找个做游戏的视频网站百度竞价排名展示方式
背景
这里的索引说的是关系数据库(MSSQL)中的索引。
本篇不是纯技术性的内容,只是聊一次性能调优的经历,包含到一些粗浅的实现和验证手段,所以,大神忽略即可。
额…对了,笔者对数据库的优化手段了解有限,文中若有原则性或者概念性错误的地方,欢迎大家指正。
提起索引,相信有部分同学跟我的感觉一样,熟悉又陌生。熟悉是知道索引的概念,也知道它的利弊,但实际工作中并没有太多利用过索引。
我个人比较喜欢所谓的CodeFirst的编码方式,对关系数据库的操作,大部分都是通过orm或者一些自动化脚本来完成,直接去操作数据库的话,只有改造老项目,或者需要去库里查询一些数据的时候才会借助管理工具去直接操作数据库。所以,对索引的实际操作经历非常少。正巧,最近公司的一个常态化运行项目就遇到了检索的性能瓶颈,而现阶段又不能去修改业务代码或者引入一些中间件来缓解,所以想到了是不是可以从索引入手,尝试做一些性能优化。
结果,你猜怎么着,性能提升不多,也就10倍左右吧🚀
定位问题
发现性能瓶颈
首先,我发现这个问题的时候,在业务系统上做一次复杂的数据检索最多竟然需要1-2秒左右才能返回,在遇到网络不稳定的情况,返回时长还会更久,总之体验非常不好。

数据库性能查询
由于账号权限的问题,我没办法使用DTA(Database Engine Tuning Advisor)来具体的定位问题,所以使用了更直接的工具–执行计划(Excution Plan)来辅助。
具体步骤如下
- 首先,在本地环境下,确定此接口生成的查询语句;
- 将Sql直接放到数据库中执行,并开启执行计划和实时查询统计信息
- 获取SSMS给出的优化建议。
按此操作执行后,我们能看到当前的查询,究竟落到数据库中的链条有多长,也就是这个查询复杂度有多高,同时也能获得一个优化建议。

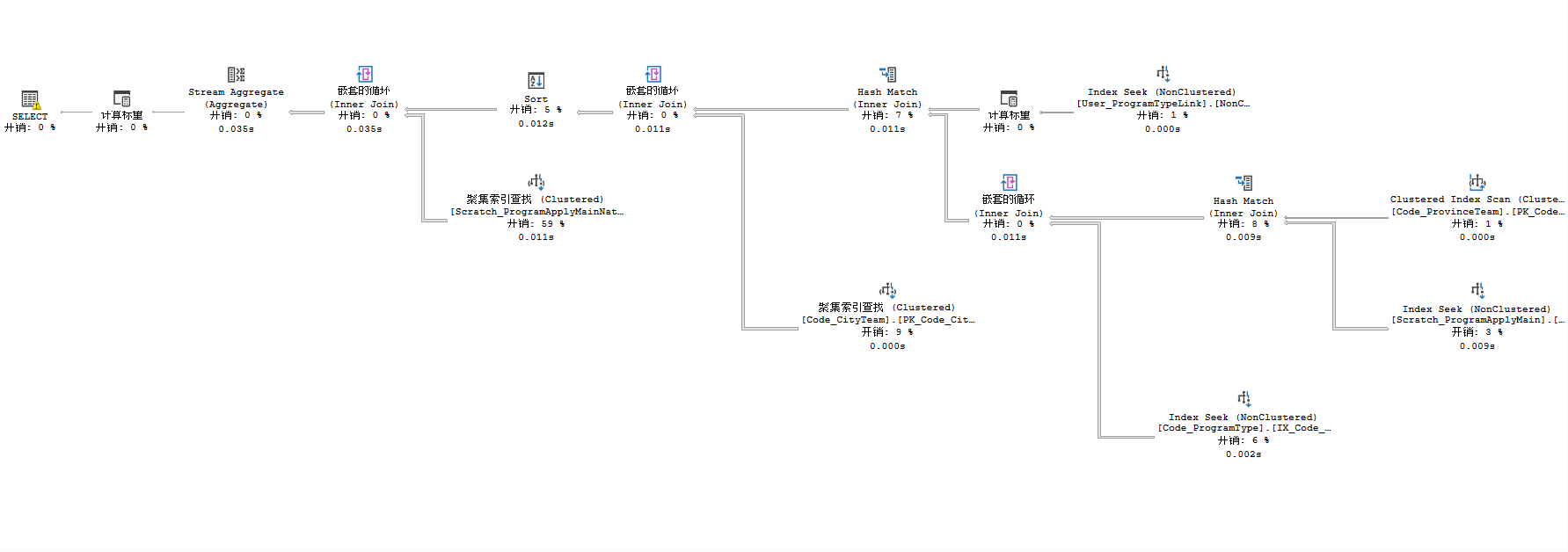
这里,我们先不管复杂度的问题,因为当前情况下,修改业务代码肯定是不可能的,所以目前只关注索引。
验证问题
编写测试接口
这里,我把这个常用的接口改造了一下,去掉了验证,鉴权等环节,也把一些额外的属性关掉了,确保每次请求都是直接打到服务端,且查询数据库
[AllowAnonymous]
//[ResponseCache(Duration = 10, VaryByQueryKeys = new string[] { "whereJsonStr", "adminId", "pageIndex", "pageSize", "rd" })]
