亳州网站网站建设114啦网址导航官网
目录
前言
1. 使用的相关官方代码[1][2][3]
2. 使用[2]代码将模型导出为ONNX
3. [1]和[2]导出的ONNX模型结构对比
4. 后处理代码参考及Python实现
4.1 参考的后处理代码
4.2 后处理Python实现
4.2.1 目录结构
4.2.2 处理脚本文件ops_rk3588.py
4.2.3 YOLOv8后处理文件yolov8_det_rk3588.py
4.2.4 YOLOv8-pose后处理文件yolov8_pose_rk3588.py
5. Python推理结果显示
5.1 YOLOv8结果显示
5.2 YOLOv8-pose结果显示
6. 总结
前言
由于种种原因,原始的YOLOv8系列的模型,在RK3588上难以部署,在 .pt 转 .onnx 的时候需要去掉后处理层(主要是DFL层)。因此,模型的后处理需要自己来实现。
本文基于Rockship 官方给的源码(导出模型的Python代码和部署模型的C++代码)实现对YOLOv8 的.onnx模型格式的导出,并实现Python版本的后处理代码。
本文实现了YOLOv8(目标检测)和YOLOv8-pose(关键点检测)的模型导出和后处理代码。
1. 使用的相关官方代码[1][2][3]
[1] 训练代码,YOLOv8/YOLOv11官方代码:https://github.com/ultralytics/ultralytics
使用的版本为:8.3.67的main分支
[2] 导出代码,airockship官方给的导出代码:https://github.com/airockchip/ultralytics_yolo11
使用的版本为:2025.01.20时最新的main分支
[3] 部署代码,airockship官方给的C++推理代码:https://github.com/airockchip/rknn_model_zoo
使用的版本为:V2.1版本的main分支
2. 使用[2]代码将模型导出为ONNX
[2]的导出目录结构和相关代码如下图(模型输入的图片尺寸根据自己实际需要的尺寸来设置,需要为32的倍数,因为模型中有8/16/32倍下采样):
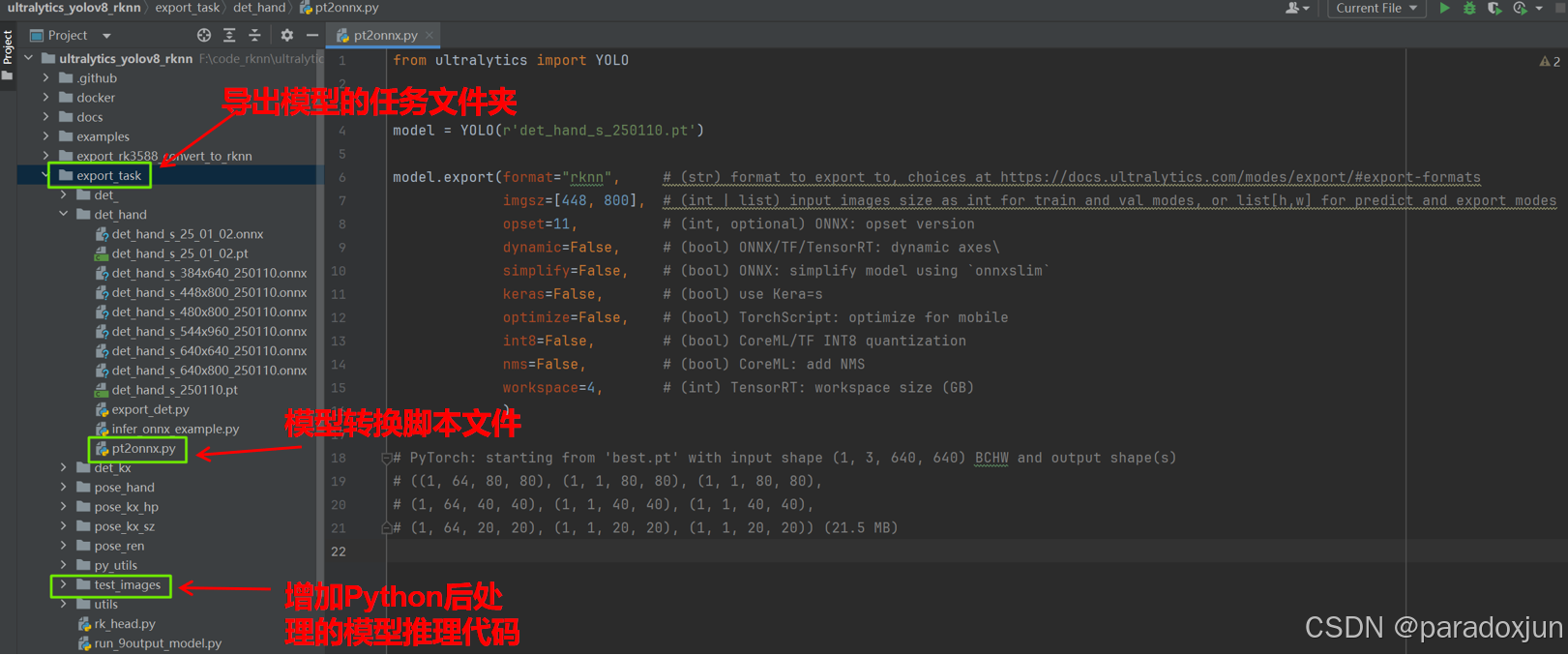
from ultralytics import YOLOmodel = YOLO(r'det_hand_s_250110.pt')model.export(format="rknn", # (str) format to export to, choices at https://docs.ultralytics.com/modes/export/#export-formatsimgsz=[448, 800], # (int | list) input images size as int for train and val modes, or list[h,w] for predict and export modesopset=11, # (int, optional) ONNX: opset versiondynamic=False, # (bool) ONNX/TF/TensorRT: dynamic axes\simplify=False, # (bool) ONNX: simplify model using `onnxslim`keras=False, # (bool) use Kera=soptimize=False, # (bool) TorchScript: optimize for mobileint8=False, # (bool) CoreML/TF INT8 quantizationnms=False, # (bool) CoreML: add NMSworkspace=4, # (int) TensorRT: workspace size (GB))# PyTorch: starting from 'best.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s)
# ((1, 64, 80, 80), (1, 1, 80, 80), (1, 1, 80, 80),
# (1, 64, 40, 40), (1, 1, 40, 40), (1, 1, 40, 40),
# (1, 64, 20, 20), (1, 1, 20, 20), (1, 1, 20, 20)) (21.5 MB)
检测、关键点、旋转框、分割均可这样导出(模型内部存了.yaml文件,已经含有模型的信息)。由于我只使用到检测和关键点,因此,仅给出这二者的后处理推理代码。
3. [1]和[2]导出的ONNX模型结构对比
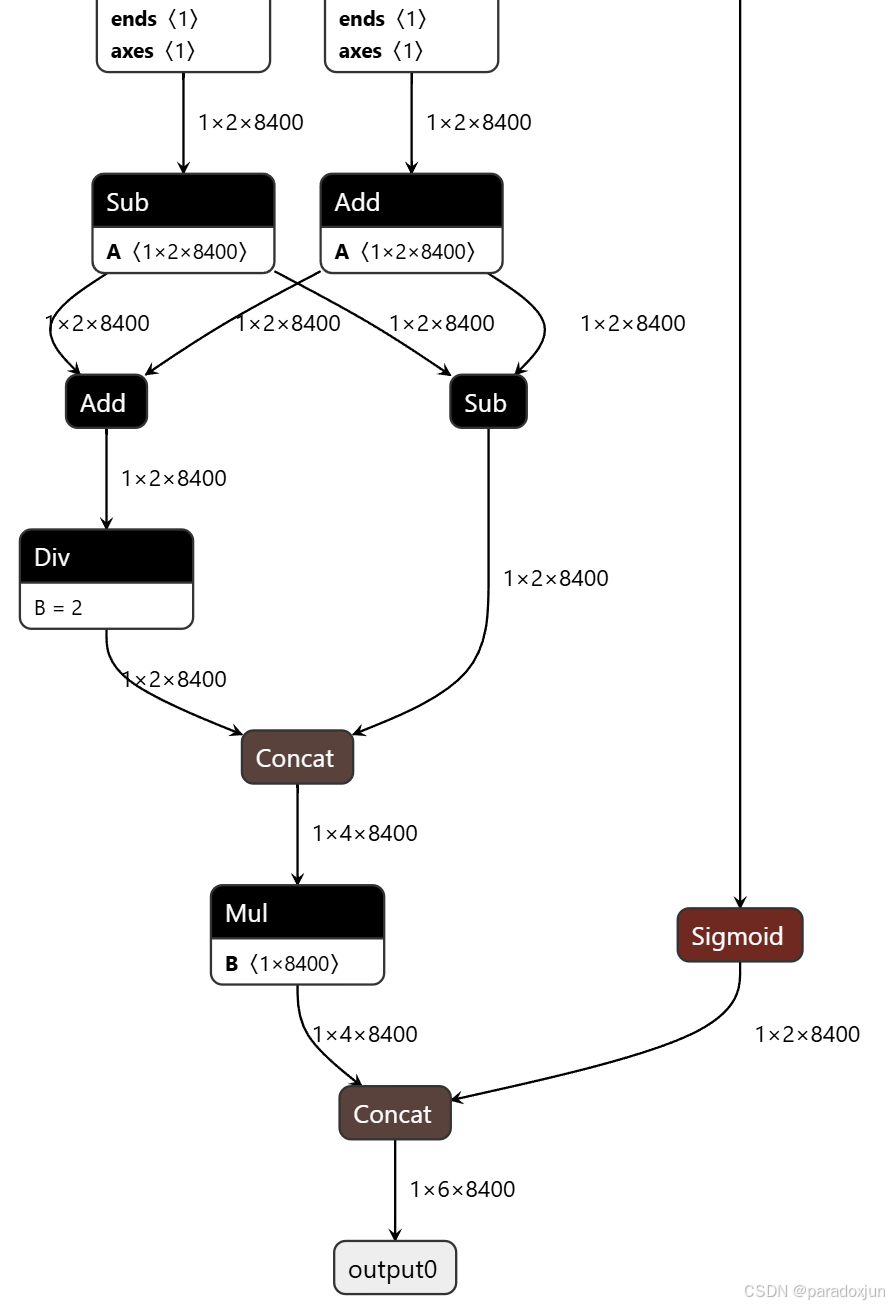
[1]如下图,将不同分辨率的检测头输出结果连接在一起,仅输出一个结果:
输出维度为:[1, 4+class_num, 21×input_imgsz_h×input_imgsz_w÷1024]。
其中,21/1024 = (1/8×1/8+1/16×1/16+1/32×1/32)
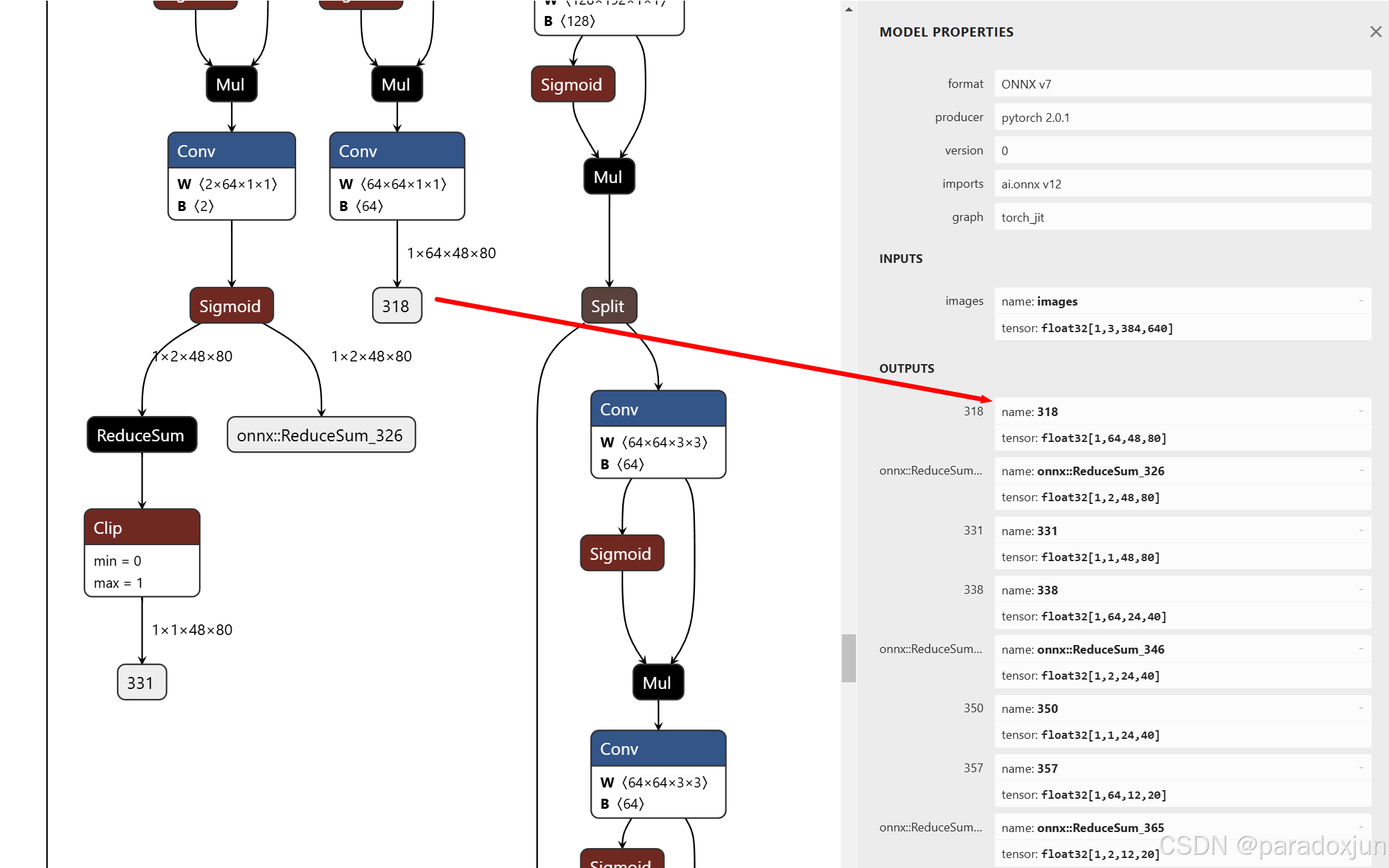
[2]如下图(只截图下采样为8的3个头),总共有9个输出头:
318: [1, 64, input_imgsz_h // 8, input_imgsz_w // 8] (下图的输入图片为(384, 640))
326: [1, class_num, input_imgsz_h // 8, input_imgsz_w // 8]
331: [1, 1, input_imgsz_h // 8, input_imgsz_w // 8]
338: [1, 64, input_imgsz_h // 16, input_imgsz_w // 16]
346: [1, class_num, input_imgsz_h // 16, input_imgsz_w // 16]
350: [1, 1, input_imgsz_h // 16, input_imgsz_w // 16]
357: [1, 64, input_imgsz_h // 32, input_imgsz_w // 32]
365: [1, class_num, input_imgsz_h // 32, input_imgsz_w // 32]
369: [1, 1, input_imgsz_h // 32, input_imgsz_w // 32]
4. 后处理代码参考及Python实现
4.1 参考的后处理代码
[3]中,RK官方写的C++后处理代码写得跟💩一样,个人严重怀疑是让实习生写的,烂的有点离谱,不过这里仅实现推理,不做性能优化。
参考的代码路径:
rknn_model_zoo/examples/yolov8/cpp/postprocess.cc
rknn_model_zoo/examples/yolov8_pose/cpp/postprocess.cc
参考的函数:
inline static int clamp(...);
static float CalculateOverlap(...);
static int nms(...); // 优化:YOLO后处理trick - 减少nms的计算次数、比较次数和空间消耗
static int nms_pose(...);
void softmax(...);
static float sigmoid(...);
static float unsigmoid(...);
static void compute_dfl(...);
static int process_fp32(...);
static int process_fp32_v8(...);
static int process_fp32_pose(...);
