怎样经营好一个网站国内最新消息新闻
1 DQN
1.1 状态价值估计
deep qlearning算法
https://hugging-face.cn/learn/deep-rl-course/unit2/mid-way-quiz
贝尔曼方程:

蒙特卡洛方法和时序差分方法(TD):


要训练一个价值函数,衡量每一个状态的价值。
如何衡量呢?用该状态的回报来评估。
比如玩游戏每一帧是一个状态,t时刻状态的价值 就是 t时刻之后的总的回报。
蒙特卡洛方法是玩一遍玩到结束,然后可以得到t时刻之后总的回报。 玩很多次求平均无偏估计。
TD方法是玩一步,然后估计t时刻之后总的回报。
就是上面的2个图。
1.2 Q-Learning 是一种离策略的、基于价值的方法,它使用 TD 方法来训练其动作价值函数
状态动作价值函数可以看做一个二维表格:
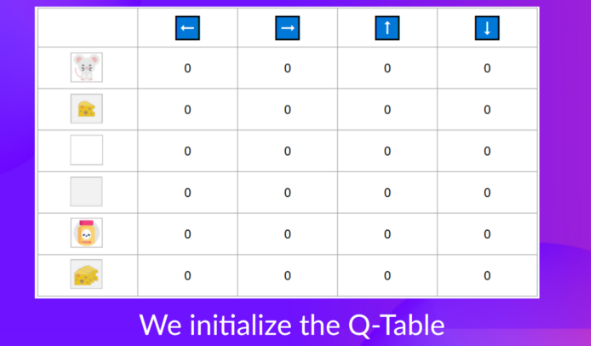
假如我们通过训练得到了Qtable,那么他们就可以知道每个状态应该走哪一步。走该状态(某一行)动作价值最大的那一步。

1.3 ε-贪心策略是一种处理探索/利用权衡的策略
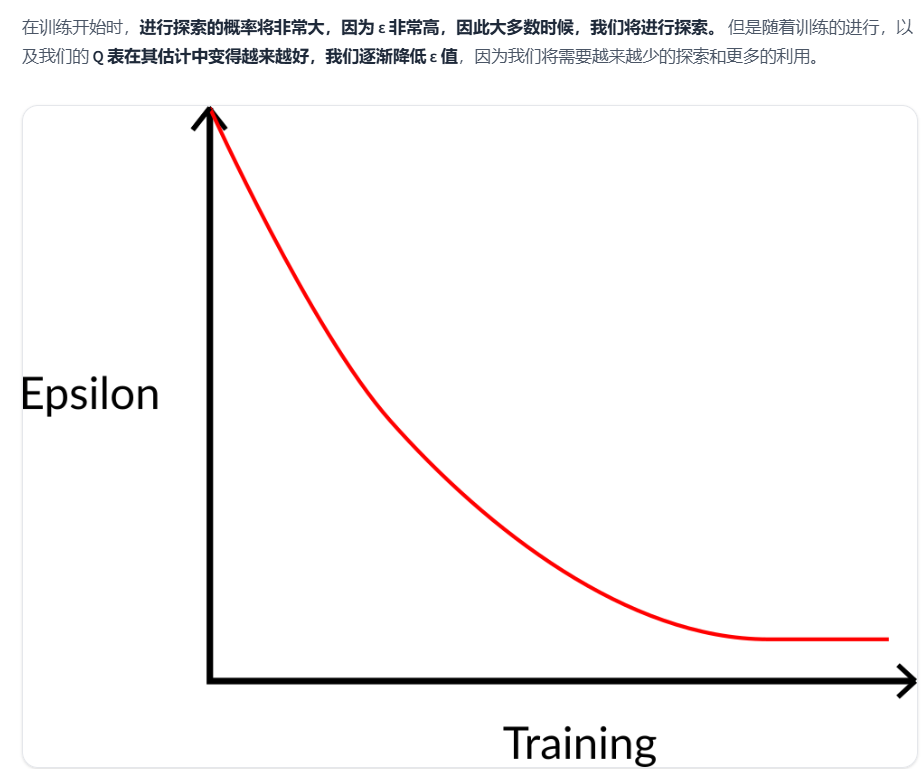
Qtable是离散的,因此每一行的最大值也就是每个状态的最优动作一般是可以确定的。但是前期模型效果不好,我们希望随机性大一些,模型训练的越来越好的时候,使用最优动作的概率变大。
1.4 执行动作
通过1.3执行动作之后,环境给出 即时奖励和下一步状态。
关于即时奖励和下一步状态,这一部分是环境定义的,不是RL算法。因此我们需要了解env的特点,甚至做一个任务的时候,我们要自己定义自己的env,状态是什么,动作有哪些,什么情况下有奖励等等。就算使用gymnsium已经定义好的环境,我们也要了解其观察空间,动作空间,奖励是什么。这一部分真的很重要,就是环境。
1.5 更新状态-动作价值
TD target很重要,就是即时奖励 + 下一个状态的 价值
下一个状态的价值,这里使用的最优的状态动作价值来表示。 np.max(Q[state])

1.6 离策略和同策略
采用的是ε-贪心策略 这样保证有一定的探索性质
更新状态动作价值的时候,才用的是完全贪心策略
所以是离策略。只是一个概念。
1.7 deep Qlearning
Q-Learning 是一种用于训练 Q 函数的算法,Q 函数是一种动作价值函数,它确定在特定状态并采取特定动作的价值。
deep Qlearning 用神经网络来表示Q函数(Qtable), 输入状态,输出的是动作价值
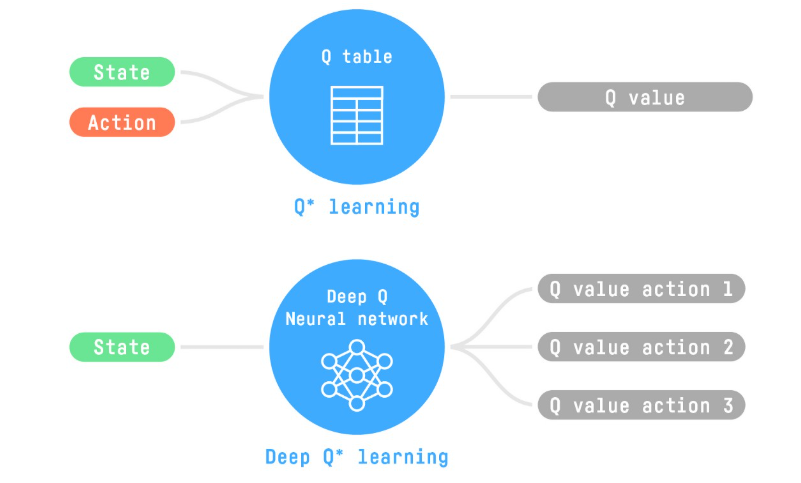
可想而知的是,得到每个动作的价值之后,价值最大的动作就是我们需要的动作。
loss:
分析一下,为什么是这样? target引入了新的即时奖励也就是我们实际走一步的奖励,引入了实际的信息。来更新Q
# 定义Q网络
class QNetwork(nn.Module):def __init__(self, state_size, action_size, hidden_size=64):super(QNetwork, self).__init__()self.fc1 = nn.Linear(state_size, hidden_size)self.fc2 = nn.Linear(hidden_size, hidden_size)self.fc3 = nn.Linear(hidden_size, action_size)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))return self.fc3(x)
1.8 DQN阶段
深度 Q 学习训练算法有两个阶段
采样:我们执行动作并将观察到的经验元组存储在回放记忆中。
训练:随机选择一个小批量的元组,并使用梯度下降更新步骤从此批次中学习
TD算法虽然是每一步 更新一次,但是对于深度学习训练,还是要采集多一些数据进行批次训练效果更好。虽然也不必像蒙特卡洛方法那样玩完整局游戏。
1.9 特点
- 经验回放
就是缓冲我们玩的游戏,1.可以重复利用这些经验,避免忘记以前的经验, 2.随机取出一批,消除连续状态的相关性。
初始化一个容量为 N 的回放记忆缓冲区 D。N是超参数
buffer存储经验序列
class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def add(self, state, action, reward, next_state, done):self.buffer.append(Experience(state, action, reward, next_state, done))def sample(self, batch_size):experiences = random.sample(self.buffer, k=batch_size)states = torch.FloatTensor(np.array([e.state for e in experiences])).unsqueeze(1)actions = torch.LongTensor(np.array([e.action for e in experiences])).unsqueeze(1)rewards = torch.FloatTensor(np.array([e.reward for e in experiences])).unsqueeze(1)next_states = torch.FloatTensor(np.array([e.next_state for e in experiences])).unsqueeze(1)dones = torch.FloatTensor(np.array([e.done for e in experiences]).astype(np.uint8)).unsqueeze(1)return states, actions, rewards, next_states, donesdef __len__(self):return len(self.buffer)
