钱包钱夹移动网站建设百度贴吧入口
1. 简介
- deepseek r1是对标openai o1模型的推理模型;
- 本文主要介绍GRPO作为强化学习框架,使用Deepseek-V3-Base作为基座训练deepseek r1及deepseek r1 zero。deepseek r1 zero模型仅通过Deepseek-V3-Base+RL就能达到在AIME2024 benchmark上效果超过openai-o1-0912,但存在可读性差和语言混合问题。deepseek r1则是Deepseek-V3-Base通过少量数据sft,再将sft后的模型经过RL后得到的模型,不仅解决了上面的问题,效果也远超预期。
2. 方法
2.1 DeepSeek-R1-Zero Model
2.1.1 GRPO(Group Relative Policy Optimization)
- 在强化学习中,忽略掉critic model
- 使用group scroes预估baseline
- 针对query q,GRPO首先会从旧policy π θ o l d \pi_{\theta old} πθold中sample一组回复{ o 1 , o 2 , . . . . , o G {o_1, o_2,...., o_G} o1,o2,....,oG},然后通过下面的objective优化 θ \theta θ:
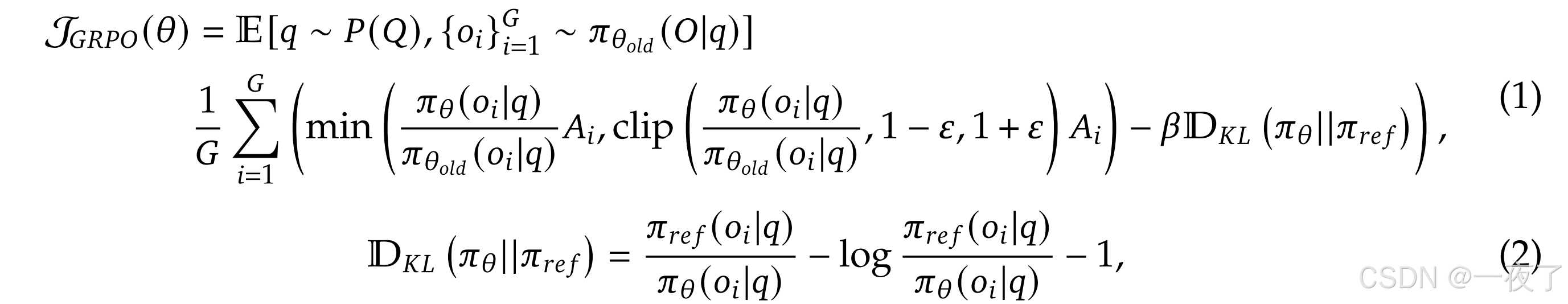
- 其中 ϵ \epsilon ϵ和 β \beta β表示超参, A i A_i Ai表示advantage,计算公式如下:
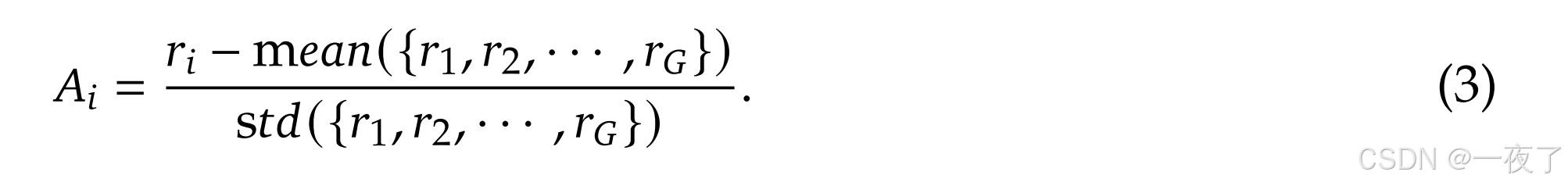
2.1.2 Reward Modeling
- 训练使用基于规则的奖励系统,由两部分组成:
- Accuracy Reward:用来评估resposne是否准确,比如说在数学问题中使用结果与标准答案是否一致作为判断标准;代码问题使用编译器的结果作为判断标准。