int post_process_det(...);
int post_process_pose(...);
4.2 后处理Python实现
4.2.1 目录结构
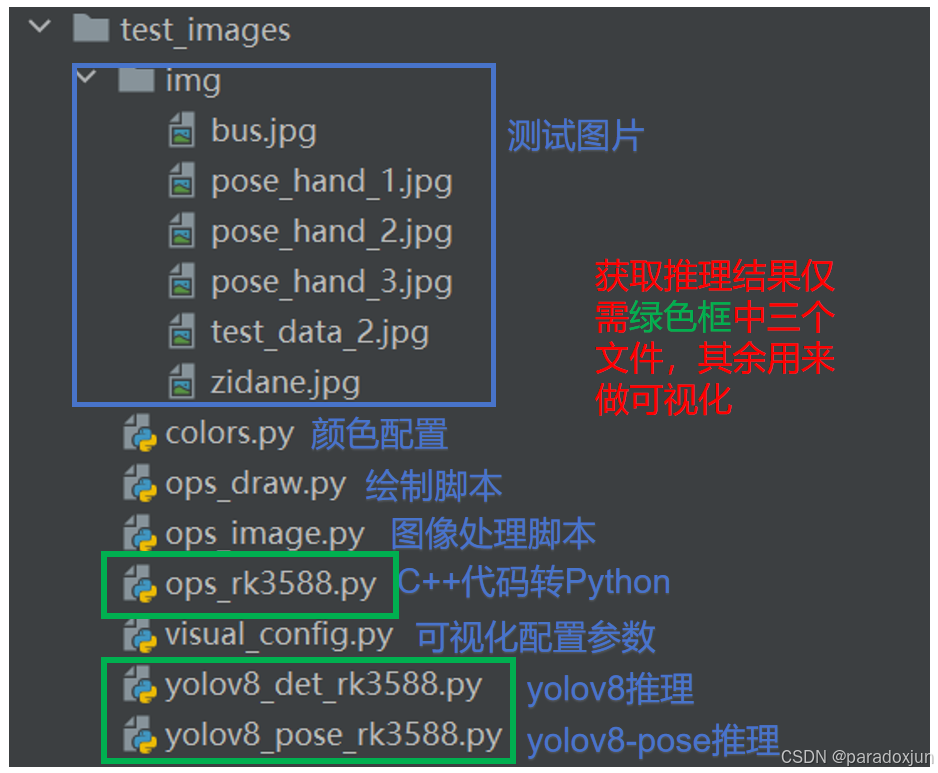
4.2.2 处理脚本文件ops_rk3588.py
对C++中的结构体、变量进行了拆分和优化。
import cv2
import numpy as npdef letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scalefill=False, scaleup=True, stride=32):"""调整图片大小并填充以适应目标尺寸。:param im:输入图片。:param new_shape:目标形状,默认 (640, 640)。:param color:填充颜色,默认 (114, 114, 114)。:param auto:自动调整填充,保持最小矩形。True会让图片宽高是stride的最小整数倍,比如32,可以方便卷积。:param scalefill:是否拉伸填充。在auto是False时,True会让图片拉伸变形。:param scaleup:是否允许放大。False让图片只能缩小。:param stride:步幅大小,默认 32。:return:返回调整后的图片,缩放比例(宽,高)和填充值。"""shape = im.shape[:2] # 获取当前图片的形状 [高度, 宽度]if isinstance(new_shape, int):new_shape = (new_shape, new_shape)r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) # 缩放比例 (新尺寸 / 旧尺寸)if not scaleup: # 如果不允许放大,只进行缩小 (提高验证的 mAP)r = min(r, 1.0)ratio = r, r # 计算填充宽度和高度的缩放比例new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # 新的未填充尺寸 (宽度, 高度)dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # 计算宽高方向的填充值if auto: # 如果设置为自动,保持最小矩形dw, dh = np.mod(dw, stride), np.mod(dh, stride) # 使填充值是步幅的倍数elif scalefill: # 如果拉伸填充,完全填充dw, dh = 0.0, 0.0 # 不进行填充new_unpad = (new_shape[1], new_shape[0]) # 未填充的尺寸就是目标尺寸ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # 计算宽高的缩放比例dw /= 2 # 将填充值均分到两侧dh /= 2 # 将填充值均分到上下if shape[::-1] != new_unpad: # 如果当前形状和新的未填充形状不同,则调整大小im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) # 计算上下填充的像素数left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) # 计算左右填充的像素数im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # 添加填充边框,填充值为指定颜色return im, ratio, (dw, dh) # 返回调整后的图片,缩放比例和填充值def clamp(val, min_val, max_val):return max(min_val, min(val, max_val))def calculate_overlap(xmin0, ymin0, xmax0, ymax0, xmin1, ymin1, xmax1, ymax1):w = max(0.0, min(xmax0, xmax1) - max(xmin0, xmin1) + 1.0)h = max(0.0, min(ymax0, ymax1) - max(ymin0, ymin1) + 1.0)i = w * h # 交集面积u = ((xmax0 - xmin0 + 1.0) * (ymax0 - ymin0 + 1.0) +(xmax1 - xmin1 + 1.0) * (ymax1 - ymin1 + 1.0) - i) # 并集面积return 0.0 if u <= 0.0 else (i / u) # 计算 IoUdef nms(validCount, outputLocations, objProbs, classIds, order, filterId, threshold):"""采用双指针和滑动窗口方法对检测框进行非极大值抑制(NMS)Parameters:validCount (int): 有效检测框的数量outputLocations (list of float): 每个框的位置信息 (x, y, w, h)objProbs (list of float): 每个检测框的置信度classIds (list of int): 每个检测框的类别IDorder (list): 表示有效的检测框索引filterId (int): 需要处理的类别IDthreshold (float): IoU 阈值Returns:None (order 数组在原地修改)"""i, j = 0, 1while i < validCount and j < validCount:while i < validCount and (order[i] == -1 or classIds[order[i]] != filterId):i += 1 # 找到下一个有效框while j < validCount and (order[j] == -1 or classIds[order[j]] != filterId):j += 1 # 找到下一个有效框if j >= validCount:breakn = order[i]while j < validCount and order[j] != -1 and classIds[order[j]] == filterId:m = order[j]# 计算两个框的坐标差值,若过小则移除置信度较低的框if (abs(outputLocations[n][0] - outputLocations[m][0]) < 1.5 and # xabs(outputLocations[n][1] - outputLocations[m][1]) < 1.5 and # yabs(outputLocations[n][2] - outputLocations[m][2]) < 2.0 and # wabs(outputLocations[n][3] - outputLocations[m][3]) < 2.0 # h):if objProbs[i] >= objProbs[j]:order[j] = -1 # 置信度较低的框置为无效j += 1else:order[i] = -1i = j # 当前最小置信度低导致无效,修改为移动索引j = i + 1breakelse:i = j # 当前最小和下一个不同导致无效,修改为移动索引j = i + 1break# 进行标准 NMS 处理for i in range(validCount):n = order[i]if n == -1 or classIds[n] != filterId:continuefor j in range(i + 1, validCount):m = order[j]if m == -1 or