做爰全过程网站免费的视频seo网址
大语言模型(LLMs)的推理能力是当下研究热点,强化学习在其复杂推理任务微调中广泛应用。这篇论文深入剖析了相关算法,发现简单的拒绝采样基线方法表现惊人,还提出了新算法。快来一探究竟,看看这些发现如何颠覆你对LLMs训练的认知!
论文标题
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
来源
arXiv:2504.11343v1 [cs.LG] 15 Apr 2025
https://arxiv.org/abs/2504.11343
文章核心
研究背景
在大语言模型(LLMs)的后训练阶段,近端策略优化(PPO)是常用方法,但它存在计算开销大、算法复杂等问题。同时,一些简单有效的强化学习(RL)算法逐渐受到关注,如GRPO在训练模型(如DeepSeek - R1)上取得成功,但对其有效性来源了解不足。
研究问题
- RL算法中不同方法处理负样本的方式差异较大,负样本在LLMs训练中的作用和影响尚不明确,例如简单地基于最终答案正确性定义负样本可能过于粗糙。
- GRPO算法细节缺乏充分文档记录,其性能优势是源于自身固有优点,还是与之前研究方法的延续性,有待探究。
- 在基于奖励的LLMs后训练中,算法设计和样本选择的重要性尚不清晰,难以确定哪种因素对模型性能提升更关键。
主要贡献
- 重新评估简单基线方法:发现仅使用正样本训练的简单拒绝采样基线方法RAFT,性能与最先进的RL方法GRPO差距极小,在早期训练阶段收敛更快,挑战了传统认为RL方法因利用负反馈而更强大的观点。
- 剖析GRPO优势来源:通过消融实验揭示,GRPO的主要优势并非奖励归一化,而是丢弃了完全错误响应的提示,为理解和改进基于策略梯度的RL算法提供了关键依据。
- 提出新算法Reinforce - Rej:基于研究成果提出Reinforce - Rej算法,它选择性过滤完全正确和完全错误的样本,提高了KL效率和稳定性,为奖励基策略优化提供了一个简单且有竞争力的基线。
- 明确样本选择重要性:强调在基于奖励的LLMs后训练中,样本选择比算法设计更重要,未来研究应聚焦于更合理地选择和利用样本,而不是盲目依赖负样本。
方法论精要
- 核心算法/框架:研究涉及RAFT、Policy Gradient(包括Reinforce)、GRPO、Iterative DPO、RAFT++等算法。其中,RAFT通过拒绝采样选择正样本微调模型;Policy Gradient旨在优化策略网络以最大化期望奖励;GRPO改进了Policy Gradient,采用优势函数并进行奖励归一化;Iterative DPO基于成对比较数据集优化对比损失;RAFT++则是对RAFT应用重要性采样和裁剪技术的扩展算法。
- 关键参数设计原理:在实验中,使用AdamW优化器,学习率为$ 1×10^{-6} 。每次迭代采样 1024 个提示, R A F T 和 G R P O 每个提示生成 。每次迭代采样1024个提示,RAFT和GRPO每个提示生成 。每次迭代采样1024个提示,RAFT和GRPO每个提示生成 n = 4 $个响应,训练小批量大小设置为512,模型训练时最多生成4096个令牌。这些参数设置基于verl框架推荐,以平衡模型训练的效率和效果。
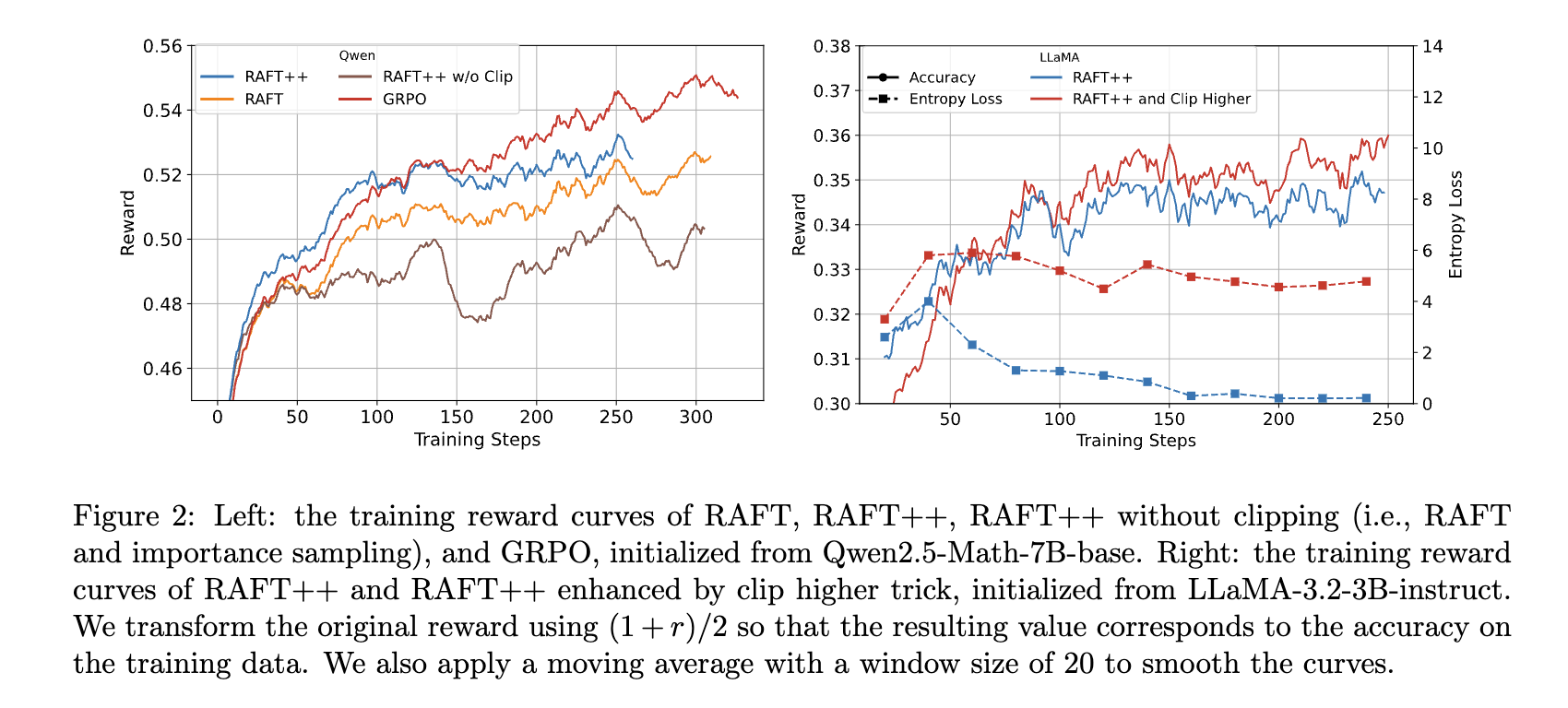
- 创新性技术组合:RAFT++结合了重要性采样和裁剪技术,在采样过程中纠正分布偏移,同时通过裁剪防止更新过大导致训练不稳定,有效提升了模型性能。Reinforce - Rej算法则创新性地同时过滤完全正确和完全错误的样本,避免不良样本对训练的干扰,提高模型训练的稳定性和效率。
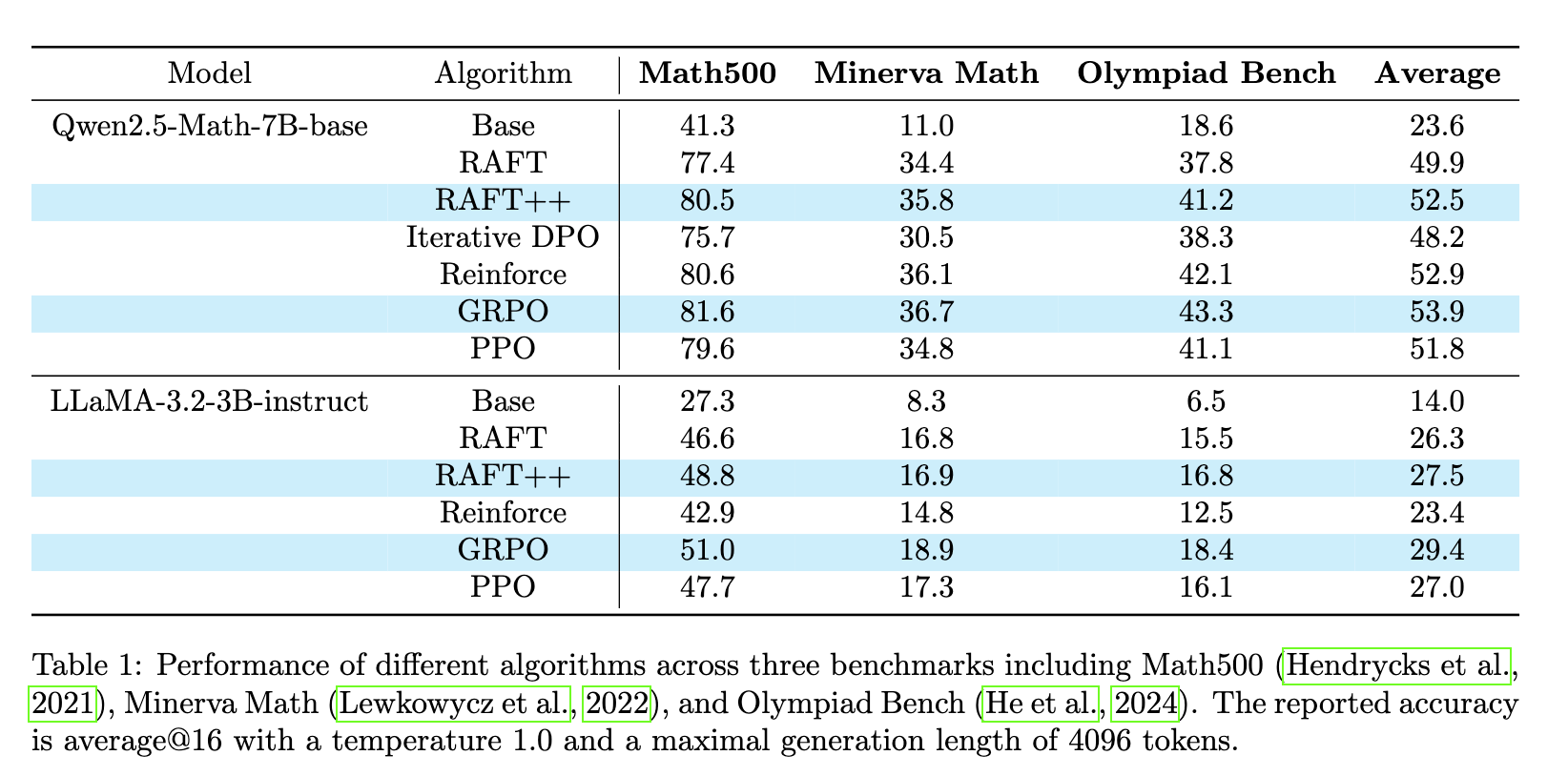
- 实验验证方式:选择数学推理任务进行实验,使用Numina - Math数据集,该数据集包含约860k数学问题及答案,来源广泛。模型选择Qwen2.5 - Math - 7B - base和LLaMA - 3.2 - 3B - instruct。基线方法包括Base模型(未经过特定RL算法微调)、Iterative DPO、Reinforce、GRPO、PPO等。通过对比不同算法在多个基准测试(Math500、Minerva Math、Olympiad Bench)上的平均@16准确率来评估模型性能。
实验洞察
- 性能优势:在Qwen2.5 - Math - 7B - base模型上,RAFT平均准确率达49.9%,超过Iterative DPO(48.2%),接近PPO(51.8%);RAFT++进一步提升至52.5%,与GRPO的53.9%非常接近。在LLaMA - 3.2 - 3B - instruct模型上,RAFT平均准确率为26.3%,RAFT++为27.5%,均优于Reinforce(23.4%)。
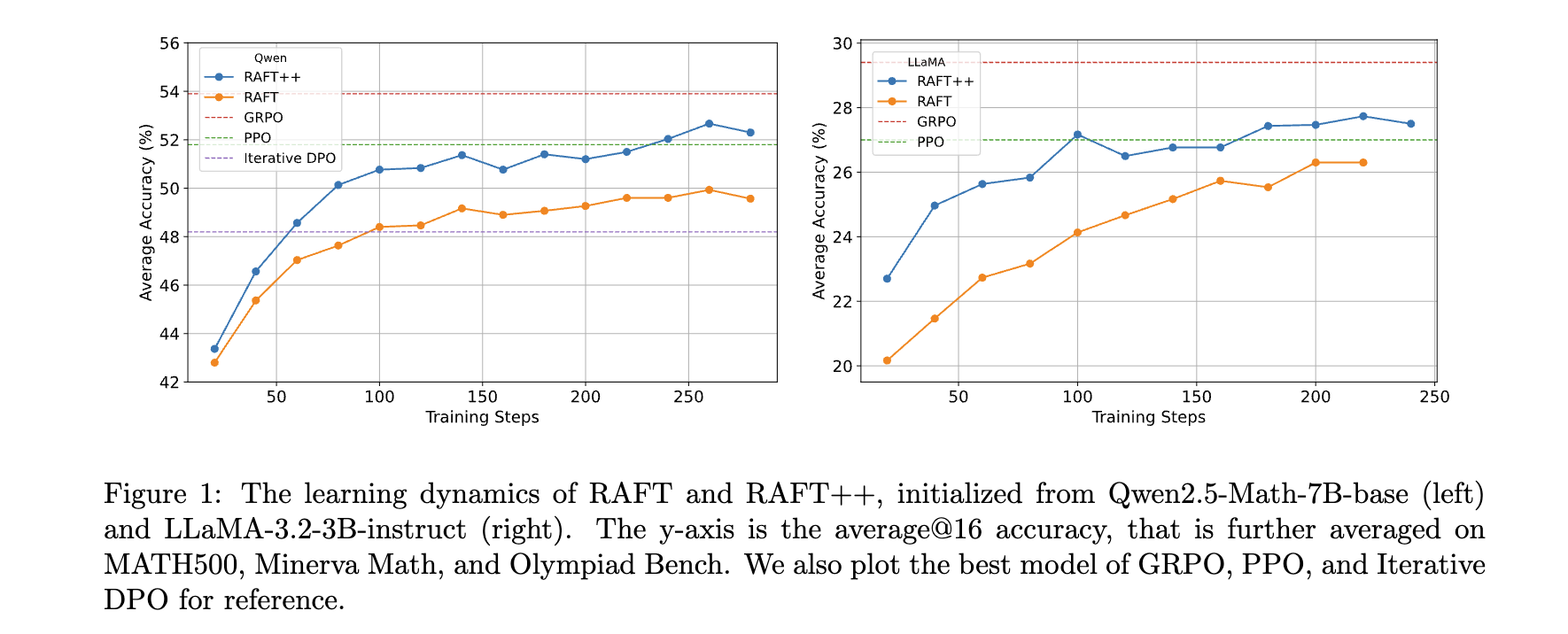
- 效率突破:RAFT++在早期训练阶段收敛速度比GRPO更快,其在训练前期准确率提升迅速。这得益于其仅使用正样本训练,能快速聚焦有效信息,使模型在早期训练中快速学习和提升性能。
- 消融研究:研究发现从RAFT++到GRPO,RAFT++早期收敛快但后期被超越,原因是仅从正样本学习导致策略熵快速下降,限制了探索能力。从Reinforce到GRPO的关键优势在于丢弃完全错误的样本,如“Reinforce + Remove all wrong”变体比Vanilla Reinforce性能提升显著,而奖励归一化对性能提升贡献较小。