行业网站需要如何做搜索引擎优化的基本手段
Stream流与File类
Stream流
简化集合和数组的操作,
startWith(“张”)
第一个为这个返回true
String
1.获取Stream对象
单列集合
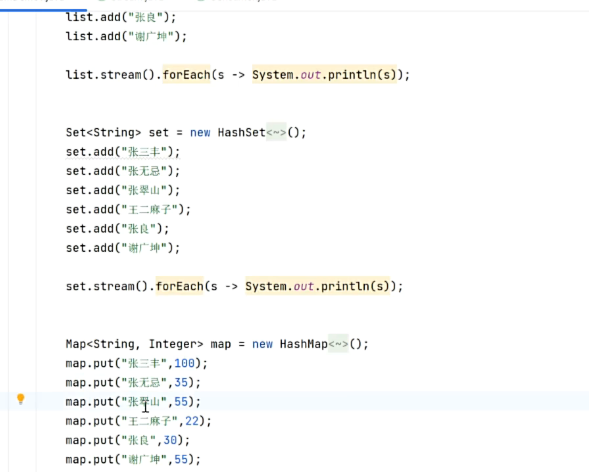
双列集合
先获得键值对
在遍历
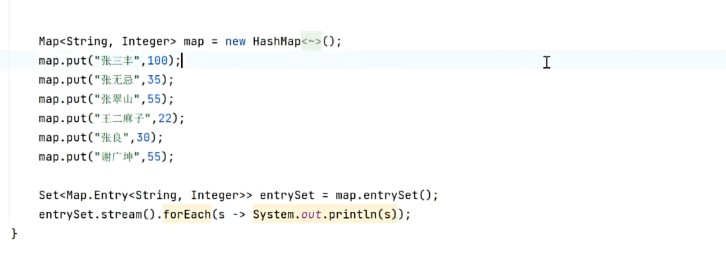
数组

零散的数据
Stream<Integer> arr=Stream.of(1,2,34,3);
stream.forEach(sss);
即可
2.中间方法
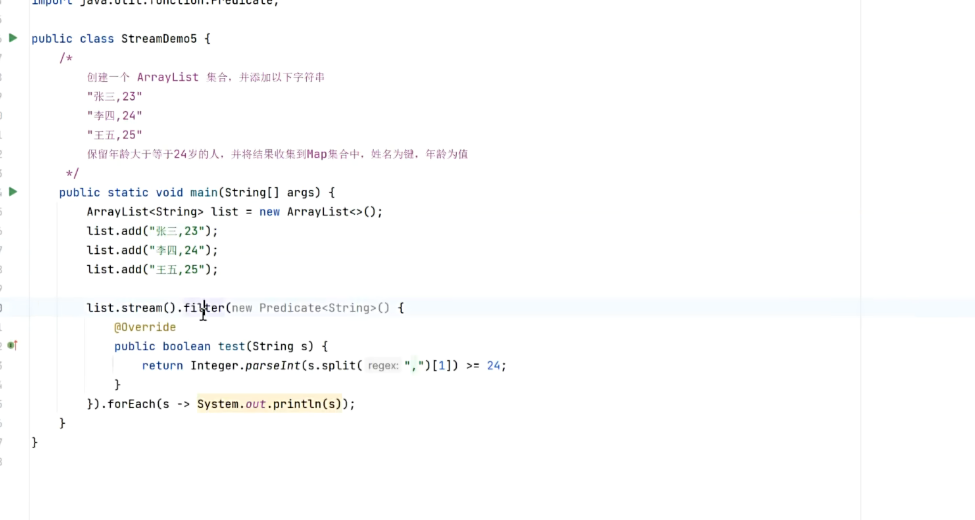
filter
在集合当中,对数据进行过滤
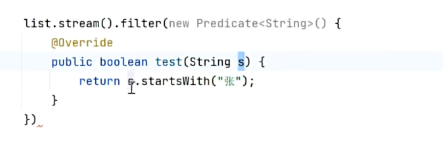
重写Predicate类,符合条件的返回true,不符合的返回false
他的返回值,仍然是一个Stream流对象,所以称之为中间过程
ArrayList<String> arr=new ArrayList<>();arr.add("dasd");arr.add("basd");arr.add("dad");arr.add("dsa");arr.stream().filter(s -> s.startsWith("d")).filter(s->s.endsWith("d")).forEach(s-> System.out.println(s));
limit
arr.stream().limit(3).forEach(s->System.out.println(s));使用limit(int length);//限制多少个元素
skip
arr.stream().skip(3).forEach(s->System.out.println(s));使用skip(int length);//跳过多少个元素
limit和skip是可以一起用的
concat
Stream.concat(Stream a,Stream b);
将两个流进行合并,但是注意一点,不会进行去重哦
distinct
arr.distinct();进行操作即可
依赖的是hashcode和equals方法,所以需要注意一点,在我们自己创建对象的时候,需要重写这两个方法注意一下,如果一个流已经被消费过或者是进行使用过,那么这个流就相当于关闭了,就不能再进行操作了!!!!!!!!!