- 固定Q目标
在1.7种target是 R(t+1) + discounted estimate optimal Q-value of next state。 当我们想要计算 TD 误差(又名损失)时,我们计算 TD 目标(Q 目标)和当前 Q 值(Q 的估计值)之间的差异。Q就是神经网路,目标和估计中都有Q
但是,我们 对真实的 TD 目标没有任何概念。我们需要估计它。使用贝尔曼方程,我们看到 TD 目标只是在该状态下采取该动作的奖励,加上下一个状态的折扣最高 Q 值。然而,问题是我们使用相同的参数(权重)来估计 TD 目标 和 Q 值。因此,TD 目标和我们正在更改的参数之间存在显着的相关性。因此,在训练的每一步,我们的 Q 值和目标值都会发生偏移。我们正在接近我们的目标,但目标也在移动。这就像追逐移动的目标!这可能会导致训练中出现明显的振荡。
因此采取:
使用 具有固定参数的单独网络 来估计 TD 目标,其实就是每 C 步从我们的深度 Q 网络复制参数 以更新目标网络。 C是超参数
相当于用就网络作为目标,没关系,R(t+1)是主要的收益,因此目标还是更好。
- 双重DQN
训练开始时,我们没有关于要采取的最佳动作的足够信息。因此,将最大 Q 值(这是有噪声的)作为要采取的最佳动作可能会导致误报。如果非最优动作经常被赋予比最优最佳动作更高的 Q 值,那么学习将变得复杂。
解决方案是:当我们计算 Q 目标时,我们使用两个网络将动作选择与目标 Q 值生成解耦。我们
使用我们的 DQN 网络 来选择下一个状态要采取的最佳动作(具有最高 Q 值的动作)。
使用我们的 目标网络 来计算在该状态下采取该动作的目标 Q 值。
因此,双重 DQN 帮助我们减少 Q 值的过高估计,并因此帮助我们更快、更稳定地进行训练。

2.10 code实现(不包含双重DQN)
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import random
from collections import deque, namedtuple# 设置随机种子
def set_seed(seed):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)if torch.cuda.is_available():torch.cuda.manual_seed(seed)# 定义经验回放缓冲区
Experience = namedtuple('Experience', ['state', 'action', 'reward', 'next_state', 'done'])class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def add(self, state, action, reward, next_state, done):self.buffer.append(Experience(state, action, reward, next_state, done))def sample(self, batch_size):experiences = random.sample(self.buffer, k=batch_size)states = torch.FloatTensor(np.array([e.state for e in experiences])).unsqueeze(1)actions = torch.LongTensor(np.array([e.action for e in experiences])).unsqueeze(1)rewards = torch.FloatTensor(np.array([e.reward for e in experiences])).unsqueeze(1)next_states = torch.FloatTensor(np.array([e.next_state for e in experiences])).unsqueeze(1)dones = torch.FloatTensor(np.array([e.done for e in experiences]).astype(np.uint8)).unsqueeze(1)return states, actions, rewards, next_states, donesdef __len__(self):return len(self.buffer)# 定义Q网络
class QNetwork(nn.Module):def __init__(self, state_size, action_size, hidden_size=64):super(QNetwork, self).__init__()self.fc1 = nn.Linear(state_size, hidden_size)self.fc2 = nn.Linear(hidden_size, hidden_size)self.fc3 = nn.Linear(hidden_size, action_size)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))return self.fc3(x)# DQN智能体