public IActionResult GetApplyStatusListForTest(string whereJsonStr, int adminId, int pageIndex = 1, int pageSize = 10, int rd = 0)
{// 复杂查询业务// ... 代码省略
}
编写测试脚本
这里还是使用Grafana的K6工具进行测试。
关于K6的内容,大家可以参见其官方文档👉:https://grafana.com/docs/k6/latest/
笔者之前也写过一篇类似的博客👉:https://juejin.cn/post/7442535460361109554
import http from 'k6/http';
import { check, sleep } from 'k6';export const options = {vus: 10,duration: '1m',thresholds: {checks: ['rate>0.95'], // 至少 95% 的请求必须成功http_req_duration: ['p(95)<500'] // 95% 的请求响应时间小于 500 毫秒}
}const urls = [`https://localhost:5001/matchai/getApplyStatusListForTest?pageindex=${Math.floor(Math.random() * 10) + 1}&pagesize=10&whereJsonStr=...`,`https://localhost:5001/matchai/getApplyStatusListForTest?pageindex=${Math.floor(Math.random() * 10) + 1}&pagesize=10&whereJsonStr=...`,`https://localhost:5001/matchai/getApplyStatusListForTest?pageindex=${Math.floor(Math.random() * 10) + 1}&pagesize=10&whereJsonStr=...`,`https://localhost:5001/matchai/getApplyStatusListForTest?pageindex=${Math.floor(Math.random() * 10) + 1}&pagesize=10&whereJsonStr=...`
]