- Format Reward:判断回复是否符合某个格式
2.1.3 训练prompt

2.1.4 Performance
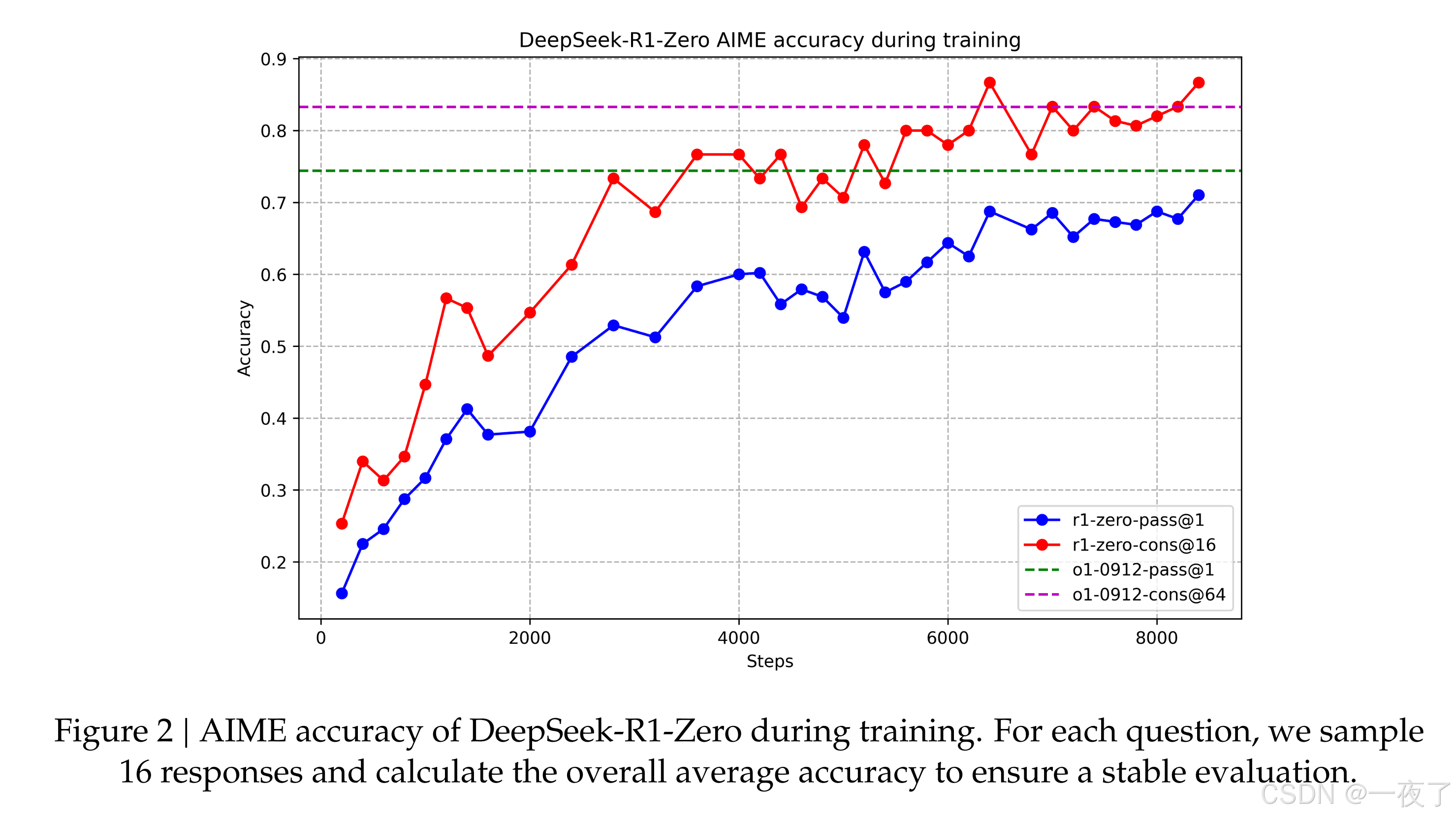
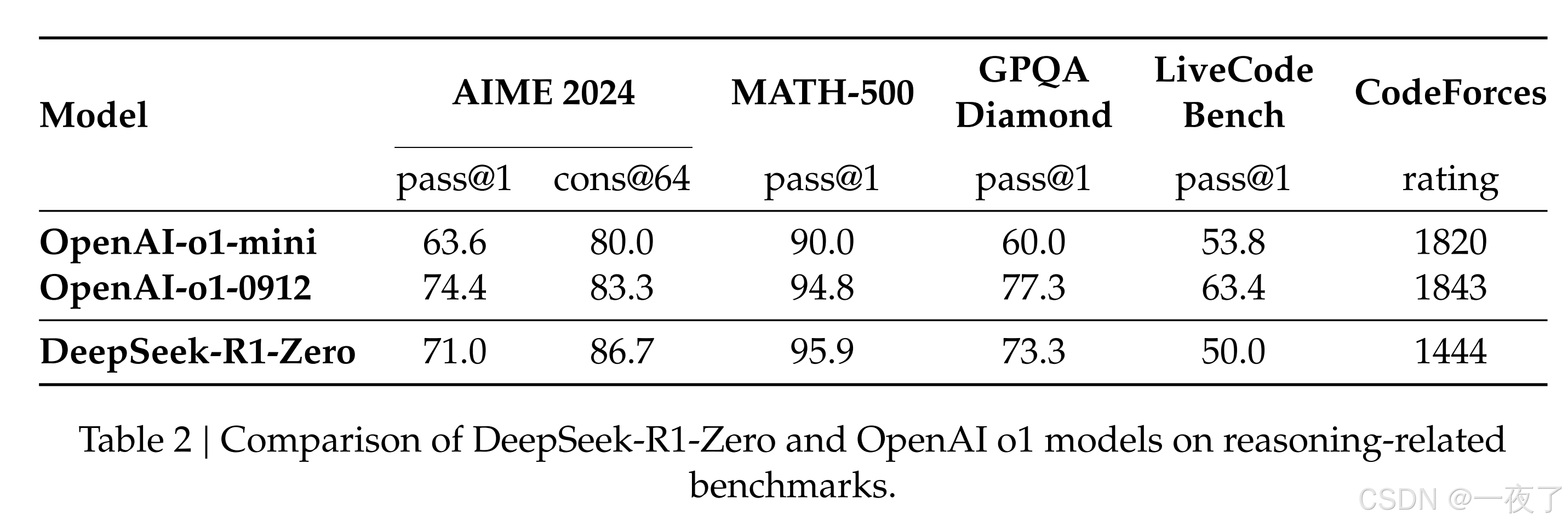
- 不需要微调就可以通过RL在推理任务中达到很好的效果;
- 使用majority voting可以进一步提升模型效果;
- Self-evolution
- 模型回复长度增加,模型在探索更多深度的思考回答复杂问题;
- 通过强化学习,模型会有类似refection,reevaluate等行为
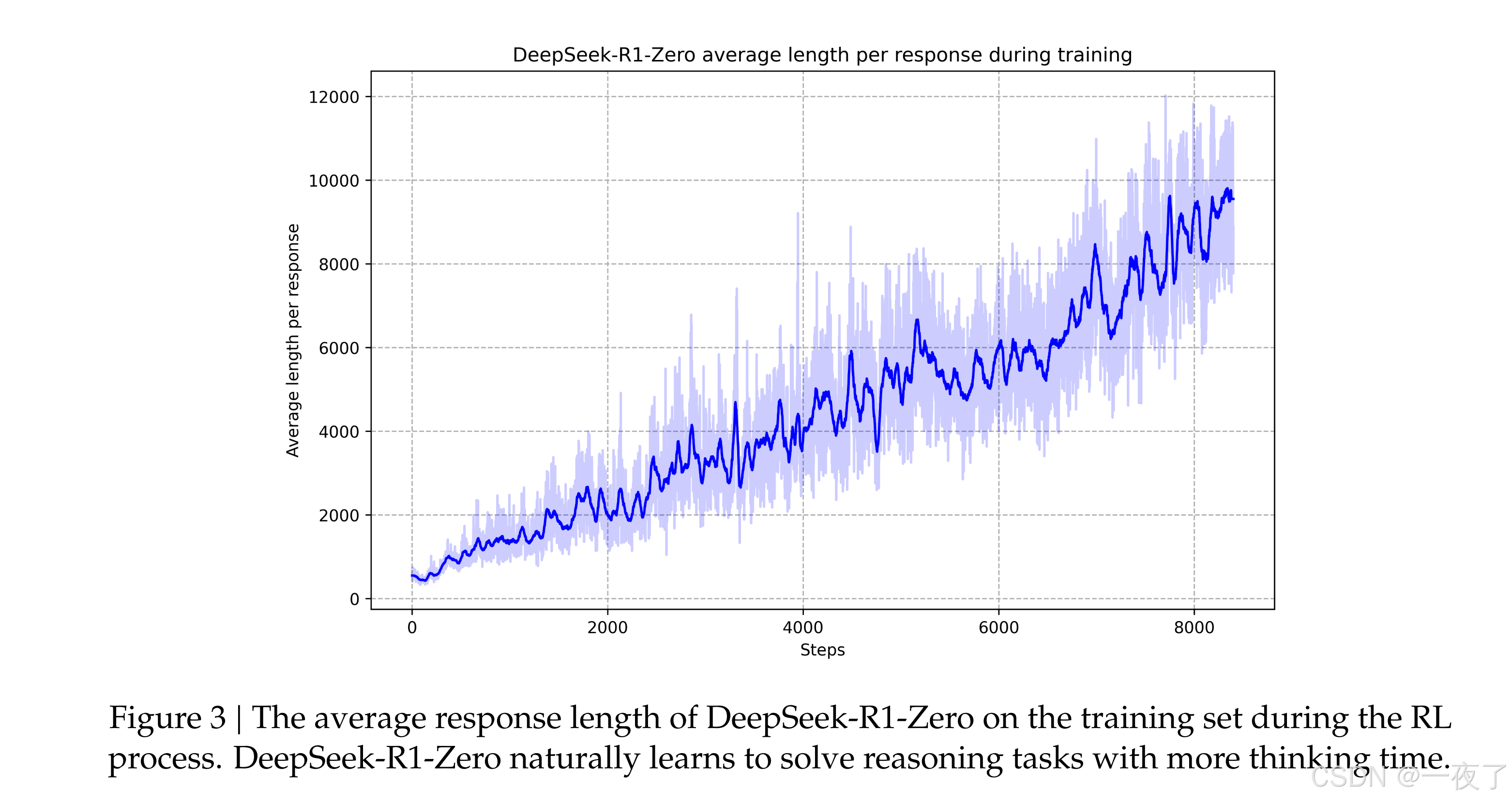
- Aha Moment of Deepseek-R1-zero

- 缺点
- 可读性差
- 语言混合
2.2 DeepSeek-R1 Model
