一个专业做设计的网站google 推广优化
优化理论
本章节介绍深度学习中的高级优化技术,包括学习率衰减、梯度裁剪和批量归一化。这些技术能够显著提升模型的训练效果和稳定性。
学习率衰减(Learning Rate Decay)
数学原理与可视化
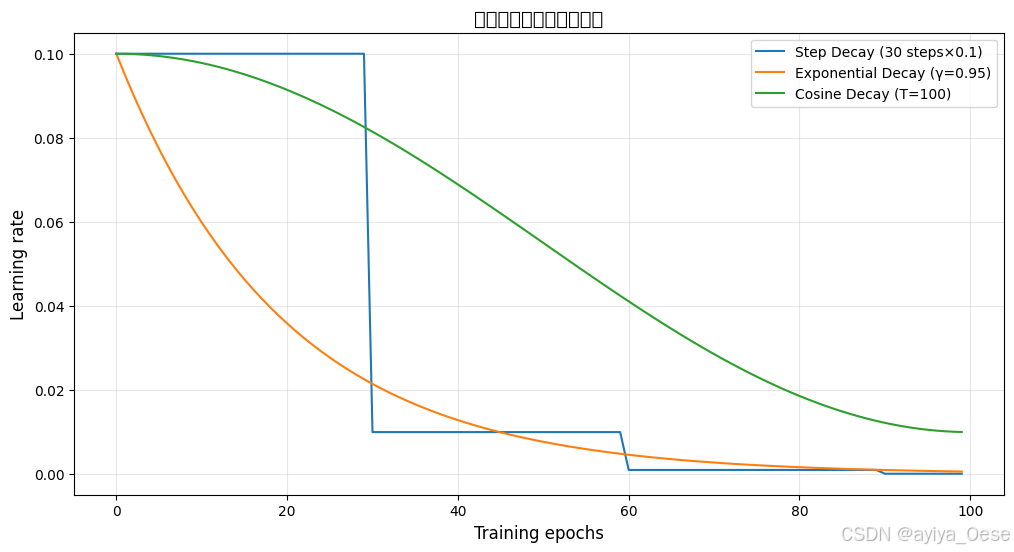
学习率衰减策略的数学表达:
-
步进式衰减:
α t = α 0 × γ ⌊ t / s ⌋ \alpha_t = \alpha_0 \times \gamma^{\lfloor t/s \rfloor} αt=α0×γ⌊t/s⌋
其中 s s s为衰减周期, γ \gamma γ为衰减因子 -
指数衰减:
α t = α 0 × e − γ t \alpha_t = \alpha_0 \times e^{-\gamma t} αt=α0×e−γt -
余弦衰减:
α t = α min + 1 2 ( α 0 − α min ) ( 1 + cos ( t π T ) ) \alpha_t = \alpha_{\text{min}} + \frac{1}{2}(\alpha_0 - \alpha_{\text{min}})(1 + \cos(\frac{t\pi}{T})) αt=αmin+21(α0−αmin)(1+cos(Ttπ))
import matplotlib.pyplot as plt# 衰减策略可视化
epochs = 100
initial_lr = 0.1# 计算各策略学习率
step_lrs = [initial_lr * (0.1 ** (i//30)) for i in range(epochs)]
expo_lrs = [initial_lr * (0.95 ** i) for i in range(epochs)]
cosine_lrs = [0.01 + 0.5*(0.1-0.01)*(1 + np.cos(np.pi*i/epochs)) for i in range(epochs)]# 绘制对比图
plt.figure(figsize=(12,6))
plt.plot(step_lrs, label='Step Decay (每30步×0.1)')
plt.plot(expo_lrs, label='Exponential Decay (γ=0.95)')
plt.plot(cosine_lrs, label='Cosine Decay (T=100)')
plt.title("不同学习率衰减策略对比", fontsize=14)
plt.xlabel("训练周期", fontsize=12)
plt.ylabel("学习率", fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
最佳实践
# 组合使用多种调度器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)# 前50步使用余弦衰减
scheduler1 = CosineAnnealingLR(optimizer, T_max=50)
# 之后使用步进衰减
scheduler2 = StepLR(optimizer, step_size=10, gamma=0.5)for epoch in range(100):train(...)if epoch < 50:scheduler1.step()else:scheduler2.step()
梯度裁剪(Gradient Clipping)
数学原理
梯度裁剪通过限制梯度范数防止参数更新过大:
if ∥ g ∥ > c : g ← c ∥ g ∥ g \text{if } \|g\| > c: \quad g \gets \frac{c}{\|g\|}g if ∥g∥>c:g←∥g∥cg
其中 c c c为裁剪阈值, ∥ g ∥ \|g\| ∥g∥为梯度范数
梯度动态可视化
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# 定义一个简单的模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)# 初始化模型、优化器和损失函数
model = SimpleModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()grad_norms = []