export default function () {const url = urls[Math.floor(Math.random() * urls.length)];console.log(`-------------------start----------------------`);console.log(`Request URL: ${url}`);console.log(`--------------------end----------------------`);let params = {headers: {'Content-Type': 'application/json'}};let res = http.get(url, params);// 解析响应体let response = JSON.parse(res.body);// 定义检查点let checks = {'status code is 200': (r) => r.status === 200,'API code is 1': (r) => response.code === 1};// 执行检查点check(res, checks);// 记录非成功的响应if (response.code !== 1) {console.log(`Error: code=${response.code}, msg=${response.msg}, data=${JSON.stringify(response.data)}`);}console.log(`Response Time: ${res.timings.duration}ms`);const sleepTime = Math.floor(Math.random() * 51) + 50; // 随机生成50到100毫秒sleep(sleepTime / 1000); // 将毫秒转换为秒}
简单说明下这段测试脚本的含义
- 导入必要模块,这里用到http,check,sleep
- 配置压测参数,模拟10个并发,持续1分钟
- 设定性能阈值,95%的请求必须成功,且响应时间小于500毫秒
- 定义URL列表,随机抽取,模拟多种条件下的请求行为
- 主函数执行,即10个uv随机发起请求,并输出观测日志
- 定义响应检查行为,时间,并记录失败响应
- 模拟50-100毫秒的操作间隔
控制变量
首先,在没有索引和有索引的前提下,跑一遍脚本
K6_WEB_DASHBOARD=true K6_WEB_DASHBOARD_EXPORT=html-report.html k6 run simulatescript1.js
通过上述命令,会得到一个比较完整的报表,这里我们只看Performance Overview部分,可以
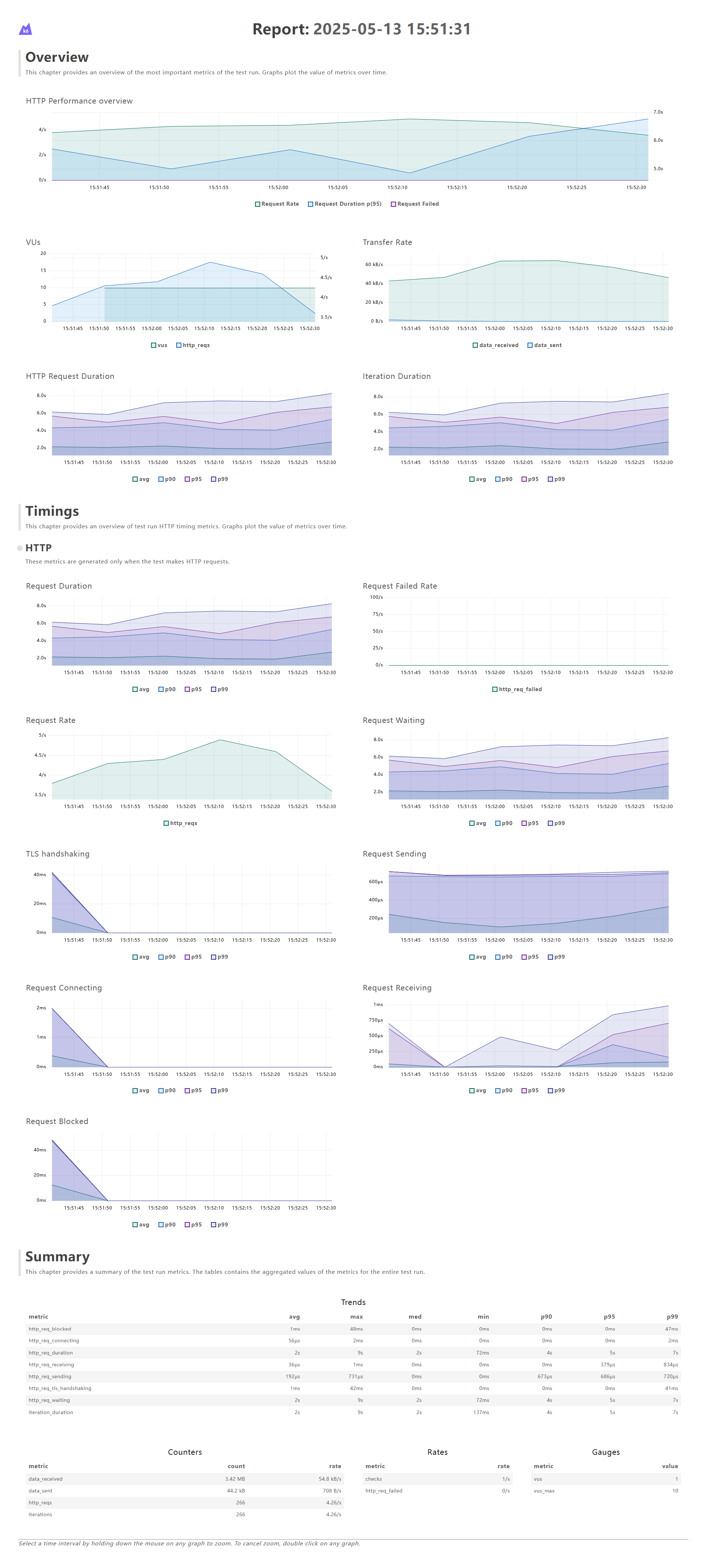
- 无索引

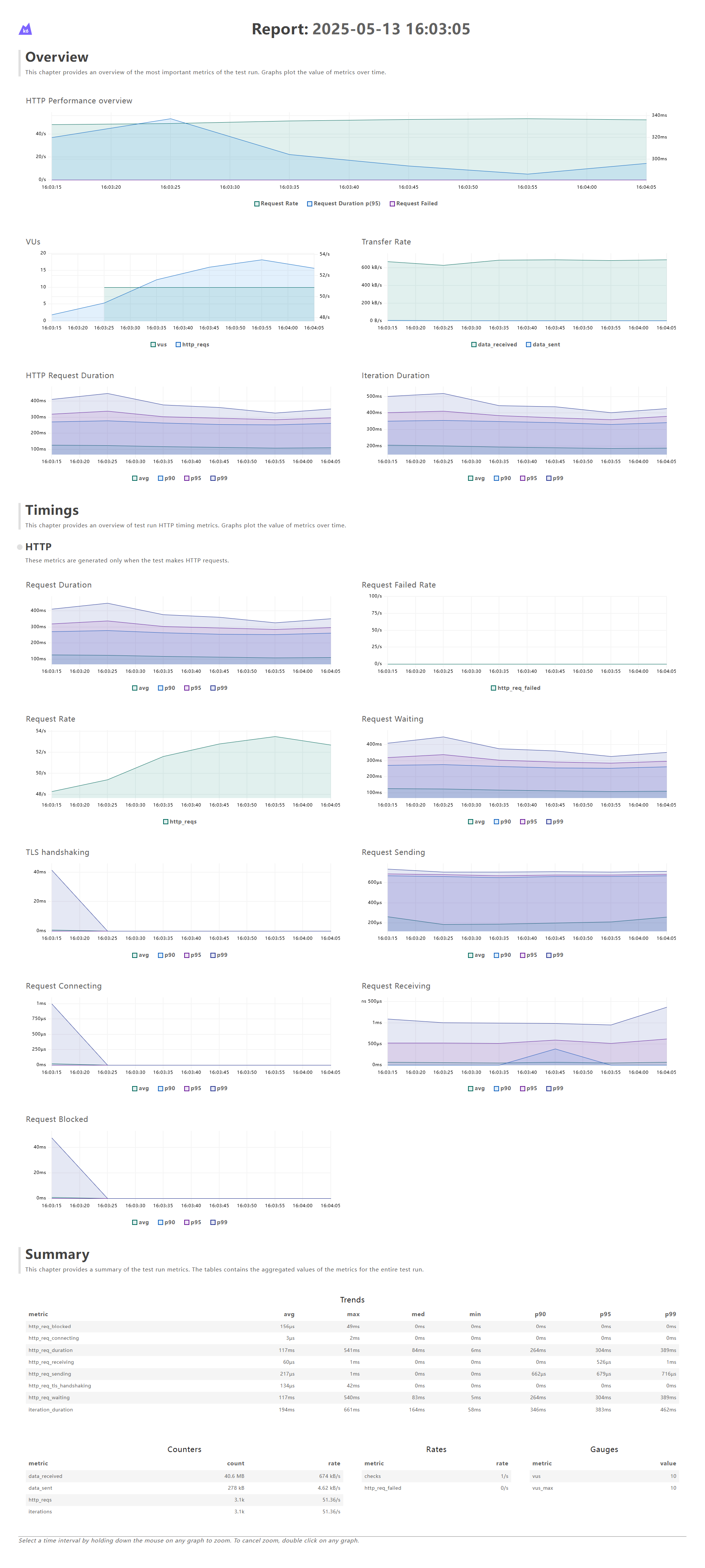
- 有索引
对比可以看到,得到的测试性能提升了10倍,这期间,除了索引的建立,其余条件均一致。
由此,可以判定,根据SSMS执行计划给出的建议,建立索引之后,性能的确可以得到明显的改善。
这里的索引,就是根据SSMS执行计划给出的建议,完成的,比如
CREATE NONCLUSTERED INDEX [IX_索引名称] ON [dbo].[表名称]
({待索引的字段}
)
INCLUDE({包含的字段}) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
需要说明的是,我这里真的就只关注了索引,实际上,执行计划还会给出很多检索执行过程的详细信息,大家可以导出成xml或者直接在ssms窗口查看

其他可行手段
客户端缓存
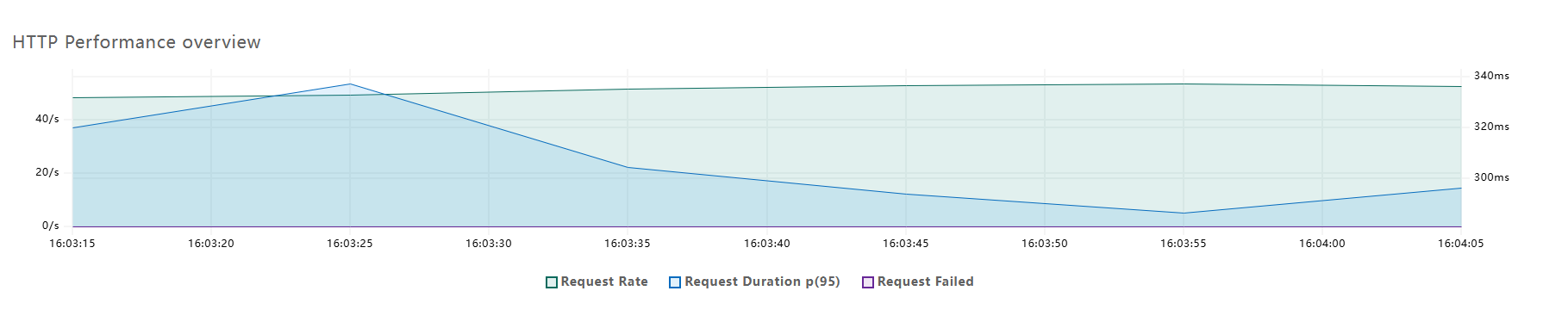
确定了增加索引,可以显著提高检索性能后,我还引入了客户端缓存,设置一个合理的过期时间,这样,再到正式站点测试后,得到的结果就是这样了👇

虽然现在的结果也并不优秀,但相比之前秒级的响应,已经能明显感觉到丝滑了许多。
索引维护
我们都知道,索引建立之后,是需要定期维护的,否则会产生过多碎片,造成性能下降。在SSMS中,可以使用Sql Agent来辅助完成。
笔者这里是建立了一个存储过程,通过系统定期调用执行。
USE [数据库]
GO
/****** Object: StoredProcedure [dbo].[IndexMaintenanceProcedure] Script Date: 2025-05-13 17:36:58 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GOALTER PROCEDURE [dbo].[IndexMaintenanceProcedure]
AS
BEGINSET NOCOUNT ON;DECLARE @schemaName NVARCHAR(128);DECLARE @tableName NVARCHAR(128);DECLARE @indexName NVARCHAR(128);DECLARE @avg_fragmentation_in_percent FLOAT;DECLARE @startTime DATETIME;DECLARE @endTime DATETIME;DECLARE @errorMessage NVARCHAR(MAX);DECLARE @actionTaken NVARCHAR(50);DECLARE @sql NVARCHAR(MAX);-- 定义游标,获取所有碎片化超过5%的索引DECLARE curIndexFrag CURSOR FORSELECT