无为县做互联网网站永久开源的免费建站系统
1. 位图(BitMap)与布隆过滤器(Bloom Filter)
1.1. 问题背景与解决方案
问题背景
场景:网页爬虫判重
- 搜索引擎的爬虫会不断地解析网页中的链接并继续爬取。
- 一个网页可能在多个页面中出现,容易重复爬取。
- 需要一种高效机制实现 URL 去重。
基本思路
判重基本逻辑
- 判断某个 URL 是否已爬取(存在);
- 如果未爬取,则继续爬取并加入“已爬取集合”。
所需操作
- 插入 URL
- 查询 URL
- 操作高效(时间复杂度低)
- 内存消耗尽可能低(处理上亿数据)
数据结构比较
| 数据结构 | 查询效率 | 插入效率 | 空间消耗 | 是否准确 |
| 散列表(哈希表) | 高(O(1)) | 高(O(1)) | 高(>100GB) | 准确 |
| 位图(BitMap) | 高(O(1)) | 高(O(1)) | 较低(位级别) | 准确(范围限制) |
| 布隆过滤器 | 高(O(K)) | 高(O(K)) | 低(约1.2GB) | 有误判(可接受) |
1.2. 位图(BitMap)
位图定义:
- 使用 位(bit)数组表示某个值是否存在。
特点:
- 高效、节省内存(如 1 亿范围只需约 12MB 内存)。
- 适用于整数范围 不太大的场景。
class BitMap:def __init__(self, nbits):"""初始化位图数组。nbits: 需要支持的最大位数。"""self.nbits = nbits# 每个元素为16位,相当于Java中的char,这里使用整数模拟self.bytes = [0] * ((nbits // 16) + 1)def set(self, k):"""将第 k 位设置为 1,表示该数字已出现。"""if k >= self.nbits or k < 0:raise ValueError("Index out of range")byte_index = k // 16bit_index = k % 16self.bytes[byte_index] |= (1 << bit_index)def get(self, k):"""获取第 k 位的状态,判断该数字是否出现。返回 True 表示已出现。"""if k >= self.nbits or k < 0:raise ValueError("Index out of range")byte_index = k // 16bit_index = k % 16return (self.bytes[byte_index] & (1 << bit_index)) != 01.3. 布隆过滤器(Bloom Filter)
背景
- 位图不能应对太大范围(如 1~10亿),需进一步优化。
- 布隆过滤器 = 多个哈希函数 + 位图
工作机制
- 使用
K个哈希函数对元素x进行哈希,得到下标X1 ~ XK; - 把位图的
X1 ~ XK位置置为1; - 查询时也用
K个哈希函数,判断对应位是否都为1;
-
- 是:可能存在(有误判);
- 否:一定不存在。
误判特性
- 误判只会出现在判断“存在”时;
- 可通过合理选择:
-
- 哈希函数个数
K - 位图大小
m - 数据规模
n
- 哈希函数个数
- 控制误判率达到可接受范围。
1.4. 应用实例
爬虫URL去重实战应用
使用布隆过滤器优化爬虫判重
- 假设需去重的 URL 数量为 10 亿
- 采用布隆过滤器(位图大小 100 亿位 ≈ 1.2GB)
- 多个哈希函数进行哈希定位
- 内存节省显著(相比于 100GB 级的哈希表)
效率分析
- 散列表:内存密集,频繁字符串比对、指针访问(慢);
- 布隆过滤器:CPU密集,批量哈希计算(快);
-
- 减少缓存miss;
- 减少长字符串比较。
应用拓展场景
- 搜索引擎网页爬虫判重
- 大规模用户访问去重(如每日UV)
- 黑名单检测、垃圾邮件过滤
- CDN 去重缓存
- 数据库缓存穿透保护等
数据结构应用对比:
| 对比维度 | 散列表 | 位图 | 布隆过滤器 |
| 精度 | 准确 | 准确(范围小) | 有小概率误判 |
| 内存占用 | 高 | 中 | 低 |
| 插入查询 | O(1) | O(1) | O(K)(哈希函数个数) |
| 应用 | 通用 | 范围小 | 大规模、可容忍误判场景 |
2. B+树:MySQL数据库索引
索引要解决什么问题?
功能性需求:
- 快速根据某个值查询:
SELECT * FROM user WHERE id = 1234 - 快速进行区间查找:
SELECT * FROM user WHERE id > 1234 AND id < 2345
性能需求:
- 查找效率要高(时间)
- 占用内存尽量少(空间)
尝试已有数据结构的适用性
| 数据结构 | 查找复杂度 | 是否支持区间查找 | 适合做索引? |
| 散列表 | O(1) | ❌ | 否 |
| 平衡二叉树 | O(logn) | ✅(中序遍历) | 有限制 |
| 跳表 | O(logn) | ✅ | 可能 |
- 结论:跳表接近满足需求,但数据库索引实际使用的是 B+ 树。
从二叉树演进到 B+ 树的过程
- 改造思路:二叉树节点只做索引,叶子节点串成有序链表以支持区间遍历
- 问题:数据量大时,索引树过高,导致磁盘 I/O 次数增多,查找变慢
- 优化:用多叉树(m 叉树)降低树的高度,减少磁盘 I/O 次数
-
- 例:对一亿条数据,二叉树高度可能高达 26,而 100 叉树高度仅为 3
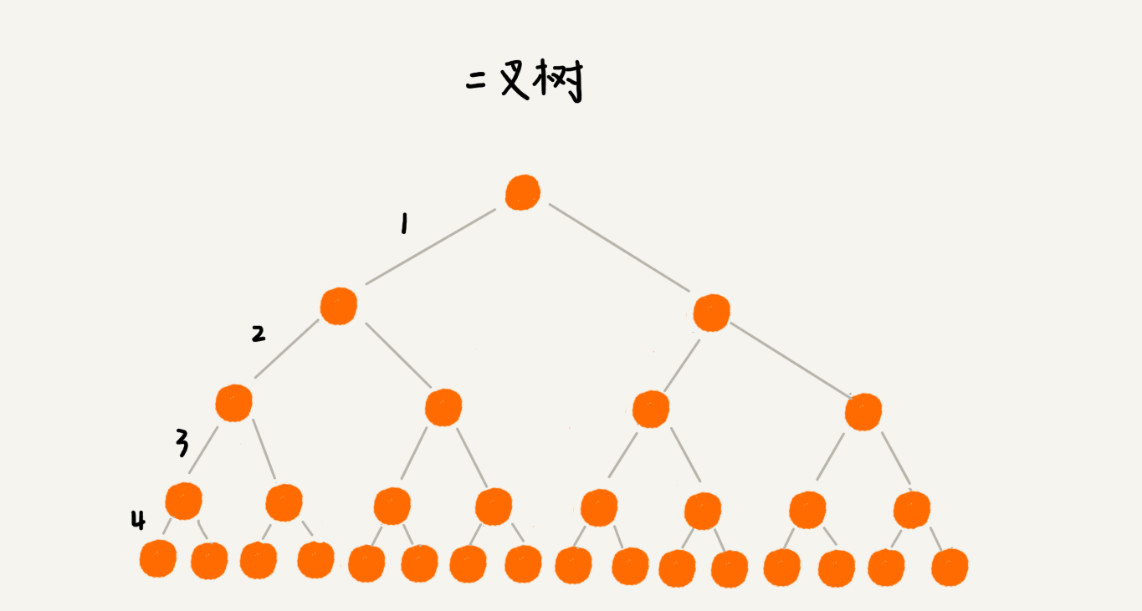
2.1. B+ 树的结构设计
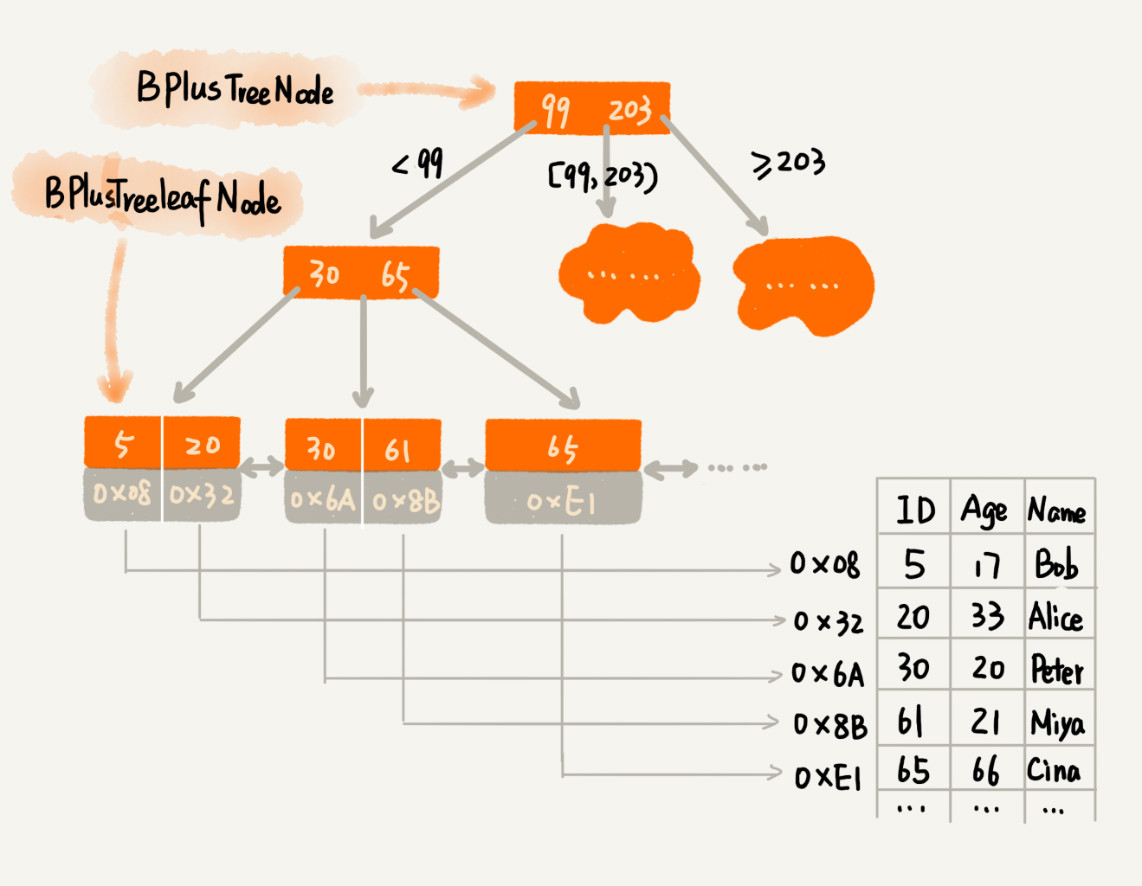
pytho实现B+树的结构设计:
class BPlusTreeNode:"""B+ 树中的非叶子节点定义"""def __init__(self, m):self.m = m # m 叉树,最大子节点个数self.keywords = [] # 键值列表 (最多 m-1 个)self.children = [] # 子节点指针列表 (最多 m 个)def is_leaf(self):return Falseclass BPlusTreeLeafNode:"""B+ 树中的叶子节点定义"""def __init__(self, k):self.k = k # 每个叶子节点最多存储 k 个键值对self.keywords = [] # 键值列表self.data_addresses = [] # 数据地址(或引用)列表self.prev = None # 前驱叶子节点指针self.next = None # 后继叶子节点指针def is_leaf(self):return True页大小与分叉因子的关系:
- 操作系统按页(如 4KB)读取数据
- 设计 m时要尽量让一个节点大小 = 一个页大小
不管是内存中的数据,还是磁盘中的数据,操作系统都是按页(一页大小通常是 4KB,这个值可以通过 getconfig PAGE_SIZE 命令查看)来读取的,一次会读一页的数据。如果要读取的数据量超过一页的大小,就会触发多次 IO 操作。所以,我们在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小。读取一个节点,只需要一次磁盘 IO 操作。
2.2. 索引影响写入性能
对于一个 B+ 树来说,m 值是根据页的大小事先计算好的,也就是说,每个节点最多只能有 m 个子节点。在往数据库中写入数据的过程中,这样就有可能使索引中某些节点的子节点个数超过 m,这个节点的大小超过了一个页的大小,读取这样一个节点,就会导致多次磁盘 IO 操作。
写入操作(插入/删除)可能触发以下行为:
- 插入时节点分裂(子节点超过 m)
- 删除时节点合并(子节点少于 m/2)
这些过程都需要修改索引树结构,可能层层递归、影响父节点甚至根节点,所以 写入比读取慢。
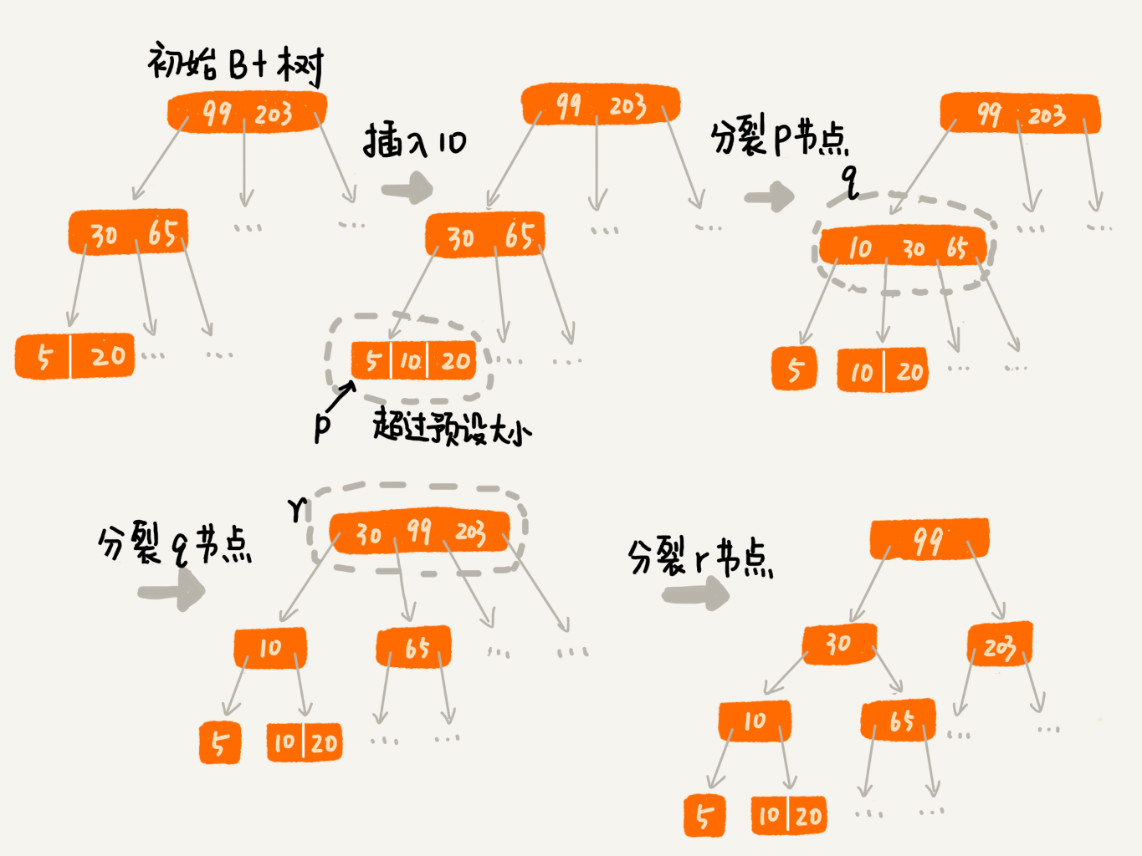
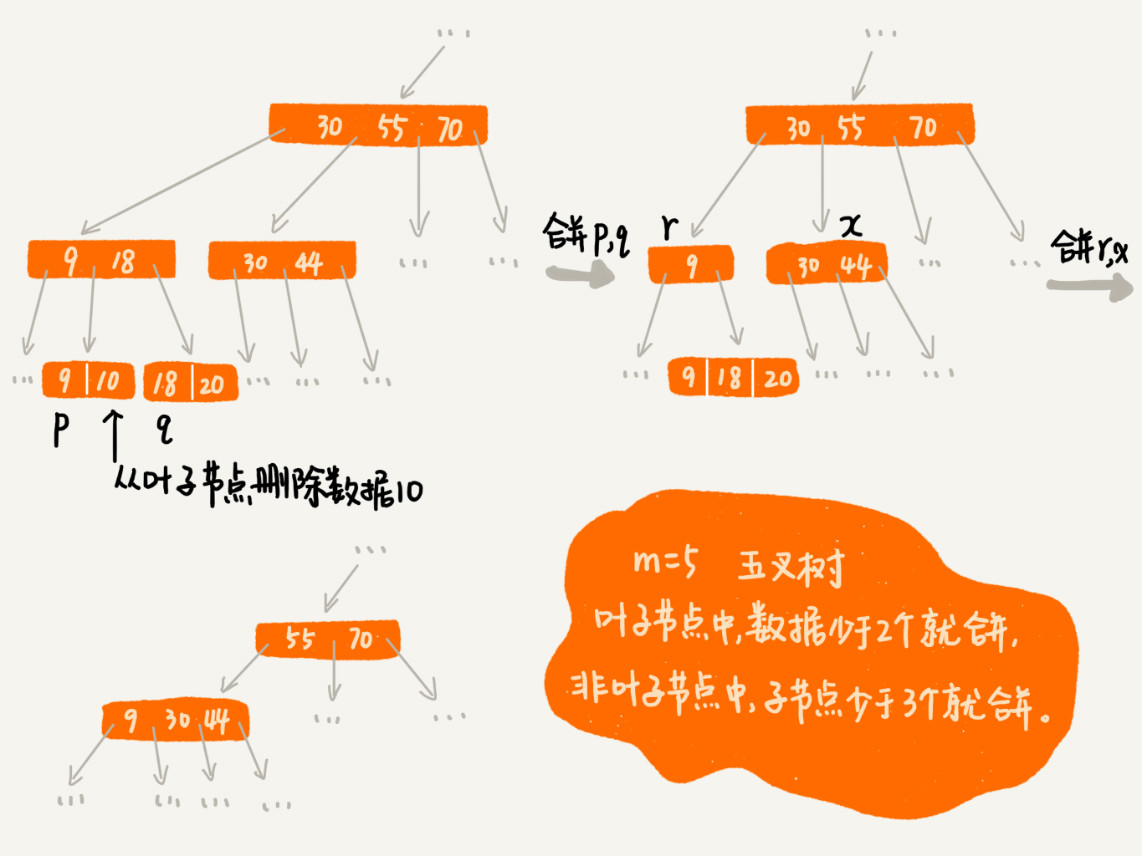
2.3. 对比与总结
B+ 树 vs 跳表:相似与差异
- 都支持区间查找
- B+ 树是磁盘友好结构,设计重点是降低磁盘 I/O 次数
- 跳表更偏内存优化,适合缓存、高速数据结构
- B+ 树历史更久(1972 年),跳表更现代(1989 年)
B+ 树的特点总结:
| 特性 | 描述 |
| 多路搜索树 | 每个节点最多有 m 个子节点,最少 m/2(除根节点) |
| 只在叶子节点存储数据 | 非叶节点仅作索引 |
| 所有叶子节点构成双向的有序链表 | 支持高效的区间查找 |
| 适配磁盘读写(页设计) | 减少磁盘 I/O 次数 |
| 插入/删除可能引发结构变动 | 分裂/合并机制维护树的平衡 |
B 树 / B-树 与 B+ 树的区别简析:
- B 树(B-Tree):数据存储在所有节点上(非叶节点也存数据)
- B+ 树:数据仅存在叶子节点,非叶节点仅做索引,更适合数据库和文件系统使用