classIds[m] != filterId:continuexmin0, ymin0, xmax0, ymax0 = (outputLocations[n][0],outputLocations[n][1],outputLocations[n][0] + outputLocations[n][2],outputLocations[n][1] + outputLocations[n][3])xmin1, ymin1, xmax1, ymax1 = (outputLocations[m][0],outputLocations[m][1],outputLocations[m][0] + outputLocations[m][2],outputLocations[m][1] + outputLocations[m][3])# 如果两个框没有交集,跳过if xmin0 > xmax1 or xmax0 < xmin1 or ymin0 > ymax1 or ymax0 < ymin1:continueiou = calculate_overlap(xmin0, ymin0, xmax0, ymax0, xmin1, ymin1, xmax1, ymax1)# 通过 IoU 进行 NMS 过滤if iou > threshold:if objProbs[i] >= objProbs[j]:order[j] = -1else:order[i] = -1breakreturn 0 # 与 C++ 代码一致,返回 0def nms_pose(validCount, outputLocations, objProbs, classIds, order, filterId, threshold):"""进行姿态检测的非极大值抑制(NMS)Parameters:validCount (int): 有效检测框的数量outputLocations (list): 每个框的位置信息 (x, y, w, h, keypoints_index)objProbs (list): 每个检测框的置信度classIds (list): 每个检测框的类别 IDorder (list): 按置信度排序的检测框索引filterId (int): 需要处理的类别 IDthreshold (float): IoU 阈值Returns:None(order 数组在原地修改)"""i, j = 0, 1while i < validCount and j < validCount:while i < validCount and (order[i] == -1 or classIds[order[i]] != filterId):i += 1 # 找到下一个有效框while j < validCount and (order[j] == -1 or classIds[order[j]] != filterId):j += 1 # 找到下一个有效框if j >= validCount:breakn = order[i]while j < validCount and order[j] != -1 and classIds[order[j]] == filterId:m = order[j]# 计算两个框的坐标差值,若过小则移除置信度较低的框if (abs(outputLocations[n][0] - outputLocations[m][0]) < 1.5 and # xabs(outputLocations[n][1] - outputLocations[m][1]) < 1.5 and # yabs(outputLocations[n][2] - outputLocations[m][2]) < 2.0 and # wabs(outputLocations[n][3] - outputLocations[m][3]) < 2.0 # h):if objProbs[i] >= objProbs[j]:order[j] = -1 # 置信度较低的框置为无效j += 1else:order[i] = -1i = j # 当前最小置信度低导致无效,修改为移动索引j = i + 1breakelse:i = j # 当前最小和下一个不同导致无效,修改为移动索引j = i + 1break# 进行标准 NMS 处理for i in range(validCount):n = order[i]if n == -1 or classIds[n] != filterId:continuefor j in range(i + 1, validCount):m = order[j]if m == -1 or classIds[m] != filterId:continuexmin0, ymin0, xmax0, ymax0 = (outputLocations[n][0],outputLocations[n][1],outputLocations[n][0] + outputLocations[n][2],outputLocations[n][1] + outputLocations[n][3])xmin1, ymin1, xmax1, ymax1 = (outputLocations[m][0],outputLocations[m][1],outputLocations[m][0] + outputLocations[m][2],outputLocations[m][1] + outputLocations[m][3])# 如果两个框没有交集,跳过if xmin0 > xmax1 or xmax0 < xmin1 or ymin0 > ymax1 or ymax0 < ymin1:continueiou = calculate_overlap(xmin0, ymin0, xmax0, ymax0, xmin1, ymin1, xmax1, ymax1)# 通过 IoU 进行 NMS 过滤if iou > threshold:if objProbs[i] >= objProbs[j]:order[j] = -1else:order[i] = -1breakreturn 0 # 与 C++ 代码一致,返回 0def sigmoid(x):""" 计算 Sigmoid 函数 """return 1.0 / (1.0 + np.exp(-x))def unsigmoid(y):""" 计算 Sigmoid 的反函数(Logit 函数) """return -1.0 * np.log((1.0 / y) - 1.0)def softmax(input_array):"""计算 Softmax 函数(数值稳定版本)Parameters:input_array (numpy.ndarray): 1D NumPy 数组Returns:numpy.ndarray: 归一化后的 Softmax 结果"""max_val = np.max(input_array) # 计算最大值以提高数值稳定性exp_values = np.exp(input_array - max_val) # 减去最大值后再求指数return exp_values / np.sum(exp_values) # 归一化def compute_dfl(tensor, dfl_len):box = np.zeros(4, dtype=np.float32)for b in range(4):exp_t = np.exp(tensor[b * dfl_len: (b + 1) * dfl_len])exp_sum = np.sum(exp_t)acc_sum = np.sum(exp_t / exp_sum * np.arange(dfl_len))box[b] = acc_sumreturn boxdef process_fp32_v8(box_tensor, score_tensor, score_sum_tensor, stride, dfl_len, threshold=0.25):print(f"box_tensor.shape: {box_tensor.shape}")print(f"score_tensor.shape: {score_tensor.shape}")print(f"score_sum_tensor.shape: {score_sum_tensor.shape}")assert (box_tensor.shape[2] == score_tensor.shape[2] andscore_tensor.shape[2] == score_sum_tensor.shape[2] andbox_tensor.shape[3] == score_tensor.shape[3] andscore_tensor.shape[3] == score_sum_tensor.shape[3]), "输入的box, score, score_sum尺寸不匹配"grid_h = box_tensor.shape[2] # 输入尺寸高度除以 8/16/32grid_w = box_tensor.shape[3] # 输入尺寸宽度除以 8/16/32obj_class_num = score_tensor.shape[1] # 类别张量第1维度大小为类别数boxes = []objProbs = []classId = []validCount = 0for i in range(grid_h):for j in range(grid_w):max_class_id = -1# 通过 score sum 进行快速过滤if score_sum_tensor is not None and score_sum_tensor[0][0][i][j] < threshold:continuemax_score = 0for c in range(obj_class_num):if score_tensor[0][c][i][j] > threshold and score_tensor[0][c][i][j] > max_score:max_score = score_tensor[0][c][i][j]max_class_id = c# 计算 boxif max_score > threshold:before_dfl = np.zeros(dfl_len * 4, dtype=np.float32)for k in range(dfl_len * 4):before_dfl[k] = box_tensor[0][k][i][j] # 跳到下一个相同 grid 位置的通道box = compute_dfl(before_dfl, dfl_len) # 调用之前转换的 compute_dfl_hw 函数x1 = (-box[0] + j + 0.5) * stridey1 = (-box[1] + i + 0.5) * stridex2 = (box[2] + j + 0.5) * stridey2 = (box[3] + i + 0.5) * stridew = x2 - x1h = y2 - y1boxes.append([x1, y1, w, h])objProbs.append(max_score)classId.append(max_class_id)validCount += 1return validCount, boxes, objProbs, classIddef process_fp32_pose(input_tensor, stride, index, threshold=0.25):"""处理 FP32 版的姿态检测数据,解析 YOLO 关键点格式并进行 softmax 处理。"""print(f"input_tensor.shape: {input_tensor.shape}")input_loc_len = 64filterBoxes = []boxScores = []classId = []validCount = 0thres_fp = unsigmoid(threshold)grid_h = input_tensor.shape[2]grid_w = input_tensor.shape[3]obj_class_num = input_tensor.shape[1] - input_loc_lenfor h in range(grid_h):for w in range(grid_w):for a in range(obj_class_num):if input_tensor[0][input_loc_len + a][h][w] >= thres_fp: # 置信度筛选box_conf_f32 = sigmoid(input_tensor[0][input_loc_len + a][h][w])# 提取 loc 数组loc = np.zeros(input_loc_len, dtype=np.float32)for i in range(input_loc_len):loc[i] = input_tensor[0][i][h][w]# 进行 softmax 处理for i in range(input_loc_len // 16):loc[i * 16: (i + 1) * 16] = softmax(loc[i * 16: (i + 1) * 16])# 计算 DFL 关键点坐标xywh_ = np.zeros(4, dtype=np.float32)xywh = np.zeros(4, dtype=np.float32)for dfl in range(16):xywh_[0] += loc[dfl + 0 * 16] * dflxywh_[1] += loc[dfl + 1 * 16] * dflxywh_[2] += loc[dfl + 2 * 16] * dflxywh_[3] += loc[dfl + 3 * 16] * dflxywh_[0] = (w + 0.5) - xywh_[0]xywh_[1] = (h + 0.5) - xywh_[1]xywh_[2] = (w + 0.5) + xywh_[2]xywh_[3] = (h + 0.5) + xywh_[3]# 转换成最终的 bbox 坐标xywh[0] = ((xywh_[0] + xywh_[2]) / 2) * stridexywh[1] = ((xywh_[1] + xywh_[3]) / 2) * stridexywh[2] = (xywh_[2] - xywh_[0]) * stridexywh[3] = (xywh_[3] - xywh_[1]) * stridexywh[0] = xywh[0] - xywh[2] / 2xywh[1] = xywh[1] - xywh[3] / 2# 存储检测结果filterBoxes.append([xywh[0], xywh[1], xywh[2], xywh[3], index + h * grid_w + w]) # x, y, w, h, 关键点索引boxScores.append(box_conf_f32)classId.append(a)validCount += 1return validCount, filterBoxes, boxScores, classIddef post_process_pose(model_in_h, model_in_w, outputs, letter_box, conf_threshold=0.25, nms_threshold=0.6):"""处理姿态检测的后处理逻辑"""validCount = 0filterBoxes = []objProbs = []classId = []index = 0for i in range(3):grid_h = outputs[i].shape[2]grid_w = outputs[i].shape[3]stride = model_in_h // grid_h# Validcount, filterBoxes, Objprobs, Classidvboc = process_fp32_pose(outputs[i], stride, index, conf_threshold)validCount += vboc[0]filterBoxes += vboc[1]objProbs += vboc[2]classId += vboc[3]index += grid_h * grid_w # 下一个分辨率检测头开始的索引print(f"input_tensor.shape(kpt_tensor.shape): {outputs[-1].shape}")# 没有检测到目标if validCount <= 0:return [[], [], [], []]indexArray = list(range(validCount))# 对不同类别进行 NMS 处理unique_classes = set(classId)for c in unique_classes:nms_pose(validCount, filterBoxes, objProbs, classId, indexArray, c, nms_threshold)print(f"validCount: {validCount}")print(f"filterBoxes: {filterBoxes}")print(f"boxScores: {objProbs}")print(f"classId: {classId}")print(f"indexArray: {indexArray}")# 处理最终检测框ret_bbox = [] # 返回的检测框ret_cls = [] # 返回的类别ret_conf = [] # 返回的置信度ret_kpt = [] # 返回的关键点last_count = 0kpt_num = outputs[-1].shape[1]kpt_dim = outputs[-1].shape[2]print(f"kpt_num: {kpt_num}, kpt_dim: {kpt_dim}")for i in range(validCount):if indexArray[i] == -1 or last_count >= 300:continuen = indexArray[i]x1 = filterBoxes[n][0] - letter_box[2]y1 = filterBoxes[n][1] - letter_box[3]x2 = x1 + filterBoxes[n][2]y2 = y1 + filterBoxes[n][3]w = filterBoxes[n][2]h = filterBoxes[n][3]keypoints_index = int(filterBoxes[n][4])keypoints = np.zeros((kpt_num, kpt_dim), dtype=np.float32)for j in range(kpt_num):keypoints[j][0] = (((outputs[3][0][j][0][keypoints_index]) - letter_box[2]) / letter_box[0])keypoints[j][1] = (((outputs[3][0][j][1][keypoints_index]) - letter_box[3]) / letter_box[1])if kpt_dim == 3:keypoints[j][2] = outputs[3][0][j][2][keypoints_index]obj_cls = classId[n]obj_conf = objProbs[i]ret_bbox.append([int(clamp(x1, 0, model_in_w) / letter_box[0]),int(clamp(y1, 0, model_in_h) / letter_box[1]),int(clamp(x2, 0, model_in_w) / letter_box[0]),int(clamp(y2, 0, model_in_h) / letter_box[1])])ret_conf.append(obj_conf)ret_cls.append(obj_cls)ret_kpt.append(keypoints)last_count += 1return ret_bbox, ret_conf, ret_cls, ret_kptdef post_process_det(model_in_h, model_in_w, outputs, letter_box, conf_threshold=0.25, nms_threshold=0.6):filterBoxes = []objProbs = []classId = []validCount = 0# 默认3个分支dfl_len = outputs[0].shape[1] // 4output_per_branch = len(outputs) // 3for i in range(3):score_sum = Noneif output_per_branch == 3:score_sum = outputs[i * output_per_branch + 2]box_idx = i * output_per_branchscore_idx = i * output_per_branch + 1grid_h = outputs[box_idx].shape[2]grid_w = outputs[box_idx].shape[3]stride = model_in_h // grid_h# Validcount, filterBoxes, Objprobs, Classidvboc = process_fp32_v8(outputs[box_idx], outputs[score_idx], score_sum, stride, dfl_len, conf_threshold)validCount += vboc[0]filterBoxes += vboc[1]objProbs += vboc[2]classId += vboc[3]# 没有检测到物体if validCount <= 0:return [[], [], []]# 生成索引数组indexArray = list(range(validCount))# 进行NMSunique_classes = set(classId)for c in unique_classes:nms(validCount, filterBoxes, objProbs, classId, indexArray, c, nms_threshold)print(f"validCount: {validCount}")print(f"filterBoxes: {filterBoxes}")print(f"objProbs: {objProbs}")print(f"classId: {classId}")print(f"indexArray: {indexArray}")# 处理最终检测框ret_bbox = [] # 返回的检测框ret_cls = [] # 返回的类别ret_conf = [] # 返回的置信度last_count = 0for i in range(validCount):# 最大检测数设置为300if indexArray[i] == -1 or last_count >= 300:continuen = indexArray[i]x1 = filterBoxes[n][0] - letter_box[2]y1 = filterBoxes[n][1] - letter_box[3]x2 = x1 + filterBoxes[n][2]y2 = y1 + filterBoxes[n][3]obj_cls = classId[n]obj_conf = objProbs[i]ret_bbox.append([int(clamp(x1, 0, model_in_w) / letter_box[0]),int(clamp(y1, 0, model_in_h) / letter_box[1]),int(clamp(x2, 0, model_in_w) / letter_box[0]),int(clamp(y2, 0, model_in_h) / letter_box[1])])ret_conf.append(obj_conf)ret_cls.append(obj_cls)last_count += 1return ret_bbox, ret_conf, ret_cls