s.name AS schema_name,t.name AS table_name,i.name AS index_name,ips.avg_fragmentation_in_percentFROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED') ipsINNER JOIN sys.indexes i ON ips.object_id = i.object_id AND ips.index_id = i.index_idINNER JOIN sys.tables t ON i.object_id = t.object_idINNER JOIN sys.schemas s ON t.schema_id = s.schema_idWHERE i.name IS NOT NULL -- 排除堆(heap)AND t.is_ms_shipped = 0 -- 排除系统表AND ips.avg_fragmentation_in_percent > 5; -- 设置阈值OPEN curIndexFrag;FETCH NEXT FROM curIndexFrag INTO @schemaName, @tableName, @indexName, @avg_fragmentation_in_percent;WHILE @@FETCH_STATUS = 0BEGINSET @startTime = GETDATE();SET @errorMessage = NULL;BEGIN TRYIF @avg_fragmentation_in_percent >= 30BEGIN-- 碎片率高,重建索引SET @actionTaken = 'Rebuild';SET @sql = N'ALTER INDEX ' + QUOTENAME(@indexName) + N' ON ' + QUOTENAME(@schemaName) + N'.' + QUOTENAME(@tableName) + N' REBUILD;';ENDELSE IF @avg_fragmentation_in_percent >= 5 AND @avg_fragmentation_in_percent < 30BEGIN-- 中度碎片,重组索引SET @actionTaken = 'Reorganize';SET @sql = N'ALTER INDEX ' + QUOTENAME(@indexName) + N' ON ' + QUOTENAME(@schemaName) + N'.' + QUOTENAME(@tableName) + N' REORGANIZE;';ENDPRINT '执行操作: ' + @sql;EXEC sp_executesql @sql;END TRYBEGIN CATCHSET @errorMessage = ERROR_MESSAGE();PRINT '错误发生: ' + @errorMessage;END CATCHSET @endTime = GETDATE();-- 记录日志INSERT INTO dbo.IndexMaintenanceLog (SchemaName, TableName, IndexName, Fragmentation, ActionTaken, StartTime, EndTime, ErrorMessage)VALUES (@schemaName, @tableName, @indexName, @avg_fragmentation_in_percent, @actionTaken, @startTime, @endTime, @errorMessage);FETCH NEXT FROM curIndexFrag INTO @schemaName, @tableName, @indexName, @avg_fragmentation_in_percent;ENDSELECT count(1) as cnt FROM dbo.IndexMaintenanceLog WHERE EndTime >= @startTime;CLOSE curIndexFrag;DEALLOCATE curIndexFrag;
END至此,本次优化工作基本完成。
一点注意
对索引熟悉的同学,应该都知道,索引有很多类型,包括聚集索引,非聚集索引,唯一索引等等。索引的主要作用,还是提升读性能,尤其在OLAP的场景,而不是和OLTP场景。
索引的建立也不是越多越好,尤其是聚集索引,是会明显影响写入性能的。本篇提到的优化过程,建立的都是非聚集索引,对写性能的影响有限。
其他的,我就不多说了,大家一搜就能得到很多标准答案,我这里再推荐一本书《数据库系统内幕》。笔者也是在有了这次优化经历之后,发现自己在很多基础性的知识还是有欠缺,分享给大伙共勉。
最后,说起性能调优,本篇聊到的内容只是冰山一角,但我们也要注意不要陷入过度优化的陷阱,所以还是看开发人员的综合能力,开发习惯和开发经验,最终找到一条适合自己项目的系统优化之路。总之呢,系统做好了,过度调整肯定不对,完全或者几乎不调整更不对,这也是对团队能力和软件质量的考验。当然了,如果你做的都是那种小项目,就几千上万条数据量,甚至是那种单机应用,一次性应用,那确实不太需要关注这方面,把功能做好,别出低级错误就可以了。
好了,这篇就聊到这里。
*附
最后附上k6测试的完整报表