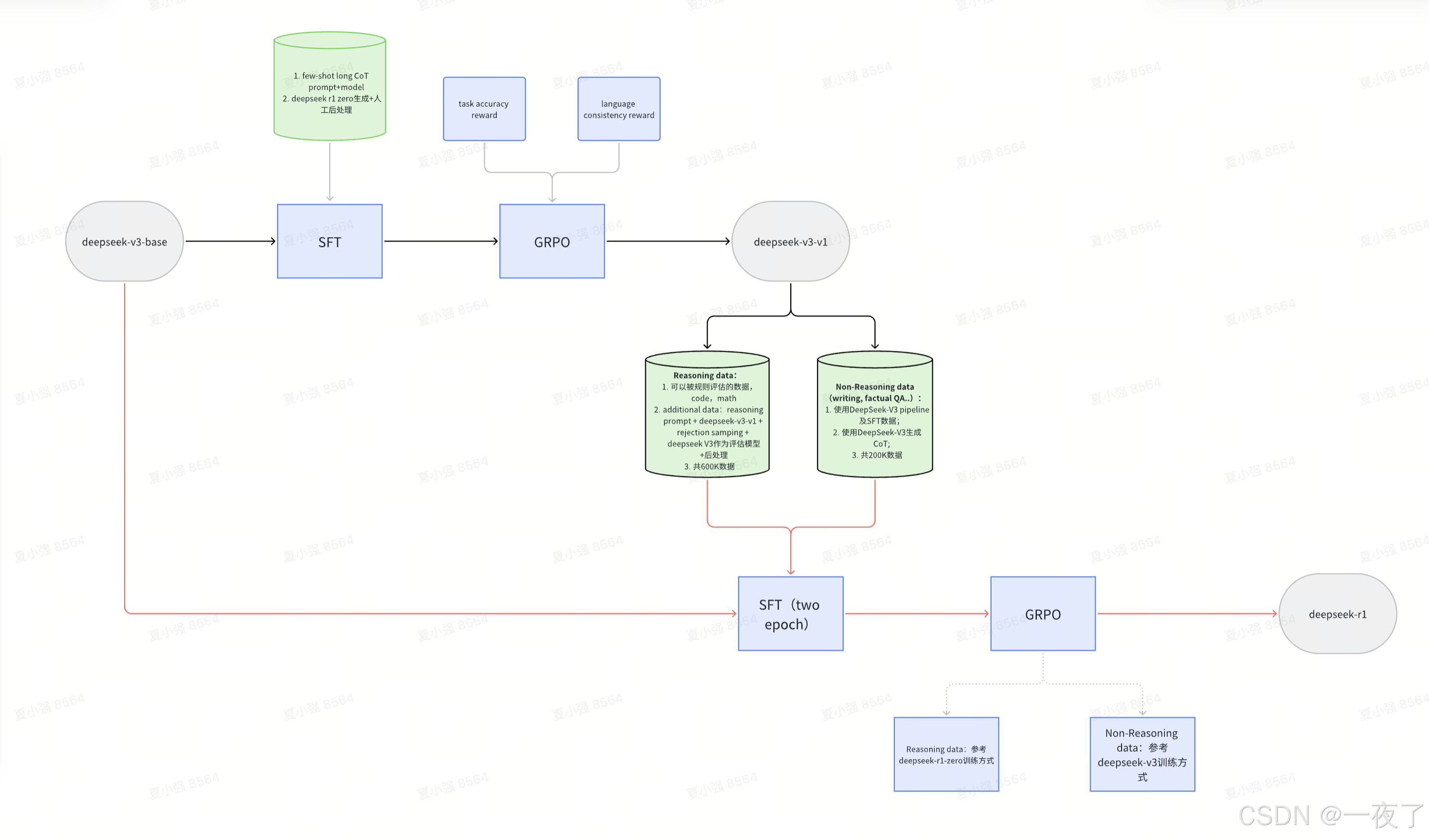
- 与DeepSeek-R1-Zero模型不同,DeepSeek-R1模型会事先准备少量的long CoT数据微调模型,然后作为RL的actor。
- 数据构建方式:1. 直接将一些long CoT数据作为few-shot,然后让模型生成带反思和校正的回复;2. 让DeepSeek-R1-Zero生成long CoT数据
- DeepSeek R1模型优点:
- 可读性:通过微调之后,回复的格式可以定义,并且没有混合语言的情况。
- 潜力:效果要好于DeepSeek R1 Zero模型
- 在得到actor后,在RL训练过程中,为了避免回复有多语言的情况,增加语言一致性的reward model,主要方式是计算回复中目标语言的占比。在整个RL过程中,使用语言一致性reward + 任务准确性reward作为最后的reward。
