做网站能赚流量钱吗互联网广告营销是什么
机器学习之随机森林(五)
文章目录
- 机器学习之随机森林(五)
- 集成学习与随机森林算法详解
- 一、集成学习概述
- 主要类型
- Bagging典型流程
- 二、随机森林原理
- 核心特点
- 三、Sklearn API详解
- 关键参数
- 四、实战案例:泰坦尼克生存预测
- 1. 数据准备与预处理
- 2. 模型训练与调优
- 3. 模型评估
- 五、关键要点总结
集成学习与随机森林算法详解
一、集成学习概述
集成学习(Ensemble Learning)通过组合多个分类器,构建预测效果更好的集成分类器。类比"三个臭皮匠,赛过诸葛亮"。
主要类型
- Bagging:并行训练多个基学习器
- Boosting:串行训练,后续模型修正前序模型的错误
- Stacking:用元学习器组合多个基学习器
Bagging典型流程
- 有放回地抽取n个训练样本
- 训练M个子模型
- 分类问题采用投票法确定最终结果
二、随机森林原理
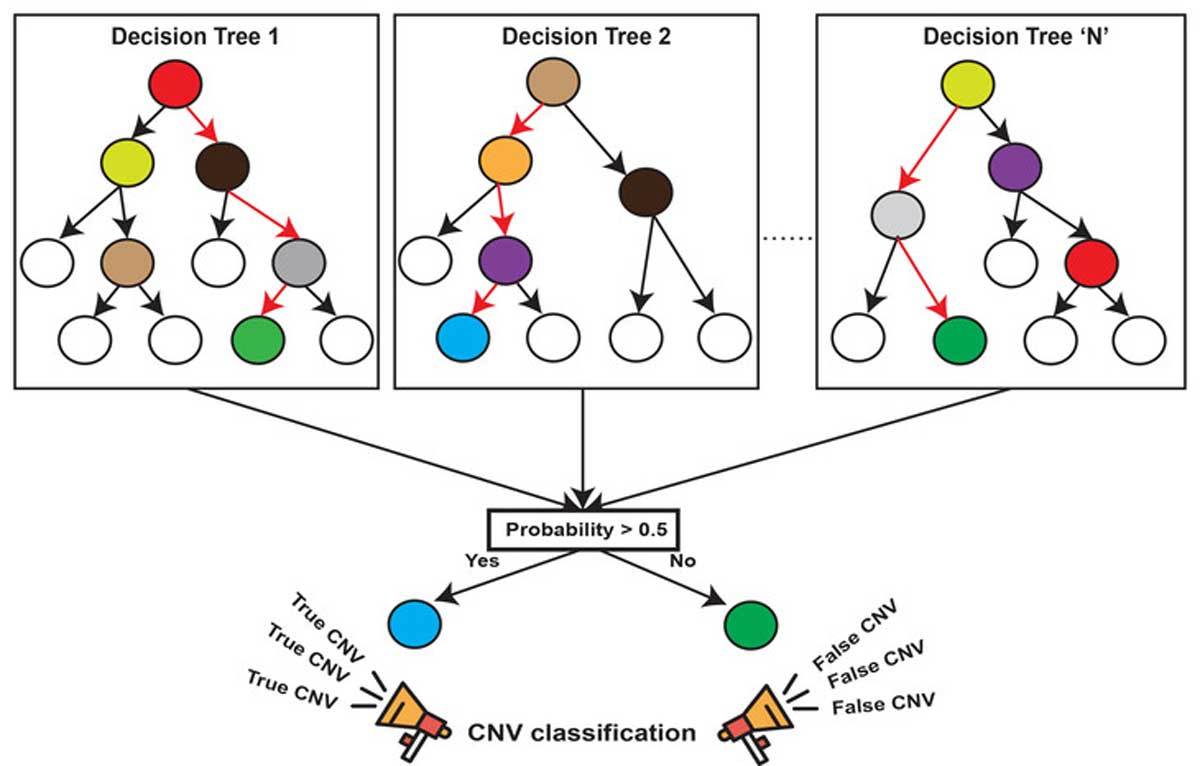
核心特点
- 随机性:
- 样本随机:有放回抽样(Bootstrap)
- 特征随机:每次随机选择k个特征(k<d)
- 森林结构:多个决策树构成
- 优势:
- 处理高维特征无需降维
- 通过平均/投票提高精度,控制过拟合
三、Sklearn API详解
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, # 树的数量criterion='gini', # 划分标准:"gini"或"entropy"max_depth=None, # 树的最大深度...
)
关键参数
| 参数 | 说明 |
|---|---|
| n_estimators | 森林中决策树的数量 |
| criterion | 划分算法:"gini"基尼系数/"entropy"信息增益 |
| max_depth | 树的最大深度限制 |
四、实战案例:泰坦尼克生存预测
1. 数据准备与预处理
import pandas as pd
from sklearn.feature_extraction import DictVectorizer# 数据加载
titanic = pd.read_csv("src/titanic/titanic.csv")
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]# 数据处理
x["age"].fillna(x["age"].mean(), inplace=True) # 年龄缺失值填充
x = x.to_dict(orient="records") # 转为字典格式
2. 模型训练与调优
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV# 特征转换
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)# 网格搜索调参
param_dict = {"n_estimators": [120,200,300,500,800,1200],"max_depth": [5,8,15,25,30]
}
estimator = GridSearchCV(RandomForestClassifier(),param_grid=param_dict,cv=3 # 3折交叉验证
)
estimator.fit(x_train, y_train)
3. 模型评估
# 最佳参数输出
print("最佳参数:", estimator.best_params_)
print("最佳准确率:", estimator.best_score_)# 测试集评估
score = estimator.score(x_test, y_test)
print("测试集准确率:", score)
五、关键要点总结
- 随机森林通过双重随机性(样本+特征)增强多样性
- 典型超参数需调优:
- 树的数量(n_estimators)
- 树深度(max_depth)
- 划分标准(criterion)
- 网格搜索+交叉验证是调参的有效方法
- 适用于高维数据,兼具准确性和抗过拟合能力