4.2.3 YOLOv8后处理文件yolov8_det_rk3588.py
封装成类:YOLOv8
实例化:yolov8_detector = YOLOv8(model_path, img_size=(384, 640), conf_thres=0.25, iou_thres=0.5)
推理:bbox, conf, cls, cost = yolov8_detector(img_rgb)
import cv2
import onnxruntime
import time
import numpy as np
from ops_rk3588 import letterbox, post_process_detclass YOLOv8:def __init__(self, model_path, img_size=(640, 640), conf_thres=0.25, iou_thres=0.7):self.input_height = img_size[0]self.input_width = img_size[1]self.conf_threshold = conf_thresself.iou_threshold = iou_thresself.initialize_model(model_path) # Initialize modeldef __call__(self, image):return self.pipeline(image)def pipeline(self, image):t0 = time.perf_counter() # start timeinput_tensor = self.prepare_input(image)t1 = time.perf_counter() # preprocess timeoutputs = self.inference(input_tensor)t2 = time.perf_counter() # model infer timeoutputs = post_process_det(self.input_height, self.input_width, outputs, letter_box=[*self.ratio, *self.dwdh],conf_threshold=self.conf_threshold, nms_threshold=self.iou_threshold)print(outputs)self.boxes, self.scores, self.class_ids = outputst3 = time.perf_counter() # total time cost, and postprocess timereturn self.boxes, self.scores, self.class_ids, (t3 - t0, t1 - t0, t2 - t1, t3 - t2)def initialize_model(self, model_path):# TODO: 排除TensorRTproviders = []if "CUDAExecutionProvider" in onnxruntime.get_available_providers():providers.append("CUDAExecutionProvider")providers.append("CPUExecutionProvider")self.session = onnxruntime.InferenceSession(model_path, providers=providers)self.get_model_details()def prepare_input(self, image):# Step 1: Get image dimensionsself.img_height, self.img_width = image.shape[:2]# Step 2: Resize to input size, convert to float32 and scale pixel values to 0 to 1im, self.ratio, self.dwdh = letterbox(image, new_shape=(self.input_height, self.input_width),color=(114, 114, 114), auto=False)im = np.ascontiguousarray(im) # contiguousim = (im.astype(np.float32) / 255.0)# Step 3: Transposeinput_tensor = im.transpose((2, 0, 1))[np.newaxis, :, :, :]return input_tensordef inference(self, input_tensor):return self.session.run(self.output_names, {self.input_names[0]: input_tensor})def get_model_details(self):model_inputs = self.session.get_inputs()model_outputs = self.session.get_outputs()self.input_names = [model_inputs[i].name for i in range(len(model_inputs))]self.output_names = [model_outputs[i].name for i in range(len(model_outputs))]if __name__ == '__main__':from ops_image import img_to_base64, get_image, resize_imagefrom ops_draw import draw_detections_pipeline# 加载模型# model_path = "../det_hand/det_hand_s_384x640_250110.onnx"model_path = "../det_kx/det_kx_yolov8sd_x0.25_384x640_250213.onnx"yolov8_detector = YOLOv8(model_path, img_size=(384, 640), conf_thres=0.25, iou_thres=0.5)# 加载图片# img_1 = "https://pic4.zhimg.com/80/v2-81b33cc28e4ba869b7c2790366708e97_1440w.webp" # URL读取img_1 = "./test_data_2.jpg"# 推理并绘制图片for img in [img_1, img_1]:img_rgb = get_image(img)img_bgr = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2BGR)# cv2.namedWindow("Output", cv2.WINDOW_NORMAL)cv2.imshow("Output", resize_image(img_bgr, 