class DQNAgent:def __init__(self, state_size, action_size, hidden_size=64, lr=1e-3, gamma=0.99, epsilon_start=1.0, epsilon_end=0.01, epsilon_decay=0.995, buffer_size=10000, batch_size=64, update_every=4, tau=1e-3):self.state_size = state_sizeself.action_size = action_sizeself.gamma = gammaself.epsilon = epsilon_startself.epsilon_end = epsilon_endself.epsilon_decay = epsilon_decayself.batch_size = batch_sizeself.update_every = update_everyself.tau = tau# Q-Networkself.qnetwork_local = QNetwork(state_size, action_size, hidden_size)self.qnetwork_target = QNetwork(state_size, action_size, hidden_size)self.optimizer = optim.Adam(self.qnetwork_local.parameters(), lr=lr)# 经验回放self.memory = ReplayBuffer(buffer_size)self.t_step = 0def step(self, state, action, reward, next_state, done):# 保存经验到回放缓冲区self.memory.add(state, action, reward, next_state, done)# 每隔update_every步学习一次self.t_step = (self.t_step + 1) % self.update_everyif self.t_step == 0 and len(self.memory) > self.batch_size:experiences = self.memory.sample(self.batch_size)self.learn(experiences)def act(self, state, eps=None):if eps is None:eps = self.epsilon# 以epsilon概率随机选择动作,否则选择最优动作if random.random() > eps:state = torch.from_numpy(state).float().unsqueeze(0)self.qnetwork_local.eval()with torch.no_grad():action_values = self.qnetwork_local(state)self.qnetwork_local.train()return np.argmax(action_values.cpu().data.numpy())else:return random.choice(np.arange(self.action_size))def learn(self, experiences):states, actions, rewards, next_states, dones = experiences# 获取目标Q值Q_targets_next = self.qnetwork_target(next_states).detach().max(1)[0].unsqueeze(1)Q_targets = rewards + (self.gamma * Q_targets_next * (1 - dones))# 获取当前Q值Q_expected = self.qnetwork_local(states).gather(1, actions)# 计算损失loss = F.mse_loss(Q_expected, Q_targets)# 最小化损失self.optimizer.zero_grad()loss.backward()self.optimizer.step()# 更新目标网络self.soft_update(self.qnetwork_local, self.qnetwork_target)# 更新epsilonself.epsilon = max(self.epsilon_end, self.epsilon * self.epsilon_decay)def soft_update(self, local_model, target_model):"""软更新目标网络参数: θ_target = τ*θ_local + (1 - τ)*θ_target"""for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):target_param.data.copy_(self.tau * local_param.data + (1.0 - self.tau) * target_param.data)import gym
import numpy as np
import matplotlib.pyplot as plt