3.终结方法
流水线的最后一个操作。
进行该类的操作之后,就不能再进行操作了,因为相当于是最后一个操作了
forEach
遍历数组
count
查看有多少个方法
4.收集操作
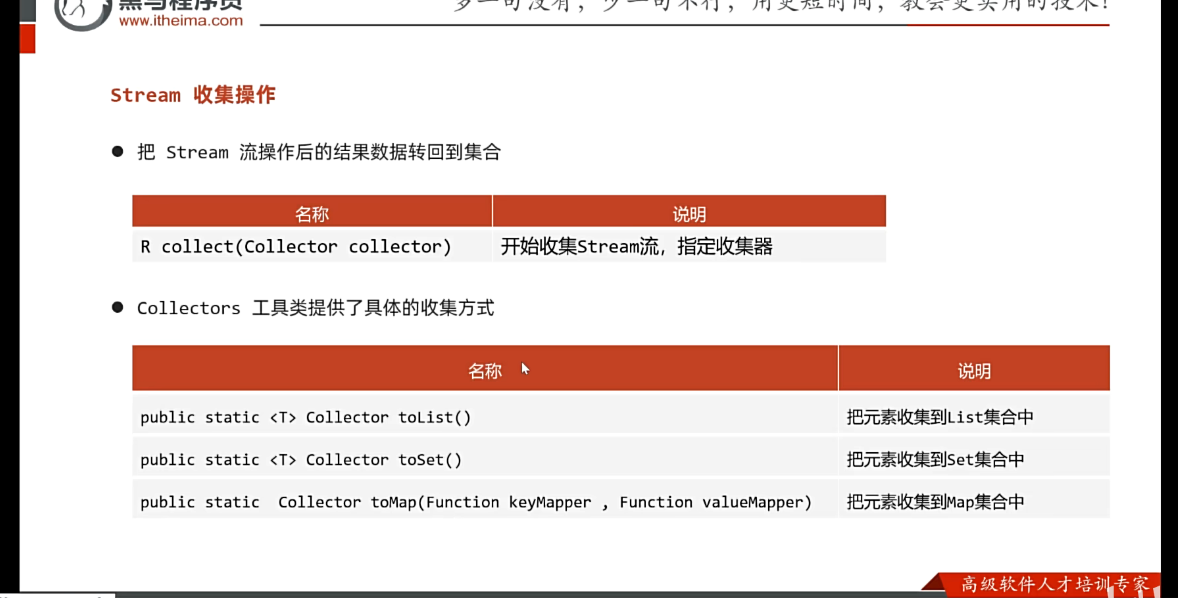
把stream流操作后的结果数据转回到集合
不会修改数据源
Collector
toList,toSet

toMap
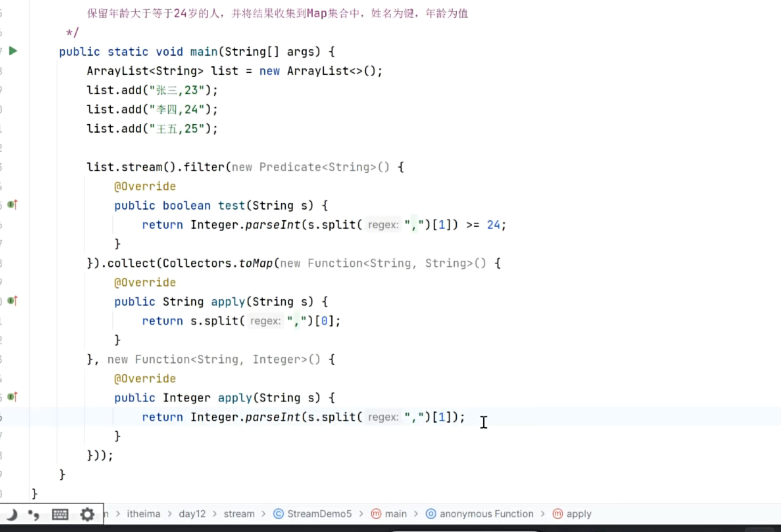
collect(,);
前面写的是key,后面是value
需要进行转化
new Function(a1,a2);
a1为流中的类型
a2为目标类型
需要重写function里面的apply方法,也就是需要将转化出来的的操作进行打印即可
File类
操作系统的文件对象(文件、文件夹)
构造
根据输入的字符串进行操作
File f1=new File("F:\\A.txt");
f1.createNewFile();//创建文件
f1.exists();//存在返回true
File f1=new File("F:\\","A.txt");也可以根据父级路径和子级路径来封装File对象f1=new File(new File(new File("F:\\") ),"A.txt");
相对路径和绝对路径
跟js那边的概念是一样的
绝对:从根目录开始,一点点的找
绝对:相对于当前项目进行查询