480, 480)[0])cv2.waitKey(0)bbox, conf, cls, cost = yolov8_detector(img_rgb)cost_time = [round(x * 1000, 2) for x in cost]info = (f"RUN SUCCESS: Total time: {cost_time[0]} ms, Preprocess time: {cost_time[1]} ms, "f"Inference time: {cost_time[2]} ms, Postprocess time: {cost_time[3]} ms. ")print(info)img_plot = draw_detections_pipeline(img_bgr, bbox, conf, cls)# cv2.namedWindow("Output", cv2.WINDOW_NORMAL)cv2.imshow("Output", resize_image(img_plot, 480, 480)[0])cv2.waitKey(0)
4.2.4 YOLOv8-pose后处理文件yolov8_pose_rk3588.py
封装成类(继承自YOLOv8类):YOLOv8KPT
实例化:pose_predictor = YOLOv8KPT(model_path, kpt_shape=(17, 3), img_size=(640, 640), conf_thres=0.3, iou_thres=0.5)
推理(默认一个类,没返回类别):bbox, conf, kpts, cost = pose_predictor(img_rgb)
import cv2
import time
from yolov8_det_rk3588 import YOLOv8
from ops_rk3588 import post_process_poseclass YOLOv8KPT(YOLOv8):def __init__(self, model_path, kpt_shape=(17, 3), img_size=(640, 640), conf_thres=0.6, iou_thres=0.7):super().__init__(model_path, img_size, conf_thres, iou_thres)self.kpt_shape = kpt_shape # 关键点形状def pipeline(self, image):t0 = time.perf_counter() # start timeinput_tensor = self.prepare_input(image)t1 = time.perf_counter() # preprocess timeoutputs = self.inference(input_tensor)t2 = time.perf_counter() # model infer timeoutputs = post_process_pose(self.input_height, self.input_width, outputs, letter_box=[*self.ratio, *self.dwdh],conf_threshold=self.conf_threshold, nms_threshold=self.iou_threshold)print(outputs)t3 = time.perf_counter() # total time cost, and postprocess timeself.boxes, self.scores, self.cls, self.kpt = outputsreturn self.boxes, self.scores, self.kpt, (t3 - t0, t1 - t0, t2 - t1, t3 - t2)if __name__ == '__main__':from ops_image import get_imagefrom ops_draw import draw_bboxes_and_keypointsfrom visual_config import pose_hand_cfg, pose_person_cfg# 加载模型model_path = r'../pose_ren/yolov8s-pose.onnx'# model_path = r'../pose_hand/yolov8s-pose-hand.onnx'pose_predictor = YOLOv8KPT(model_path, kpt_shape=(17, 3), img_size=(640, 640), conf_thres=0.3, iou_thres=0.5)# pose_predictor = YOLOv8KPT(model_path, kpt_shape=(21, 2), img_size=(480, 480), conf_thres=0.3, iou_thres=0.5)# 加载图片img_1 = "./img/bus.jpg"img_2 = "./img/zidane.jpg"# img_1 = "./img/pose_hand_1.jpg"# img_2 = "./img/pose_hand_2.jpg"# 推理并绘制图片for img in [img_1, img_2]:img_rgb = get_image(img)img_bgr = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2BGR)# cv2.namedWindow("Output", cv2.WINDOW_NORMAL)cv2.imshow("Output", img_bgr)cv2.waitKey(0)bbox, conf, kpts, cost = pose_predictor(img_rgb)# 将每个 17x3 的np数组展平,并存入新列表kpts = [kpt.flatten().tolist() for kpt in kpts]print(len(kpts))cost_time = [round(x * 1000, 2) for x in cost]info = (f"RUN SUCCESS: Total time: {cost_time[0]} ms, Preprocess time: {cost_time[1]} ms, "f"Inference time: {cost_time[2]} ms, Postprocess time: {cost_time[3]} ms. ")print(info)img_plot = draw_bboxes_and_keypoints(img_bgr, bbox, conf, kpts=kpts, **pose_person_cfg)# img_plot = draw_bboxes_and_keypoints(img_bgr, bbox, conf, kpts=kpts, **pose_hand_cfg)# cv2.namedWindow("Output", cv2.WINDOW_NORMAL)cv2.imshow("Output", img_plot)cv2.waitKey(0)
5. Python推理结果显示
5.1 YOLOv8结果显示
以手部检测为例:

中间结果分析(下面结果为上图最左侧女生图片的检测结果):
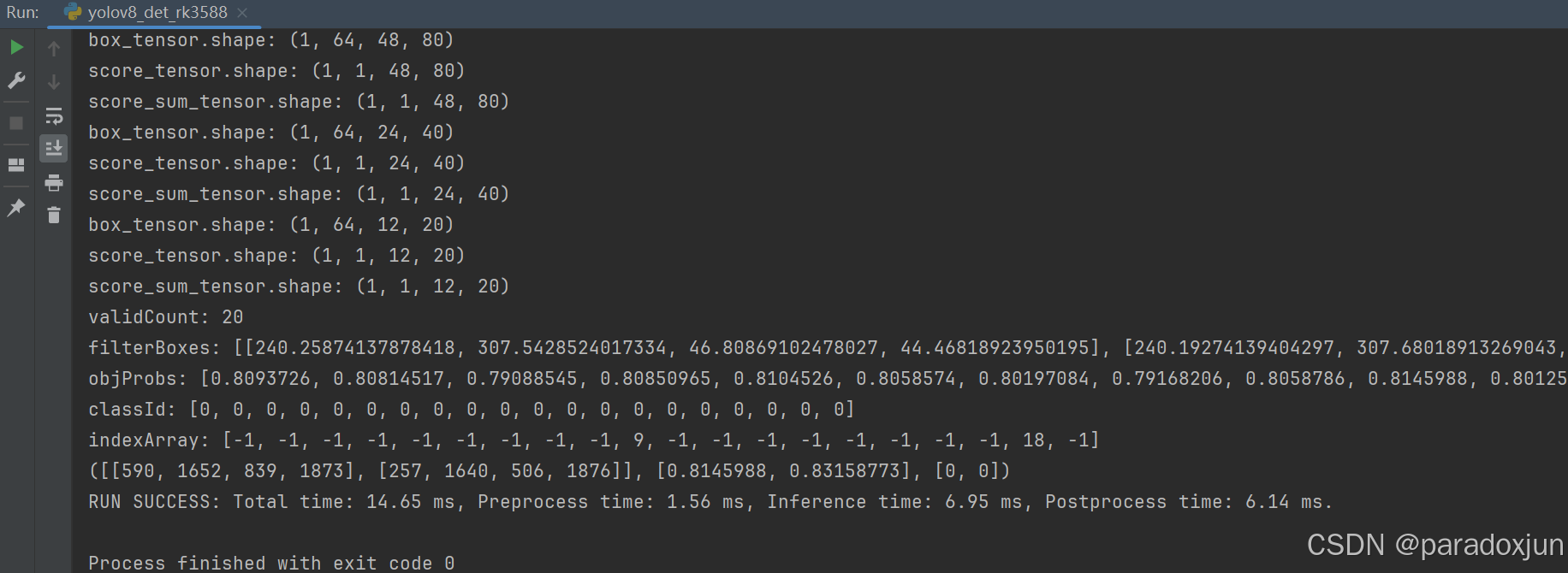
模型输入尺寸为384×640,所以第一个box_tensor形状为:[1, 64, 384 // 8, 640 // 8] == [1, 64, 48, 80],其余8个张量同理可得。
根据reduce_sum分支的张量,结合置信度阈值,过滤后,总共有20个有效待过nms的检测框。
使用nms后,有效索引对应的值为非-1.