from dqn import DQNAgent, set_seed# 训练DQN智能体
def train_dqn(env_name, n_episodes=1000, max_t=1000, eps_start=1.0, eps_end=0.01, eps_decay=0.995):env = gym.make(env_name)set_seed(42)env.seed(42)state_size = env.observation_space.shape[0]action_size = env.action_space.nagent = DQNAgent(state_size=state_size, action_size=action_size)scores = [] # 记录每回合的得分scores_window = deque(maxlen=100) # 最近100回合的得分eps = eps_start # 初始化epsilonfor i_episode in range(1, n_episodes+1):state = env.reset()score = 0for t in range(max_t):action = agent.act(state, eps)next_state, reward, done, _ = env.step(action)agent.step(state, action, reward, next_state, done)state = next_statescore += rewardif done:breakscores_window.append(score) # 保存最近的得分scores.append(score) # 保存所有得分eps = max(eps_end, eps_decay*eps) # 减小epsilonprint(f'\rEpisode {i_episode}\tAverage Score: {np.mean(scores_window):.2f}', end="")if i_episode % 100 == 0:print(f'\rEpisode {i_episode}\tAverage Score: {np.mean(scores_window):.2f}')if np.mean(scores_window) >= 200.0: # 对于LunarLander-v2,目标是达到200分print(f'\nEnvironment solved in {i_episode-100} episodes!\tAverage Score: {np.mean(scores_window):.2f}')torch.save(agent.qnetwork_local.state_dict(), f'dqn_{env_name}.pth')break# 绘制得分plt.figure(figsize=(10, 6))plt.plot(np.arange(len(scores)), scores)plt.ylabel('Score')plt.xlabel('Episode #')plt.title(f'Training Progress for {env_name}')plt.savefig(f'dqn_{env_name}_training.png')plt.show()env.close()return scores# 评估DQN智能体
def evaluate_dqn(env_name, model_path, n_episodes=10, render=True):env = gym.make(env_name)set_seed(42)env.seed(42)state_size = env.observation_space.shape[0]action_size = env.action_space.nagent = DQNAgent(state_size=state_size, action_size=action_size)agent.qnetwork_local.load_state_dict(torch.load(model_path))scores = []for i_episode in range(n_episodes):state = env.reset()score = 0done = Falsewhile not done:if render:env.render()action = agent.act(state, eps=0.0) # 完全贪心策略next_state, reward, done, _ = env.step(action)state = next_statescore += rewardscores.append(score)print(f'Episode {i_episode+1}/{n_episodes}, Score: {score:.2f}')avg_score = np.mean(scores)print(f'Average Score over {n_episodes} episodes: {avg_score:.2f}')env.close()return avg_score# 主函数
if __name__ == "__main__":env_name = "LunarLander-v2" # 可以尝试其他环境如 "CartPole-v1"# 训练print("开始训练...")scores = train_dqn(env_name)# 评估print("开始评估...")avg_score = evaluate_dqn(env_name, f'dqn_{env_name}.pth')