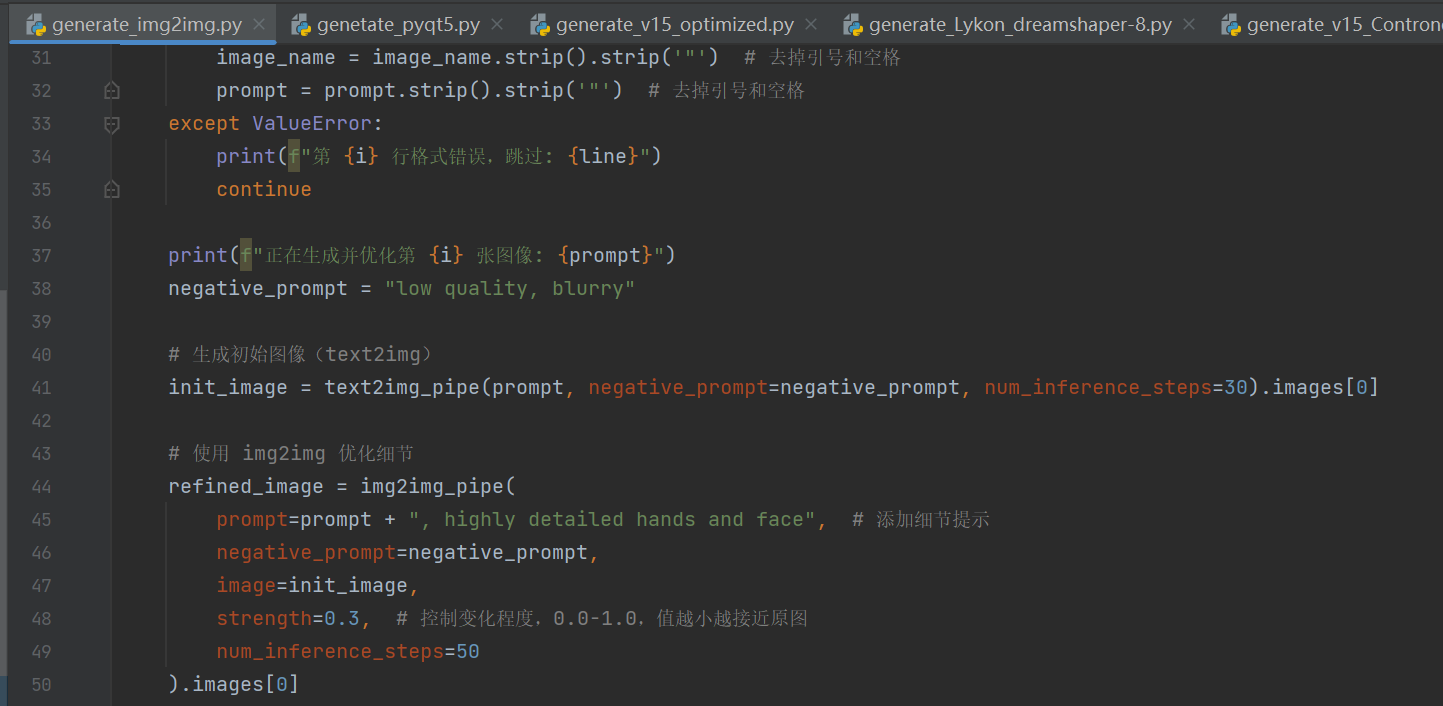
上一篇链接:Stable Diffusion+Pyqt5: 实现图像生成与管理界面(带保存 + 历史记录 + 删除功能)——我的实验记录(结尾附系统效果图)-CSDN博客
文本描述: "MEN-Denim-id_00000089-44_7_additional.jpg": "This man is wearing a short-sleeve shirt with pure color patterns. The shirt is with cotton fabric and its neckline is lapel. The trousers this man wears is of long length. The trousers are with cotton fabric and solid color patterns.",
效果:

三、优化二,微调sd参数
optimized,主要是优化迭代步数和引导强度,附加提示词优化
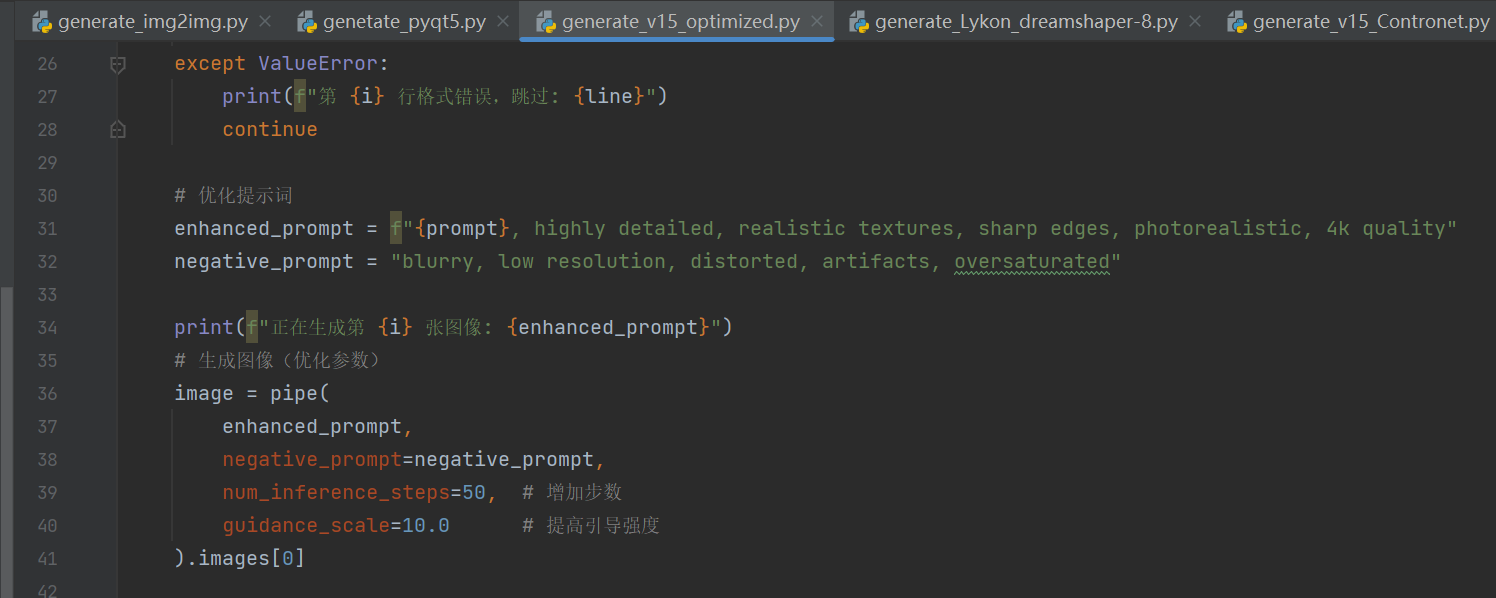
效果如下:

四、优化三,dreamshaper优化
(重新加载模型速度最慢、耗时久)
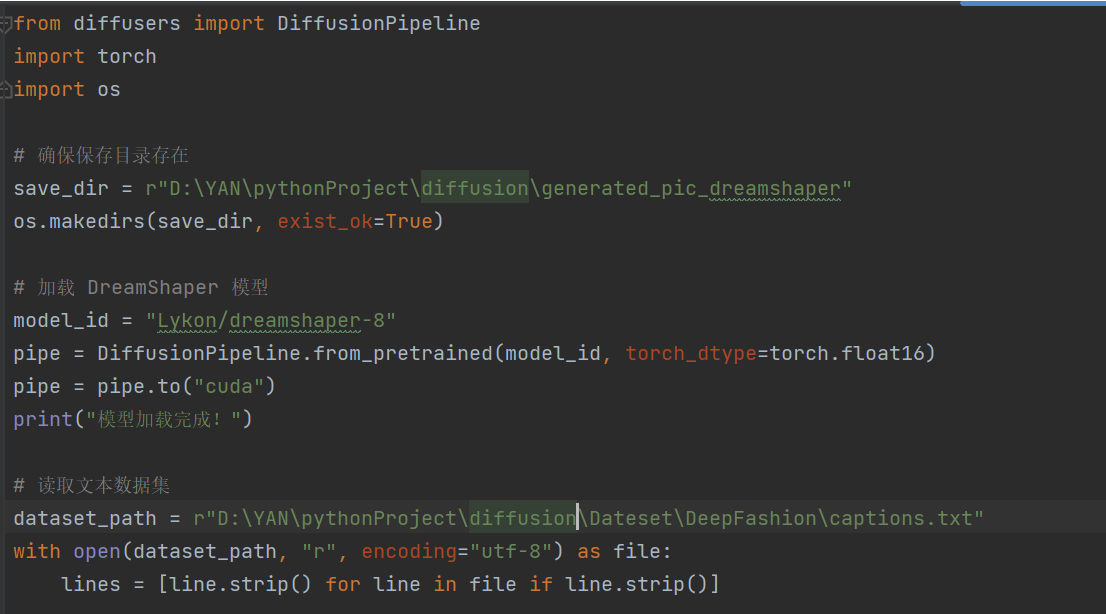

成功生成:
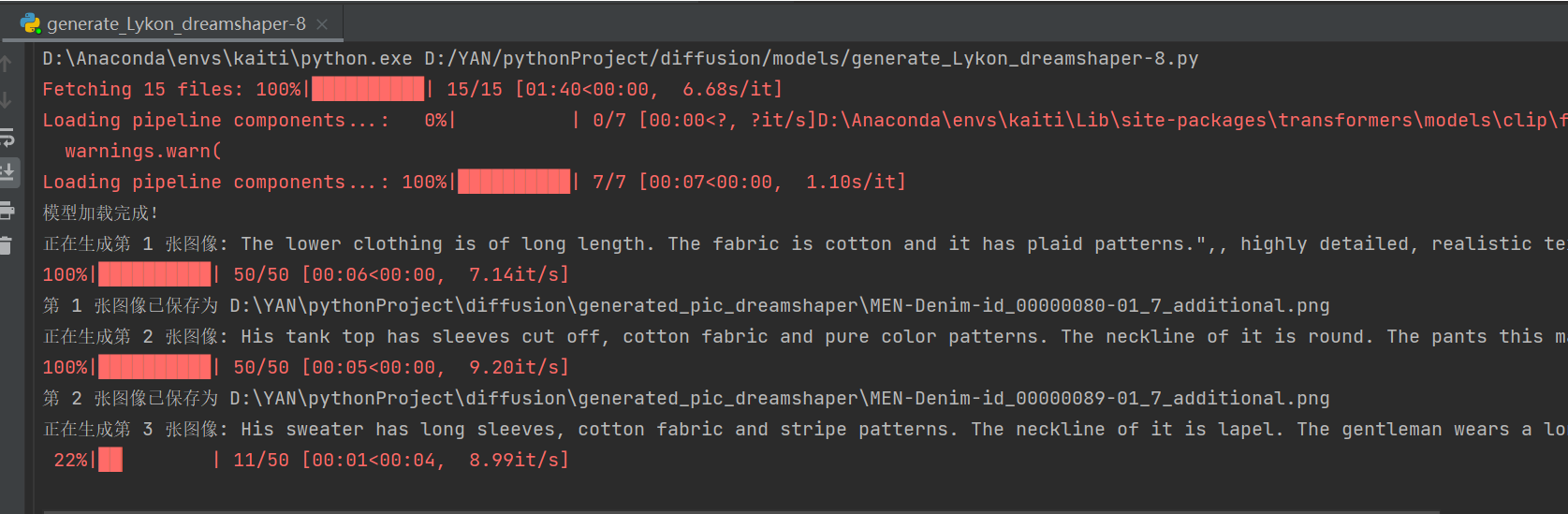
效果(可能是hugging face基础模型的原因,风格化严重):

五、优化四,sdv1.5+contronet
边缘图约束+提示词优化
需先下载库:
速度比前面慢接近十倍:(与原图保持轮廓一致)


六、问题探索历程
1. 从 SDXL 到轻量化模型:模型选择的权衡
技术问题
最初,我计划使用 Stable Diffusion XL (SDXL),因为它在图像质量上表现优异。然而,由于 SDXL 模型体积较大(约 10GB)且对硬件要求高,下载困难并且运行复杂,最终选择了更轻量的模型。
解决方法
转向使用 runwayml/stable-diffusion-v1-5(约 4GB),该模型社区支持广泛,且生成质量适中。为了提升生成效果,引入了 LoRA 微调技术。