最后经过pad_resize的逆操作,将检测框映射回原图。
原C++推理代码直接翻译过来,性能逆天,花费了6ms才处理完,转成np数组处理会极大加速(通常处理时间小于0.5ms)。
5.2 YOLOv8-pose结果显示
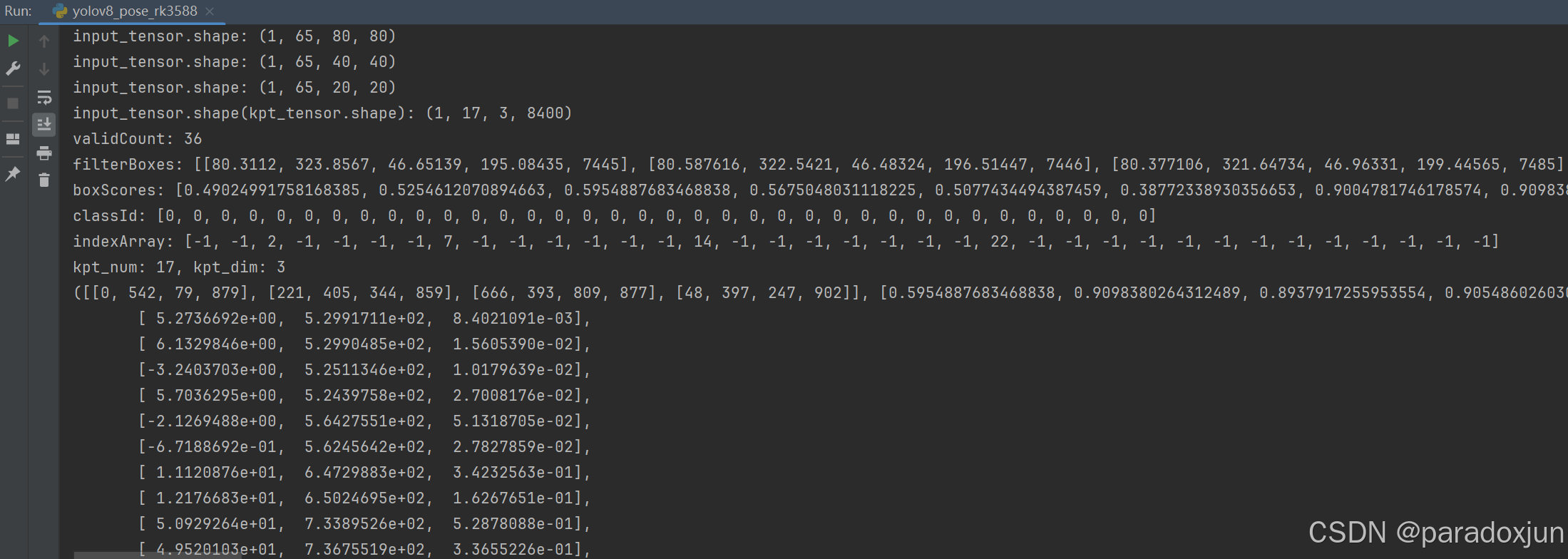
人体关键点检测结果(输入尺寸640×640,有可见不可见点之分):

打印中间处理结果:
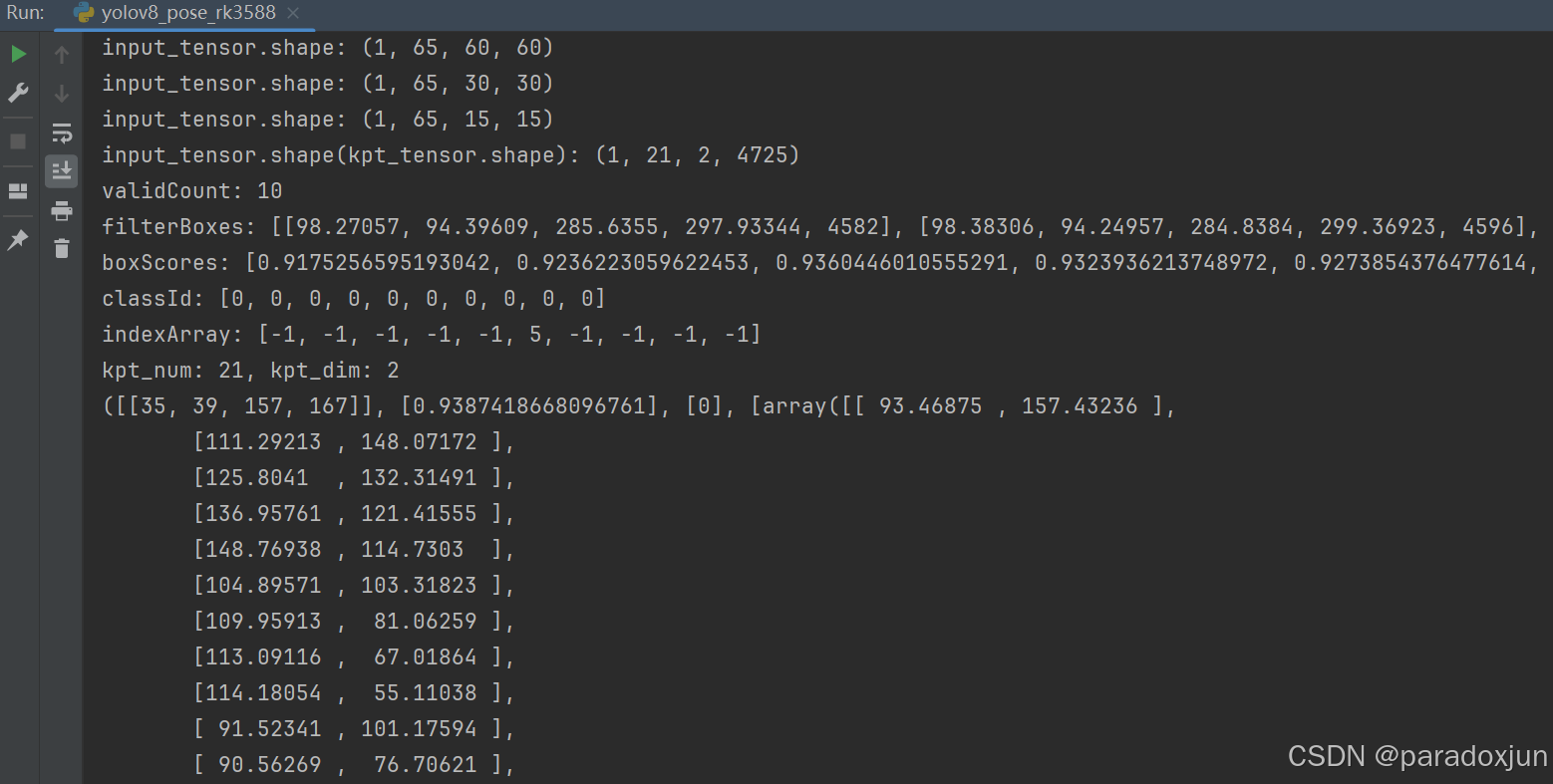
手部关键点检测结果(输入尺寸480×480,没有可见不可见点之分):

打印中间处理结果:
由于手部关键点采用自动标注,没有可见不可见之分,最后的输出结果,没有置信度。
6. 总结
使用RKNN官方代码转ONNX,主要用于在RK3588上的模型部署,方便后续ONNX转RKNN,可以使用RK官方代码一键转换+部署。转成的RKNN模型结构如下:
