用什么建网站口碑营销是什么
点一下关注吧!!!非常感谢!!持续更新!!!
大模型篇章已经开始!
- 目前已经更新到了第 22 篇:大语言模型 22 - MCP 自动操作 Figma+Cursor 自动设计原型
Java篇开始了!
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新…)
- Spark MLib (正在更新…)
集成学习
不指望单个弱模型“包打天下”,而是构造一簇互补的基学习器并让它们投票/加权,用“群体智慧”提升泛化能力、稳定性和鲁棒性。
基本定义
集成学习通过建立几个模型来解决单一预测问题,它的工作原理是生成多个分类器/模型,各自独立的学习和做出预测,这些预测最后结合成组合预测,因为优于任何一个单分类的做出预测。
集成学习分类
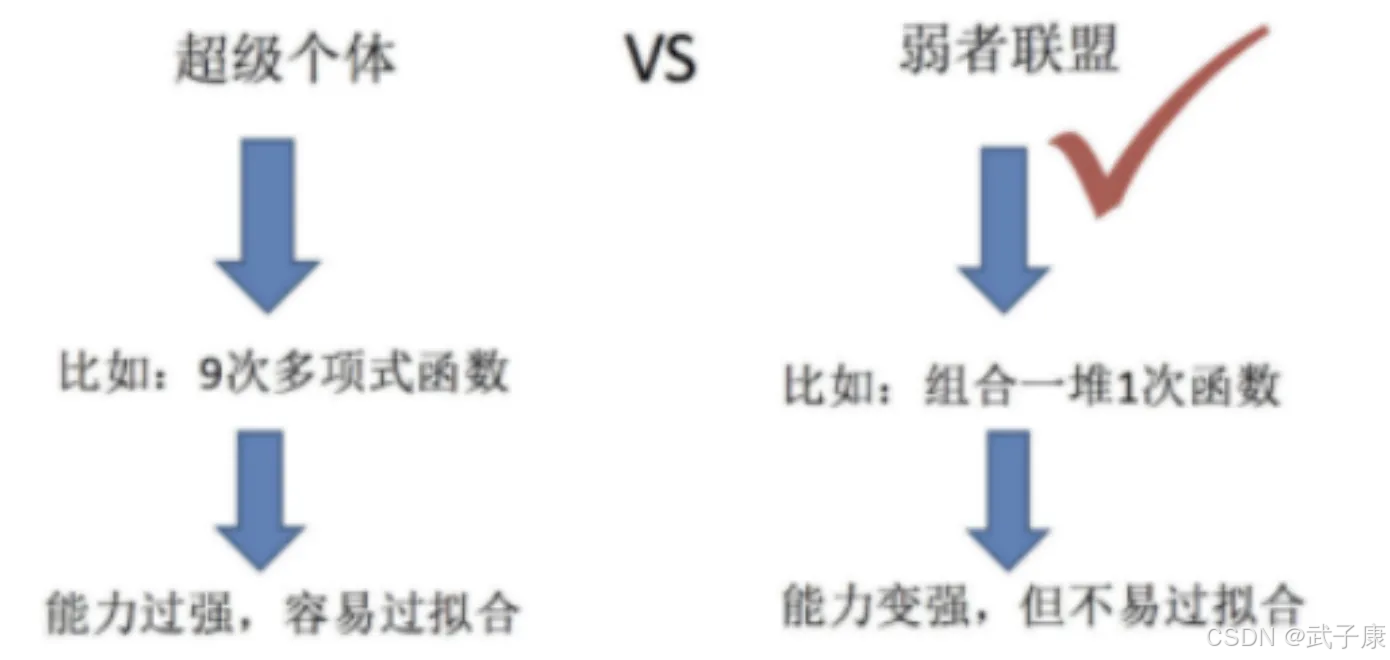
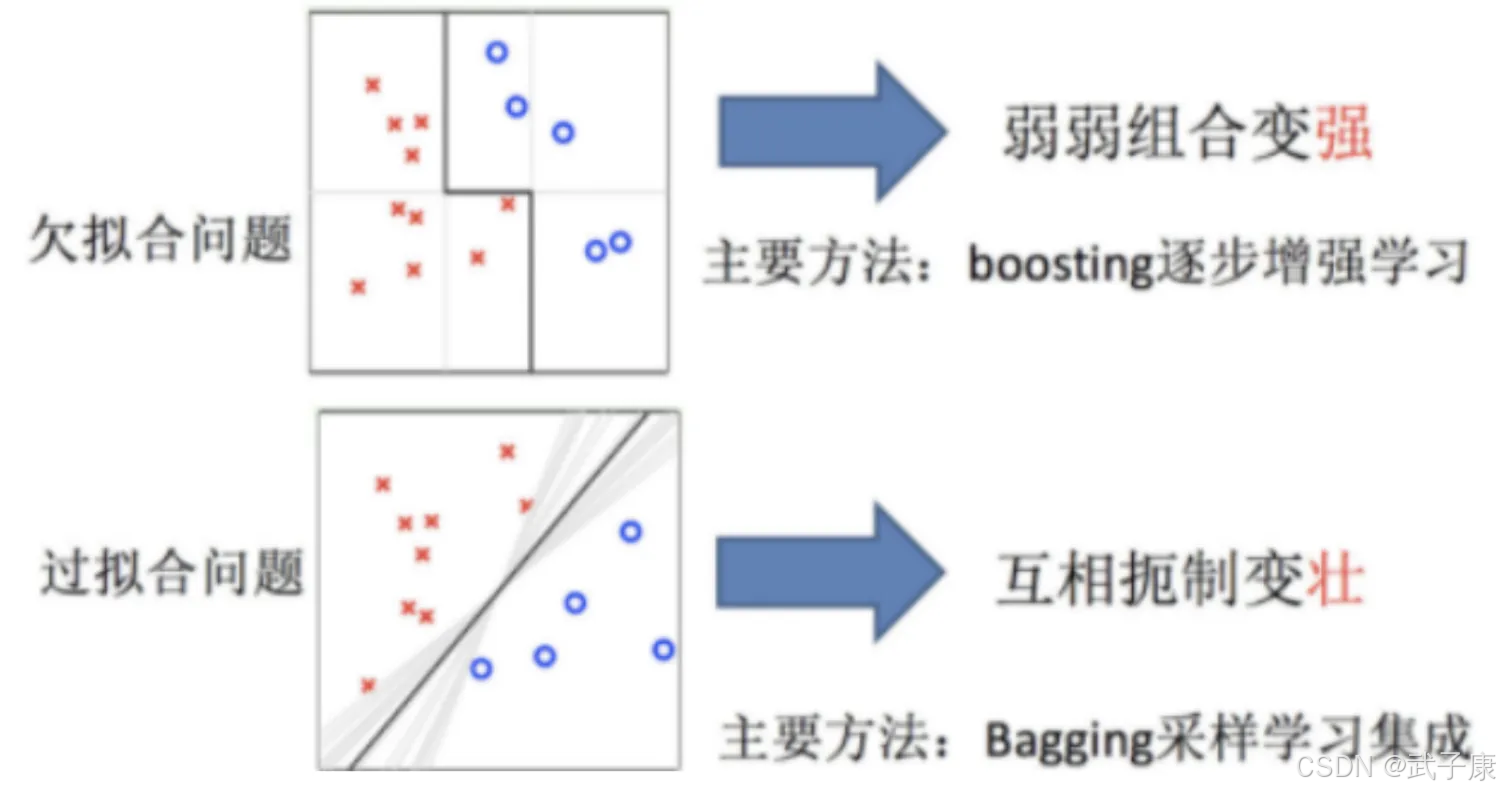
● 任务一:如何优化训练数据 - 主要用于解决欠拟合问题
● 任务二:如何提升泛化性能 - 主要用于解决过拟合问题
只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的。