clipped_grad_norms = []for _ in range(1000):# 生成随机输入和目标inputs = torch.randn(32, 10)targets = torch.randn(32, 1)# 前向传播outputs = model(inputs)loss = criterion(outputs, targets)# 反向传播optimizer.zero_grad()loss.backward()# 记录裁剪前梯度grad_norms.append(torch.norm(torch.cat([p.grad.view(-1) for p in model.parameters()])))# 执行裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)# 记录裁剪后梯度clipped_grad_norms.append(torch.norm(torch.cat([p.grad.view(-1) for p in model.parameters()])))# 更新参数optimizer.step()# 绘制梯度变化
plt.figure(figsize=(12, 6))
plt.plot(grad_norms, alpha=0.6, label='Original Gradient Norm')
plt.plot(clipped_grad_norms, alpha=0.6, label='Clipped Gradient Norm')
plt.axhline(1.0, color='r', linestyle='--', label='Clipping Threshold')
plt.yscale('log')
plt.title("Gradient Clipping Effect Monitoring", fontsize=14)
plt.xlabel("Training Steps", fontsize=12)
plt.ylabel("Gradient L2 Norm (log scale)", fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()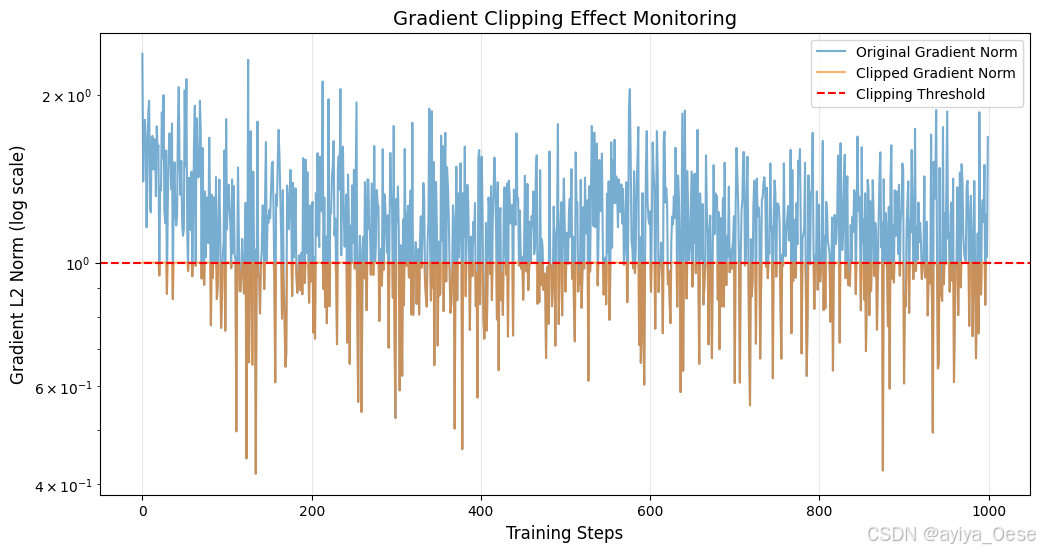
实践技巧
- RNN中推荐值:LSTM/GRU 中 max_norm 取 1.0 或 2.0
- 结合学习率:较高学习率需配合较小裁剪阈值
- 监控策略:定期输出梯度统计量
print(f"梯度均值: {grad.mean().item():.3e} ± {grad.std().item():.3e}")
批量归一化(Batch Normalization)
数学推导
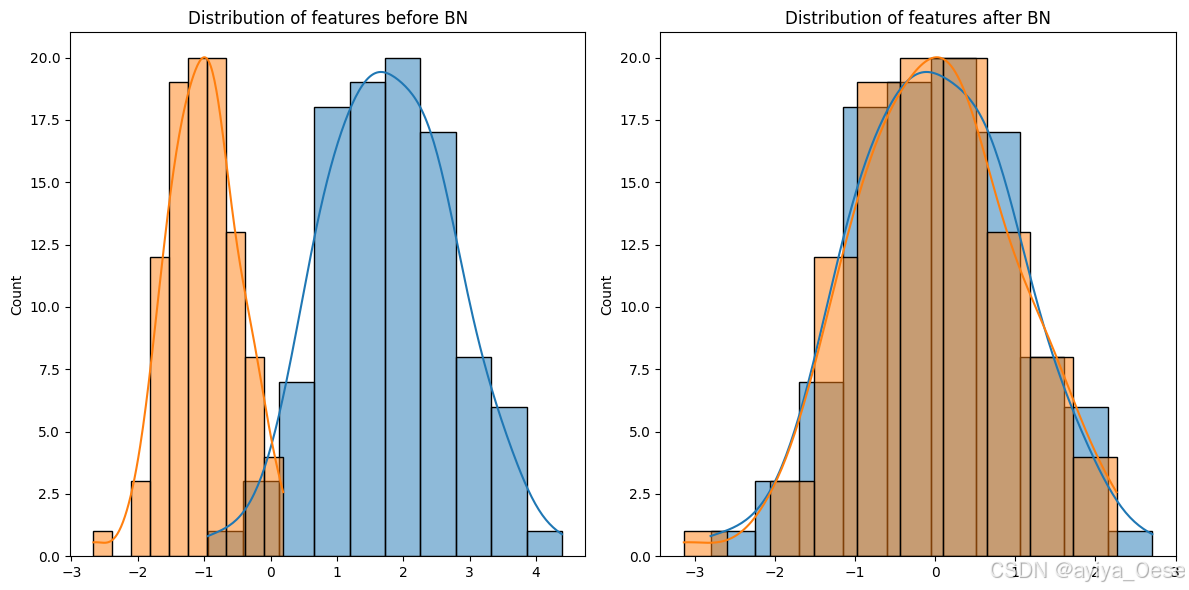
对于输入批次 B = { x 1 , . . . , x m } B = \{x_1,...,x_m\} B={x1,...,xm}:
- 计算统计量:
μ B = 1 m ∑ i = 1 m x i σ B 2 = 1 m ∑ i = 1 m ( x i − μ B ) 2 \mu_B = \frac{1}{m}\sum_{i=1}^m x_i \\ \sigma_B^2 = \frac{1}{m}\sum_{i=1}^m (x_i - \mu_B)^2 μB=m1i=1∑mxiσB2=m1i=1∑m(xi−μB)2 - 标准化:
x ^ i = x i − μ B σ B 2 + ϵ \hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} x^i=σB2+ϵxi−μB - 仿射变换:
y i = γ x ^ i + β y_i = \gamma \hat{x}_i + \beta yi=γx^i+β
训练/评估模式对比
import torch.nn as nn
import torch
# 创建BN层
bn = nn.BatchNorm1d(64)# 训练模式
bn.train()
for _ in range(100):x = torch.randn(32, 64) # 批大小32y = bn(x)
print("训练模式统计:", bn.running_mean[:5].detach().numpy()) # 显示部分通道# 评估模式
bn.eval()
with torch.no_grad():x = torch.randn(32, 64)y = bn(x)
print("评估模式统计:", bn.running_mean[:5].detach().numpy())
可视化BN效果
# 生成模拟数据
data = torch.cat([torch.normal(2.0, 1.0, (100, 1)),torch.normal(-1.0, 0.5, (100, 1))
], dim=1)# 应用BN
bn = nn.BatchNorm1d(2)
output = bn(data)# 绘制分布对比
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
sns.histplot(data[:,0], kde=True, label='原始特征1')
sns.histplot(data[:,1], kde=True, label='原始特征2')
plt.title("Distribution of features before BN")plt.subplot(1,2,2)
sns.histplot(output[:,0], kde=True, label='BN后特征1')
sns.histplot(output[:,1], kde=True, label='BN后特征2')
plt.title("Distribution of features after BN")plt.tight_layout()
技术组合应用案例
图像分类任务
# 自定义CNN模型
class CustomCNN(nn.Module):def __init__(self):super().__init__()# 卷积层 使用BNself.conv_layers = nn.Sequential(nn.Conv2d(3, 64, 3),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(64, 128, 3),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2),)# 全连接层self.fc = nn.Linear(128*5*5, 10)def forward(self, x):x = self.conv_layers(x)return self.fc(x.view(x.size(0), -1))# 初始化模型、优化器和调度器
model = CustomCNN()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
scheduler = CosineAnnealingLR(optimizer, T_max=200)# 带梯度裁剪的训练循环
max_grad_norm = 5.0 # 裁剪阈值
for epoch in range(200):model.train() # 模型进入训练模式for inputs, targets in train_loader: # 训练数据加载器outputs = model(inputs) # 前向传播loss = F.cross_entropy(outputs, targets) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)optimizer.step() # 参数更新scheduler.step() # 学习率更新
关键技术总结
| 技术 | 主要作用 | 典型应用场景 | 注意事项 |
|---|---|---|---|
| 学习率衰减 | 精细收敛 | 深层网络训练 | 配合warmup效果更佳 |
| 梯度裁剪 | 稳定训练 | RNN、Transformer | 阈值需随batch size调整 |
| 批量归一化 | 加速收敛 | CNN、全连接网络 | 小batch效果差 |
组合策略建议
- CNN架构:BN + 动量SGD + 余弦衰减
- RNN架构:梯度裁剪 + Adam + 步进衰减
- Transformer:预热 + 梯度裁剪 + AdamW
# Transformer优化示例
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4, betas=(0.9, 0.98))
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda=lambda step: min(step**-0.5, step*(4000**-1.5)) # 预热
)