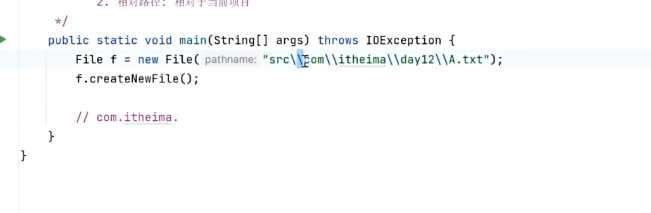
尽管我们创建包的时候习惯写.
但实际上在我们进行查询的时候需要用转移字符\\才可以
isDirectory
判断是否是文件文件夹
isFile!
判断是否是文件
exists
判断是否存在
length()
判断文件的字节大小
文件夹的话,会返回错的
getAbsoluteFile()
System.out.println(f1.getAbsoluteFile());
获得绝对路径
getName
获得文件的名字
lastModified
获得文件的最后的修改时间,返回的是毫秒值

创建和删除
createNewFile
创建一个空的文件
实现创建路径和想要创建的对象,才能通过路径对文件夹进行增删查改的操作
mkdirs
创建多级文件夹
delete
删除
只能删除空的文件夹
删除不走回收站!!
回收不了
public File[] listFiles()
获得当前目录下所有的一级文件对象
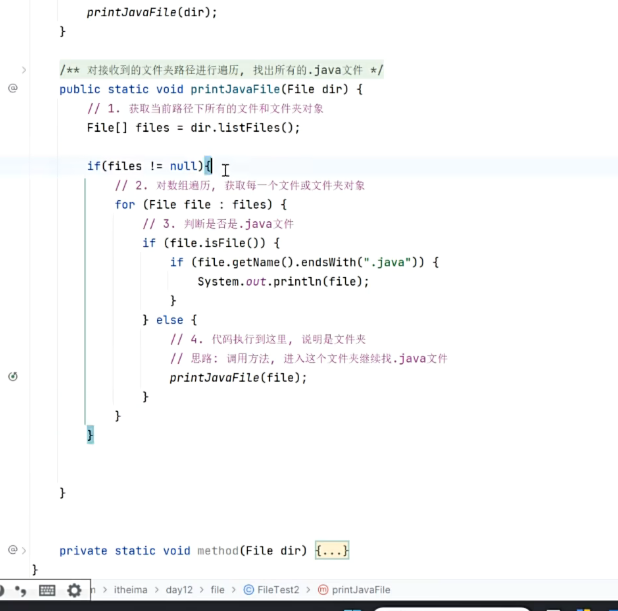
可以利用递归的操作将一个文件夹下面的所有的文件都获取
其实也就是dfs
可能偶尔会返回为null,因为
路径可能会不存在
路径是文件的时候
为空文件的时候,返回的是一个长度为0的数组
!!
当访问的内容或者是文件夹他需要的是需要密码才能够进入的时候们,就会返回为null
至于如何进行的删除,这边不进行
解释了,就是dfs的思想