Bagging
集成原理
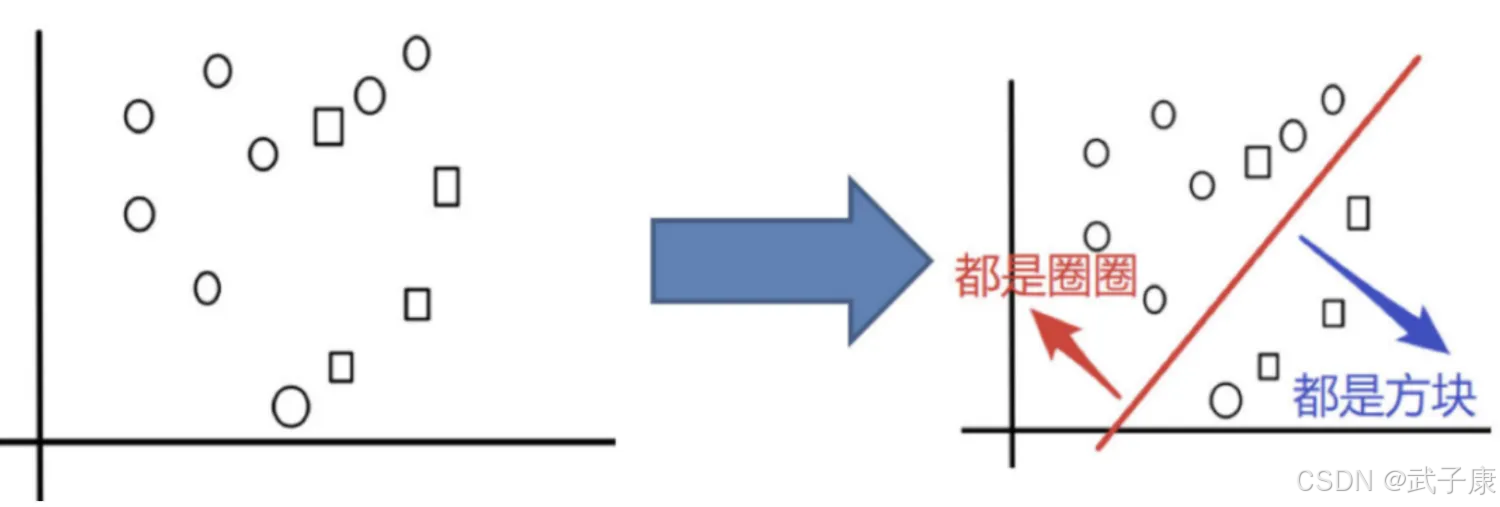
目标
把下面的圈和方块进行分类
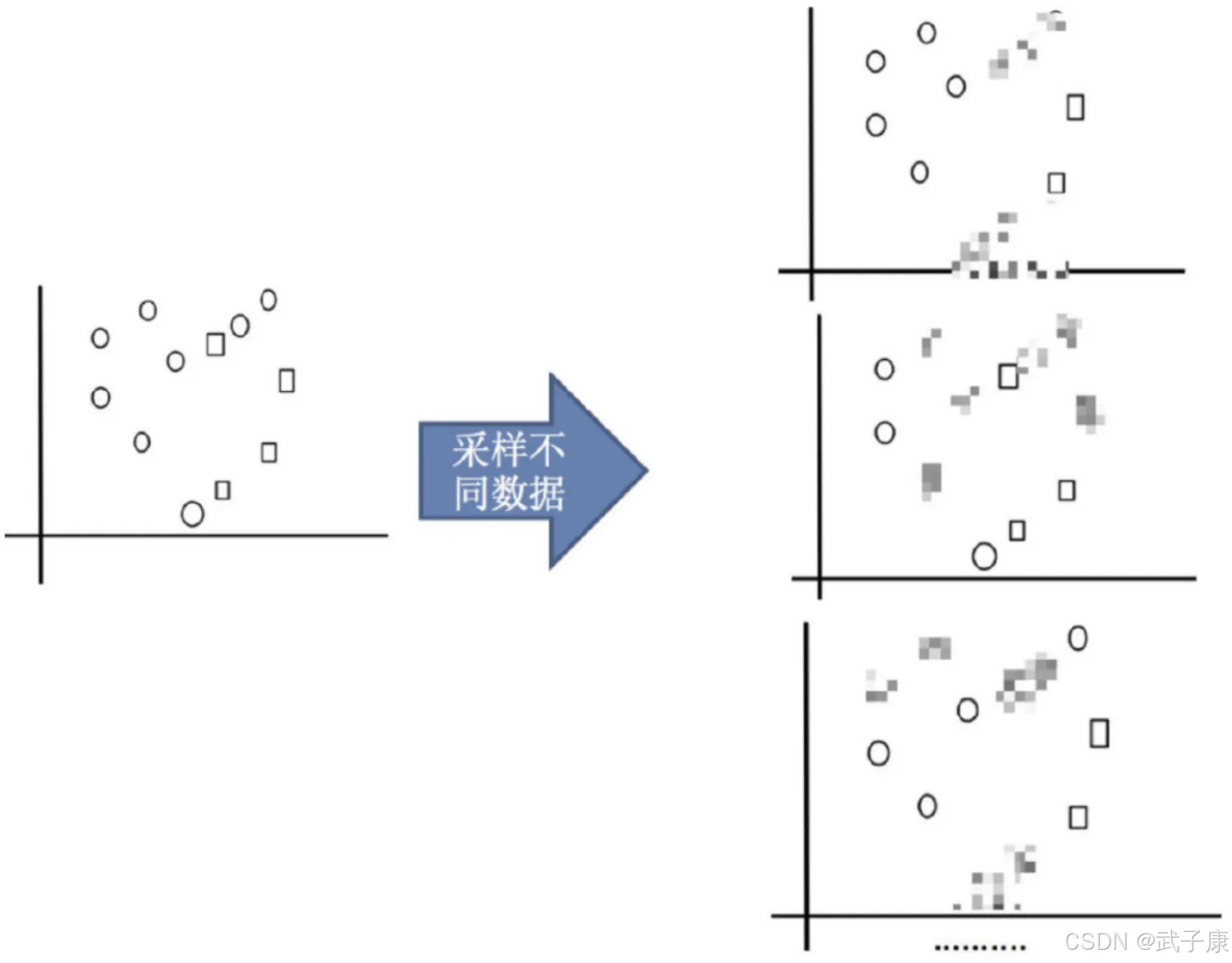
采集不同的数据集
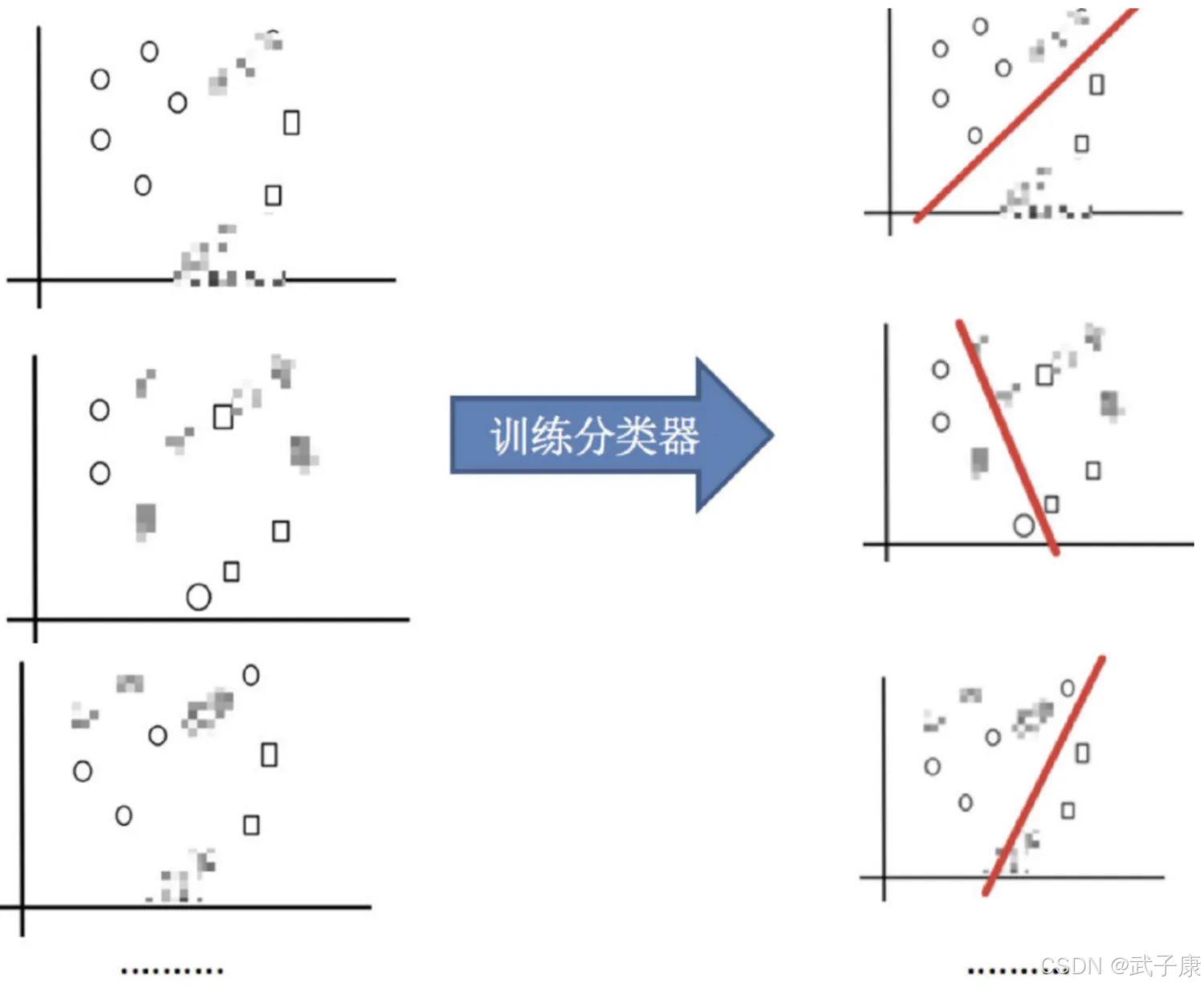
训练分类器
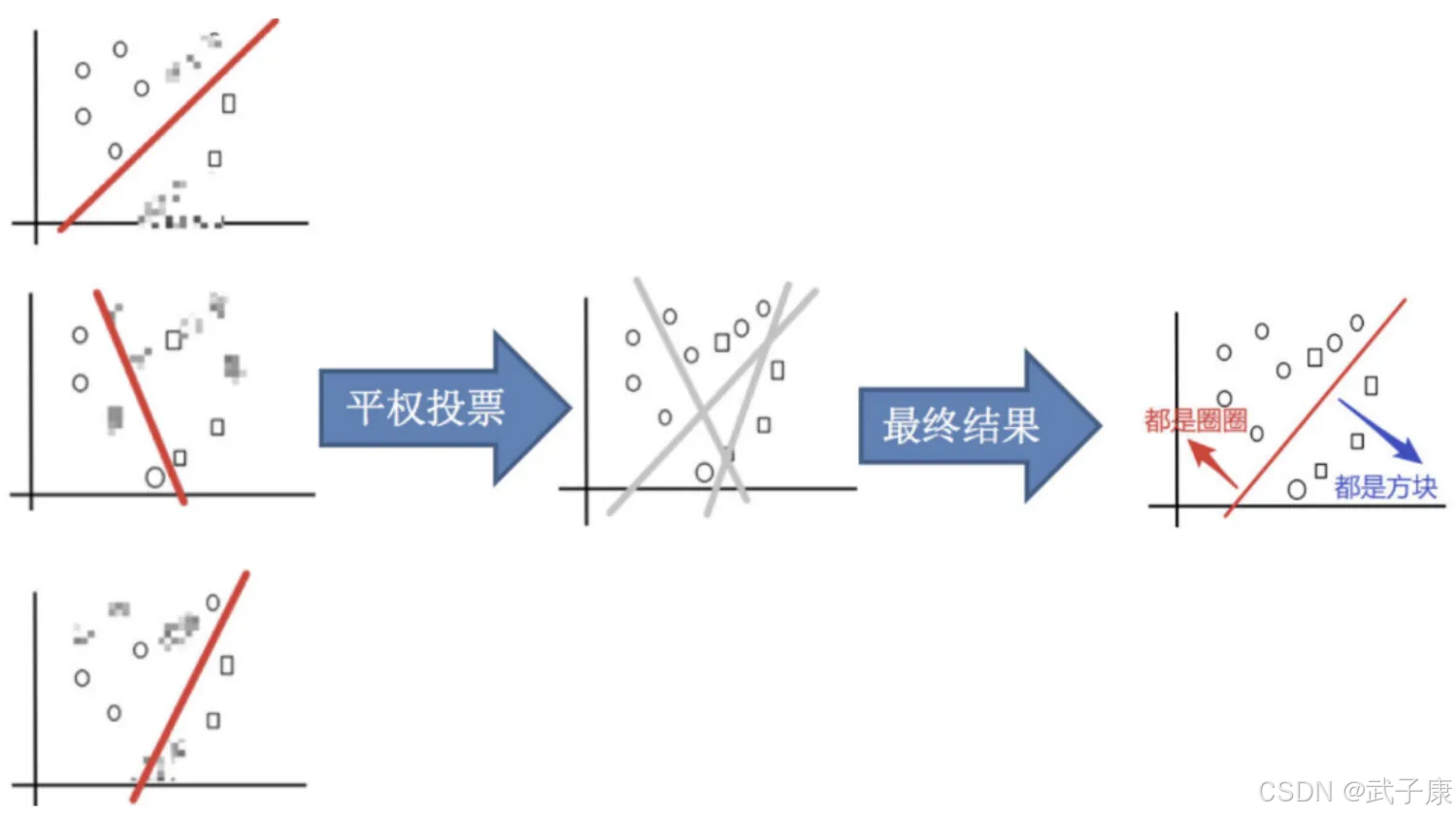
平权投票
获取最终结果
随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由所有树输出的类别的众数而定。
随机森林 = Bagging + 决策树
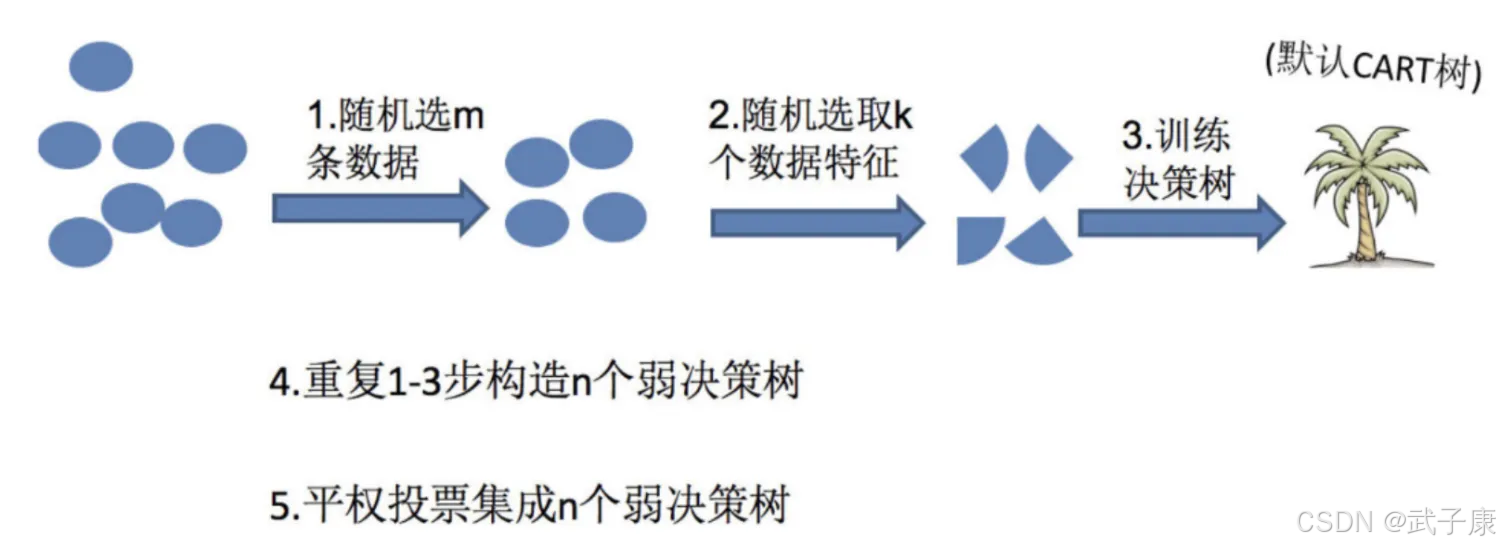
例如,如果你训练了5个树,其中有4个树的结果是True,1个树的结果是False,那么最终投票的结果就是True,随机森林构造过程中的关键步骤(M表示特征数目):
● 一次随机选出部分样本,有放回的抽样,重复N次(有可能出现重复的样本)
● 随机去选出 m 个特征,m << M,建立决策树
Boosting
基本概念
随着学习的积累从弱到强,简而言之:每新加入一个弱学习器,整体能力就会得到提升

代表算法:Adaboost、GBDT、XGBoost、LightGBM
Spark MLlib 的 GBT 相当于 “纯原生 Java/Scala 实现的 GBDT”,功能和速度距现代竞赛级框架(XGBoost / LightGBM / CatBoost)仍有差距。工业界常用以下两条路线把先进算法接进 Spark Pipeline:
- XGBoost4J‑Spark:将每个 XGBoost worker 嵌入 Spark executor,天然支持 GPU / CPU 分布式;API 兼容 ML Pipeline,可与 VectorAssembler、ParamGridBuilder 协同工作。
- LightGBM‑Spark(microsoft/synapseml):基于 LightGBM 的梯度直方、Leaf‑wise growth,训练速度较快,支持类别特征原生处理与分布式训练。
使用方式大体一致: 把 XGBoostClassifier 或 LightGBMRegressor 替换到 Pipeline 里,并确保 依赖 JAR 与 native lib 在所有 executor 可见。常见踩坑点:
- 内存分配:XGBoost 需要 executor 拥有足够的 off‑heap;通过 spark.executor.memoryOverhead 和 spark.executor.cores 调整。
- 数据格式:必须把特征向量转成 Dense 或 Sparse Vector; 并避免 StringIndexer 将类别特征过度 one‑hot,使维度爆炸。