- 在推理任务中收敛后得到中间ckpt,再进行针对所有场景的强化学习:
- 数据:
- reasoning数据:上一步模型的训练数据仅仅是能用规则得到reward的数据,这步需要加上一些额外的数据。主要通过中间ckpt 采样生成reasoning data和一些额外数据的回复,然后使用通用reward model判断好坏 + 后处理;最终得到600K数据
- 非reasoning数据:类似writing, factual QA, self-cognition, and translation等数据,主要是deepseek v3 pipeline以及部分V3 SFT数据,然后用deepseek v3得到CoT部分。最终得到200K数据。
- 最后得到800K数据
- 训练:
- 第一步:使用800K数据微调deepseek v3 base 模型;
- 第二步:用第一步的模型进行强化学习
- 在reasoning任务中,参考deepseek r1 zero训练方式
- 在general任务,参考deepseek v3 pipeline
- 数据:
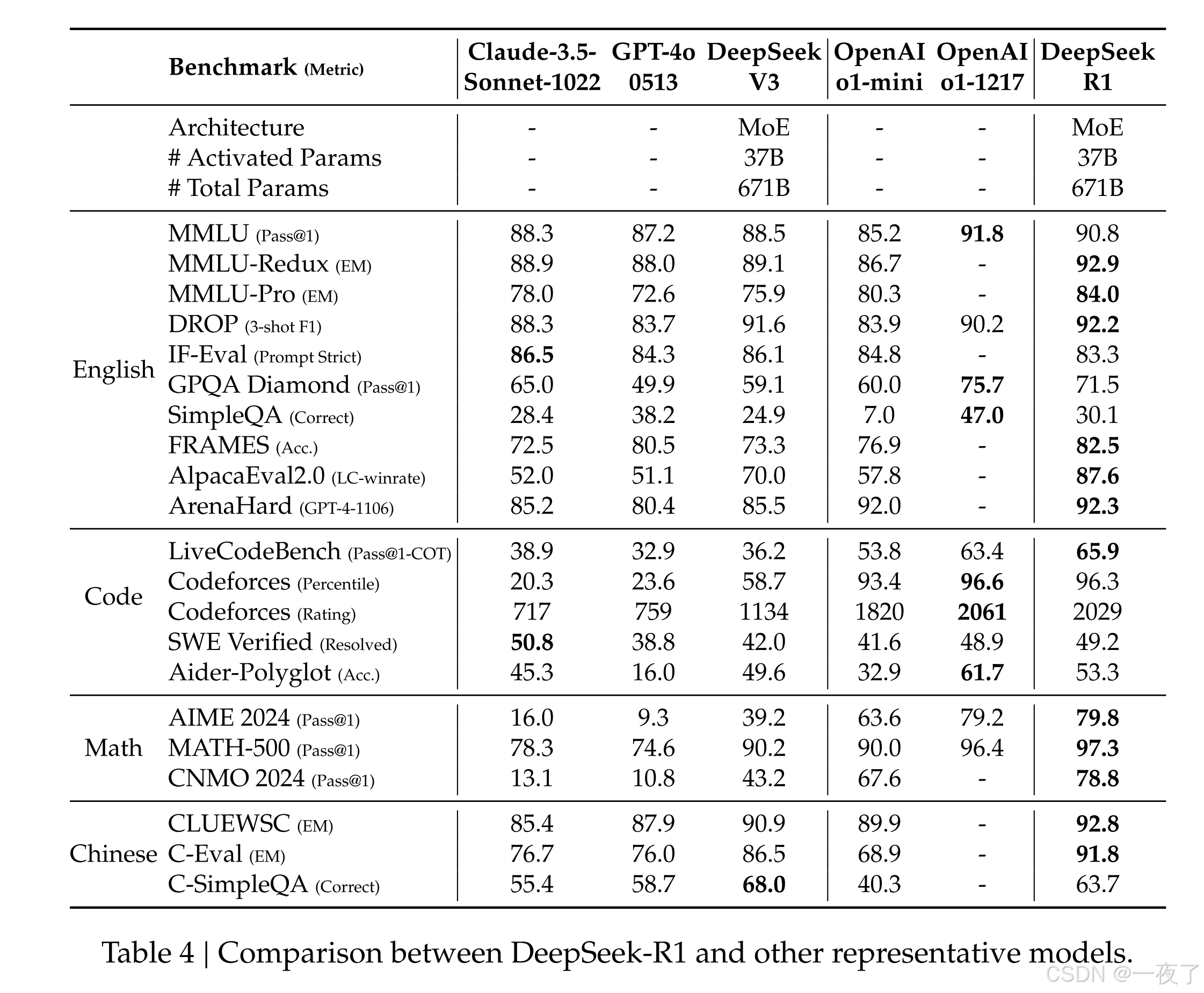
3. 实验
4. 小结
文章展示cold start和non cold start两种RL训练方式,总体而言,两种方法都有效。但non cold start的方式会有一些问题,比如说语言混合,可读性差。但使用cold start不仅在效果上超过non cold start的方式,在可读性及语言一致性问题上也得到解决
5. 参考文献:
- 1) https://weibo.com/ttarticle/p/show?id=2309405125956833771966&mark_id=999_reallog_mark_ad%3A999%7CWeiboADNatural
- 2)https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf