那个网站学做披萨比较好四川省最新疫情情况
在电商数据分析、市场调研或竞品分析中,获取商品列表信息是常见的需求。微店作为知名的电商平台,提供了丰富的商品资源和相应的 API 接口。本文将详细介绍如何使用 Python 爬虫技术,通过微店的 item_search 接口根据关键词搜索商品列表,并获取相关数据。
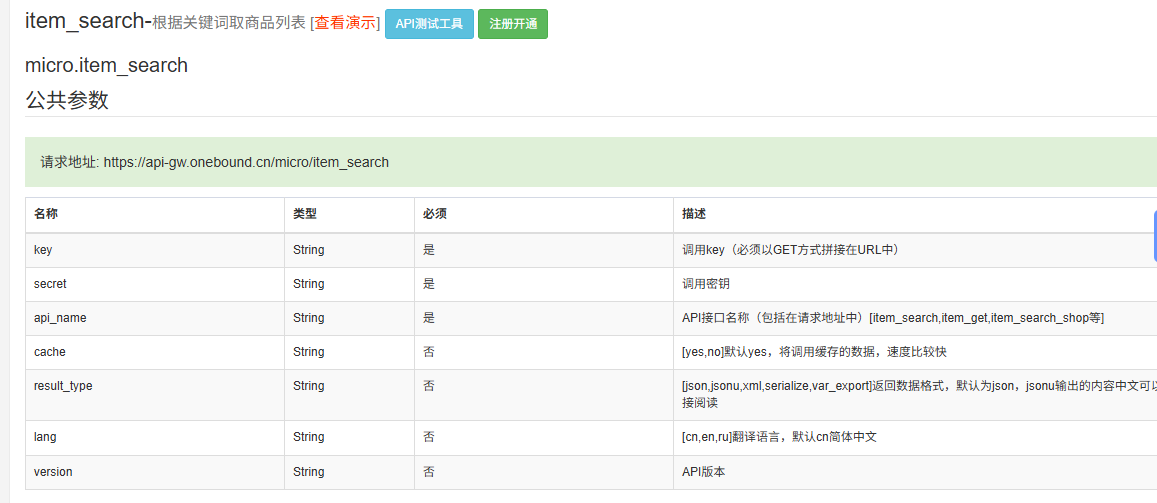
一、微店 item_search 接口简介
微店的 item_search 接口允许开发者通过关键词搜索商品列表,获取商品的基本信息,如商品名称、价格、图片、销量等。该接口通常以 RESTful API 的形式提供,返回 JSON 格式的数据。
二、准备工作
(一)安装 Python 库
在开始爬虫开发之前,需要安装一些必要的 Python 库,包括:
-
requests:用于发送 HTTP 请求。 -
json:用于处理 JSON 格式的数据。 -
pandas:用于数据存储和分析。
可以通过以下命令安装这些库:
bash
pip install requests pandas(二)获取 API 凭证
在调用微店的接口之前,需要在微店开放平台注册成为开发者,并创建应用以获取 API 凭证,如 App Key 和 App Secret。这些凭证用于获取 Access Token,是调用接口所必需的。
(三)获取 Access Token
Access Token 是调用接口的授权凭证,可以通过以下方式获取:
-
发起 POST 请求到
https://open.weidian.com/api/oauth2/token。 -
在请求体中包含
grant_type=client_credentials、client_id=YOUR_CLIENT_ID和client_secret=YOUR_CLIENT_SECRET。
示例代码:
Python
import requestsdef get_access_token(client_id, client_secret):url = "https://open.weidian.com/api/oauth2/token"data = {"grant_type": "client_credentials","client_id": client_id,"client_secret": client_secret}response = requests.post(url, data=data)if response.status_code == 200:return response.json().get("access_token")else:print("获取 Access Token 失败,状态码:", response.status_code)return None三、实战代码
(一)根据关键词搜索商品列表
以下是使用 requests 库调用 item_search 接口的代码示例:
Python
def search_items_by_keyword(keyword, access_token):url = f"https://api.weidian.com/openapi/item/search?access_token={access_token}"params = {"keyword": keyword,"page": 1, # 可选参数,指定页码"page_size": 10 # 可选参数,每页返回的商品数量}response = requests.get(url, params=params)if response.status_code == 200:return response.json()else:print("请求失败,状态码:", response.status_code)return None(二)解析商品列表数据
获取到的数据为 JSON 格式,可以通过以下代码解析并提取关键信息:
Python
def parse_item_list(data):items = data.get("items", [])parsed_items = []for item in items:item_id = item.get("item_id")title = item.get("title")price = item.get("price")image = item.get("image")sales = item.get("sales")parsed_items.append({"商品ID": item_id,"商品名称": title,"价格": price,"图片": image,"销量": sales})return parsed_items(三)存储数据到 CSV 文件
解析后的数据可以存储到 CSV 文件中,方便后续分析:
Python
import pandas as pddef save_to_csv(data, filename):df = pd.DataFrame(data)df.to_csv(filename, index=False, encoding="utf-8-sig")print(f"数据已保存到 {filename}")# 示例:搜索关键词为 "生日项链" 的商品列表
keyword = "生日项链"
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"access_token = get_access_token(client_id, client_secret)
if access_token:item_list_data = search_items_by_keyword(keyword, access_token)if item_list_data:parsed_items = parse_item_list(item_list_data)save_to_csv(parsed_items, "item_list.csv")四、注意事项
(一)遵守法律法规
在爬取数据时,必须遵守相关法律法规,不得侵犯他人合法权益。
(二)处理反爬虫机制
微店可能会限制请求频率或验证用户身份。建议合理控制请求频率,并设置合适的请求头。
(三)数据准确性
获取到的数据可能存在不准确或不完整的情况。在使用数据之前,需要进行数据清洗和验证。
五、总结
通过本文的介绍,你已经学会了如何使用 Python 爬虫技术爬取微店的 item_search 接口,根据关键词搜索商品列表并获取相关数据。这不仅可以帮助你自动化获取商品信息,还可以为你的数据分析和电商运营提供支持。
如果你对 Python 爬虫技术感兴趣,可以继续深入学习相关的知识和技能,如动态网页爬取或分布式爬虫。同时,也可以关注微店开放平台的其他接口,以获取更多有价值的数据。
如遇任何疑问或有进一步的需求,请随时与我私信或者评论联系。