技术细节
-
LoRA 微调:使用 LoRA 技术增强模型生成能力,通过加载小型权重文件(几十 MB)进行微调。
-
代码实现:
from diffusers import StableDiffusionPipeline pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16) pipe.load_lora_weights(r"D:\YAN\pythonProject\diffusion\lora\fashion-detail-lora.safetensors") -
参数调整:设置
num_inference_steps=50和guidance_scale=7.5来平衡生成质量和速度。
2. LoRA 下载受阻:转向基础模型优化
技术问题
由于网络限制,我无法顺利从 Civitai 或 Hugging Face 下载 LoRA 权重文件。
解决方法
放弃使用 LoRA,转向通过提示词工程和参数调整优化 runwayml/stable-diffusion-v1-5 的生成效果,并尝试了其他轻量模型,如 Lykon/dreamshaper-8。
技术细节
-
提示词优化:加入更具体的描述,如
highly detailed, realistic textures,并使用负面提示排除低质量元素。 -
代码调整:
image = pipe(prompt, negative_prompt="blurry, low resolution", num_inference_steps=75, guidance_scale=10.0).images[0] -
DreamShaper 模型:使用
Lykon/dreamshaper-8,并手动下载模型文件避免网络问题:model_id = r"D:\YAN\pythonProject\diffusion\models\dreamshaper-8" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
3. ControlNet 约束:提升结构一致性
技术问题
尽管生成图像有了提升,但服装结构和轮廓依然不够精确。我希望通过 ControlNet 强化生成图像的结构一致性。
解决方法
集成了 lllyasviel/sd-controlnet-canny 模型,利用 Canny 边缘图作为输入,以此加强生成图像的结构保持性。
技术细节
-
依赖安装:安装
opencv-python处理边缘图:pip install opencv-python -
ControlNet 实现:
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16) pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16) canny_image = cv2.Canny(cv2.imread(image_path, cv2.IMREAD_GRAYSCALE), 100, 200) image = pipe(prompt, image=canny_image, controlnet_conditioning_scale=1.0).images[0]
4. 指标评估:文件名匹配与全黑图处理
技术问题
计算 PSNR、SSIM 和 LPIPS 时,出现了文件名匹配失败的问题(图像格式不一致)以及部分图像为全黑图,导致计算结果偏差。
解决方法
调整文件名匹配逻辑,去除扩展名匹配,同时加入全黑图检测,跳过不合适的图像。
技术细节
-
文件名匹配:
base_name = os.path.splitext(gen_file)[0] original_file = original_files.get(base_name) -
全黑图检测:
def is_black_image(img):return np.all(img == 0) if is_black_image(generated_img):print(f" 跳过全黑图: {gen_file}")continue
5. SSIM 计算错误:尺寸与数据范围问题
技术问题
SSIM 计算报错,主要是由于图像尺寸过小或数据范围不正确。
解决方法
添加尺寸检查并为 SSIM 指定 data_range=1.0。
技术细节
-
尺寸检查:
h, w = original_img.shape[:2] if h < 7 or w < 7:raise ValueError(f"图像尺寸 {h}x{w} 太小,SSIM 需要至少 7x7") -
SSIM 参数调整:
ssim_value = ssim(original, generated, channel_axis=2, win_size=min(7, min(h, w)), data_range=1.0)
6. LPIPS 归一化调整
技术问题
LPIPS 计算结果异常,原因是图像数据范围不符合期望。
解决方法
将图像从 [0, 1] 转换为 [-1, 1],以适应 LPIPS 计算。
技术细节
original_tensor = torch.from_numpy((original * 2 - 1).transpose(2, 0, 1)).float().unsqueeze(0).to('cuda')
generated_tensor = torch.from_numpy((generated * 2 - 1).transpose(2, 0, 1)).float().unsqueeze(0).to('cuda')
lpips_value = lpips_model(original_tensor, generated_tensor).item()
最终结果与分析
在优化和调参后,我生成了多个模型的图像并计算了对应的 PSNR、SSIM 和 LPIPS 指标。以下是最终结果: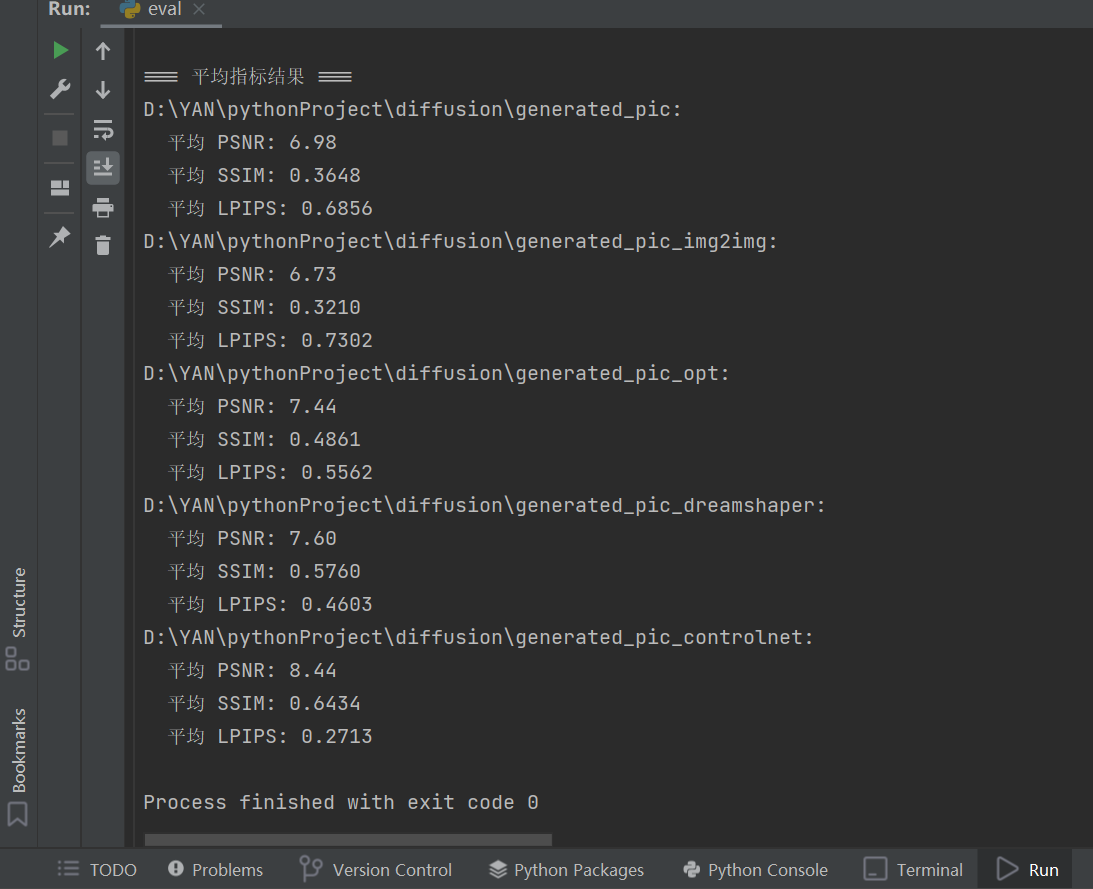
结果分析
-
PSNR:
generated_pic_controlnet的 8.44 最高,表示图像与原图差异最小。 -
SSIM:
generated_pic_controlnet的 0.6434 最高,结构相似性最优,验证了 ControlNet 对结构的一致性控制能力。 -
LPIPS:
generated_pic_controlnet的 0.2713 最低,感知相似性最佳,符合人类视觉评价。
总结
通过从 SDXL 的放弃,到 LoRA 的失败,再到 ControlNet 的成功集成,我逐步优化了图像生成质量。最终,ControlNet 在所有指标上均表现优异,特别是在服装生成任务上。
后续优化想法、可参考思路:
在 ControlNet 加入边缘图优化后,接下来可以考虑以下几个改进方向,以进一步提升图像生成质量和效果:
1. LoRA 微调
-
目标:若网络问题得到解决,可以引入服装特定的 LoRA 微调,以进一步优化细节(如纹理、材质),进而提升 SSIM 和 LPIPS 指标。
-
实现:下载和加载特定于服装领域的 LoRA 权重文件,微调基础模型,提升生成图像的细节表现。
2. 超分辨率后处理
-
目标:通过超分辨率技术(如 ESRGAN 或 Real-ESRGAN)对生成的图像进行后处理,提高 PSNR 和图像清晰度。
-
实现:使用超分辨率网络对生成的低分辨率图像进行放大和细节恢复,从而提高图像质量,减少模糊现象。
3. 自适应提示词
-
目标:基于原始图像的特征(如颜色、风格)动态生成提示词,减少生成偏差,提升图像与提示词的匹配度和感知一致性。
-
实现:使用图像分析模型提取图像特征,生成与原图风格和元素一致的提示词,以便引导模型生成更符合预期的图像。
4. 损失函数优化
-
目标:在训练或微调中加入感知损失(如 LPIPS),使生成图像更贴近人类视觉评价,提升图像质量的感知效果。
-
实现:在训练过程中加入感知损失函数,优化模型输出,使生成图像与目标图像在视觉上更为相似。
5. 多模型融合
-
目标:结合 DreamShaper 和 ControlNet 等模型的优势,通过模型集成提升图像生成的综合质量。
-
实现:在生成过程中融合多个模型的输出,采用加权平均或其他融合策略,以平衡各模型的优缺点,生成更加细腻和多样化的图像。
这些优化方法为 ControlNet 和 Stable Diffusion 图像生成模型提供了更多的潜力和改进空间。通过在细节、分辨率、提示词自适应和模型融合等方面进行优化,能够进一步提升服装生成任务的质量和稳定性,探索更多可能性,有需要可以从以上五点做尝试。
本篇基于sd v1.5:
深度学习项目记录·Stable Diffusion从零搭建、复现笔记-CSDN博客
优化后续强相关:
✅ Stable Diffusion v1.5:不换模型优化人体细节的实用技巧-CSDN博客
Stable Diffusion+Pyqt5: 实现图像生成与管理界面(带保存 + 历史记录 + 删除功能)——我的实验记录(结尾附系统效果图)-CSDN博客