- GPU 调度:需要 spark.task.resource.gpu.amount=1 并在 YARN/K8s 上配置 spark.executor.resource.gpu.amount。
实现过程
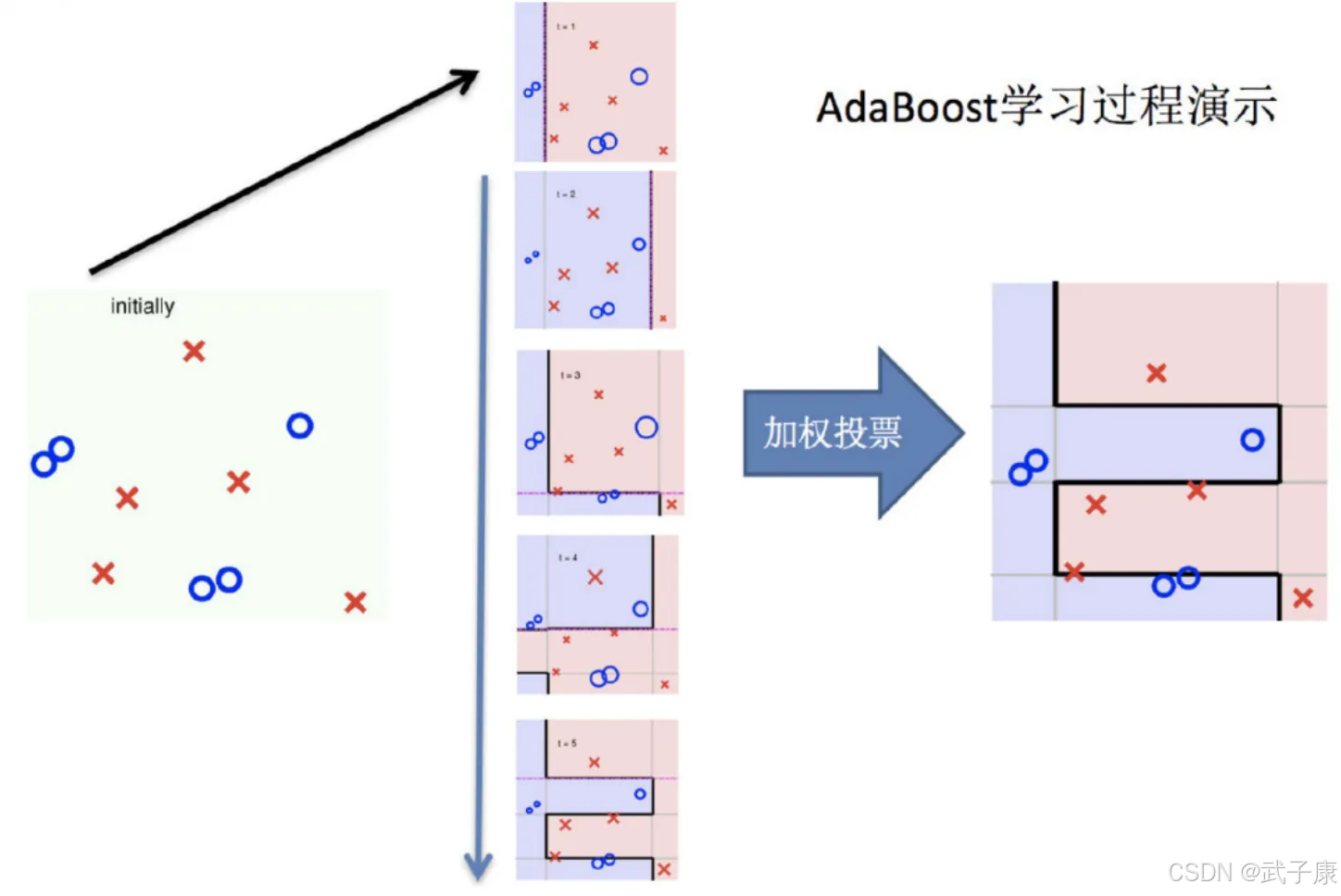
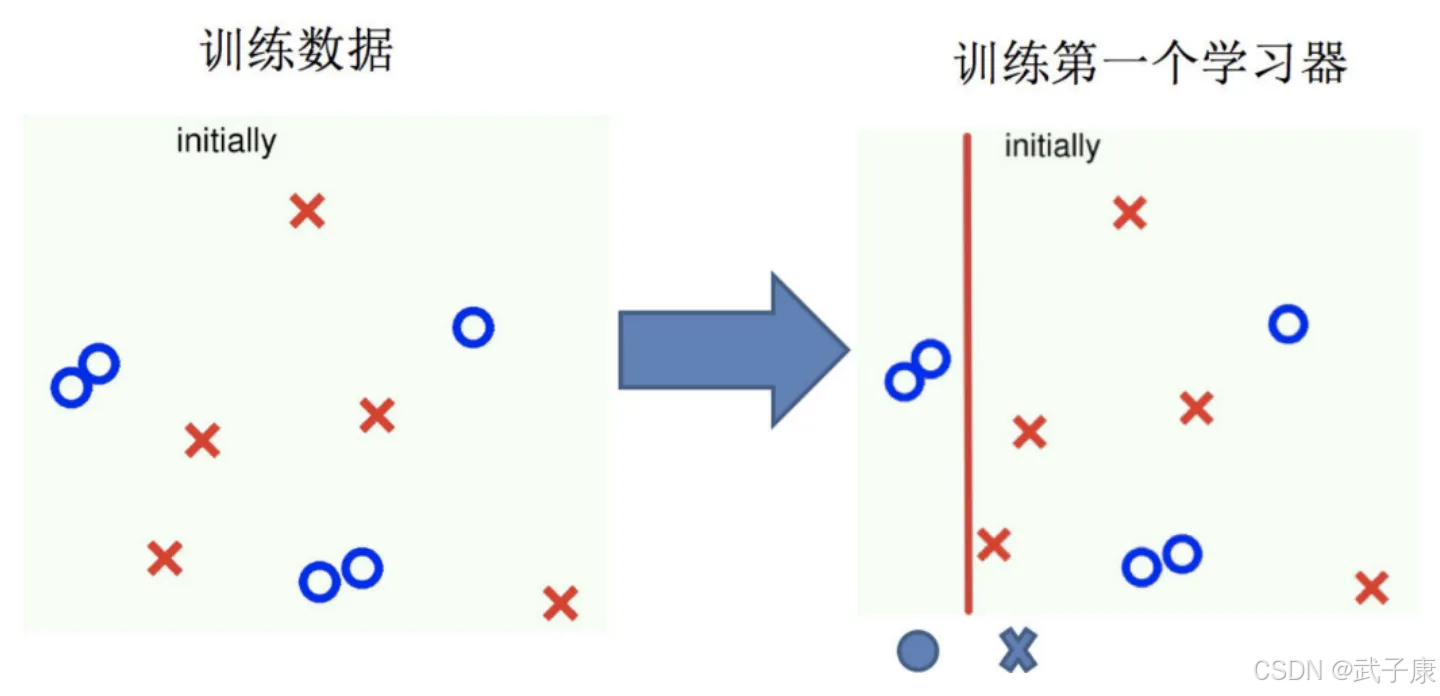
训练第一个学习器
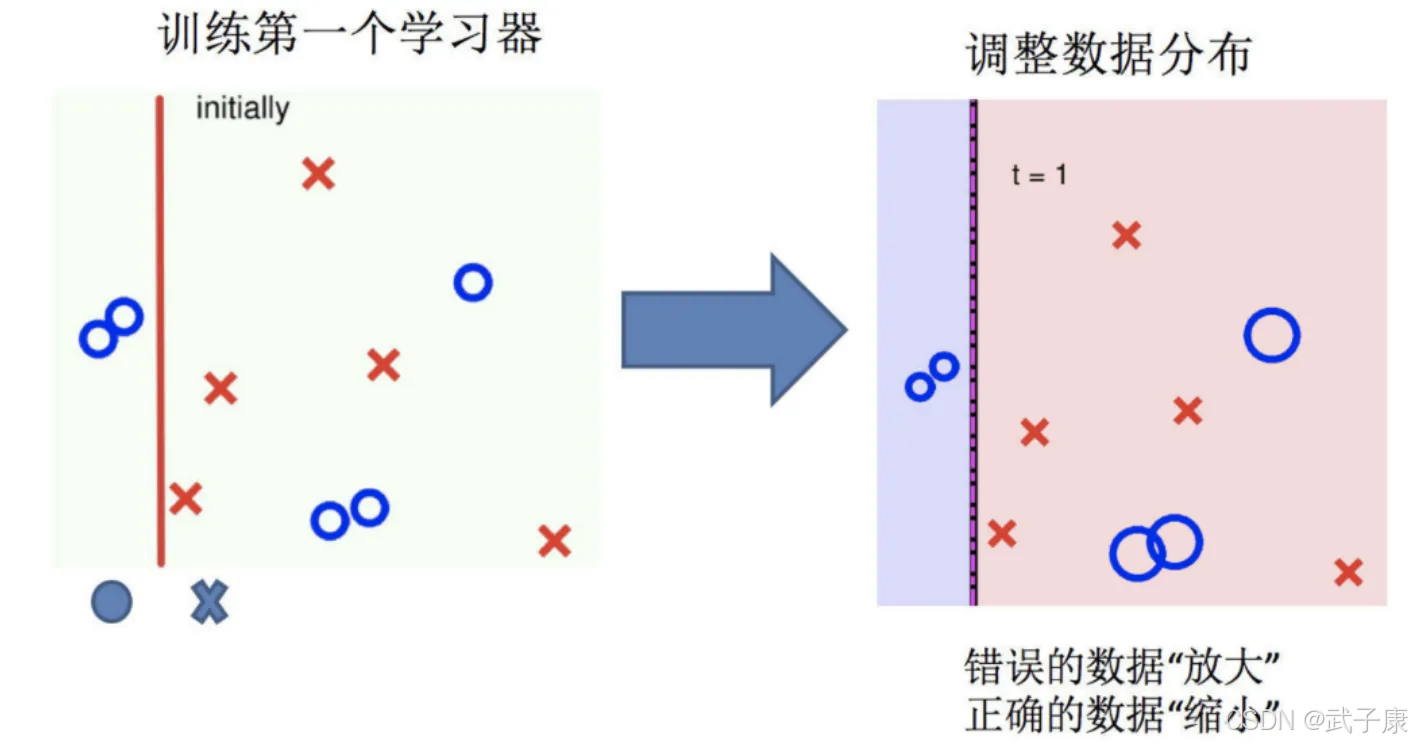
调整数据分布
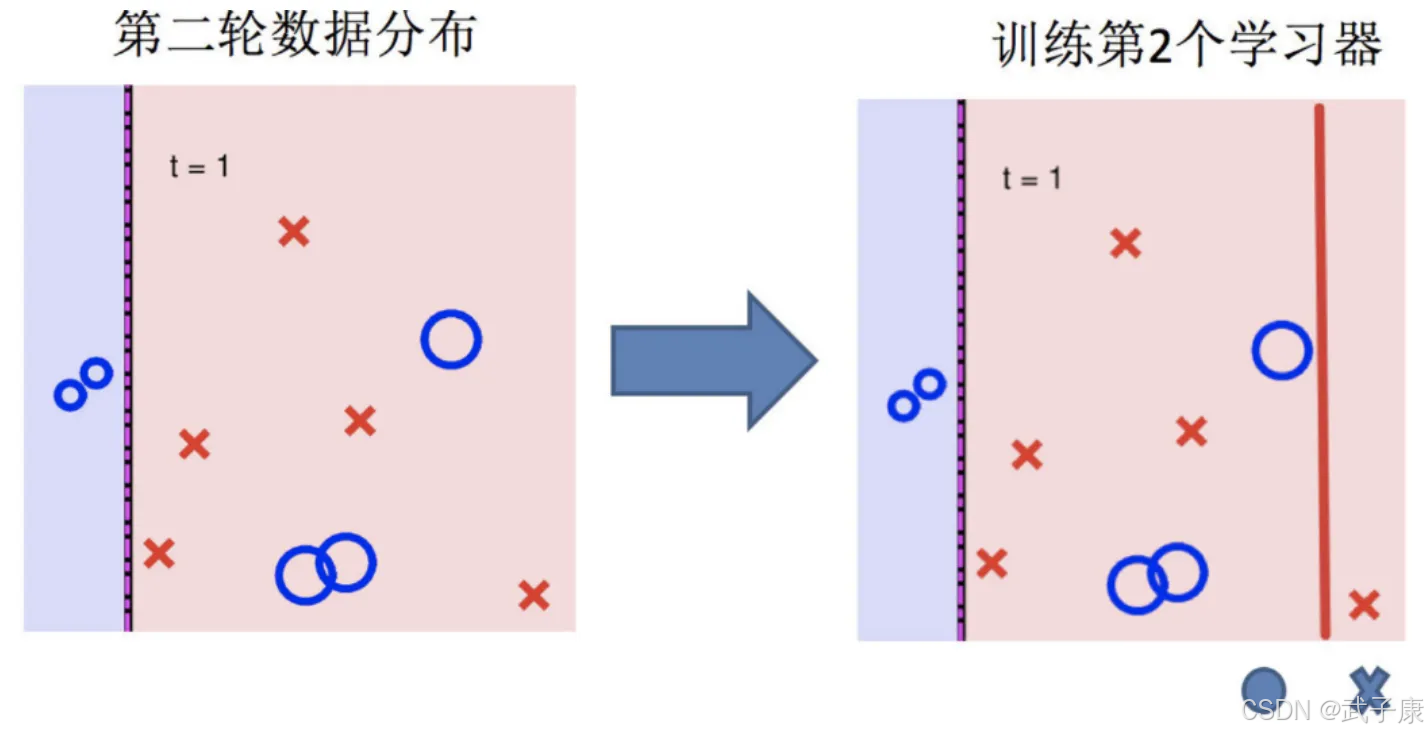
训练第二个学习器
再次调整数据分布
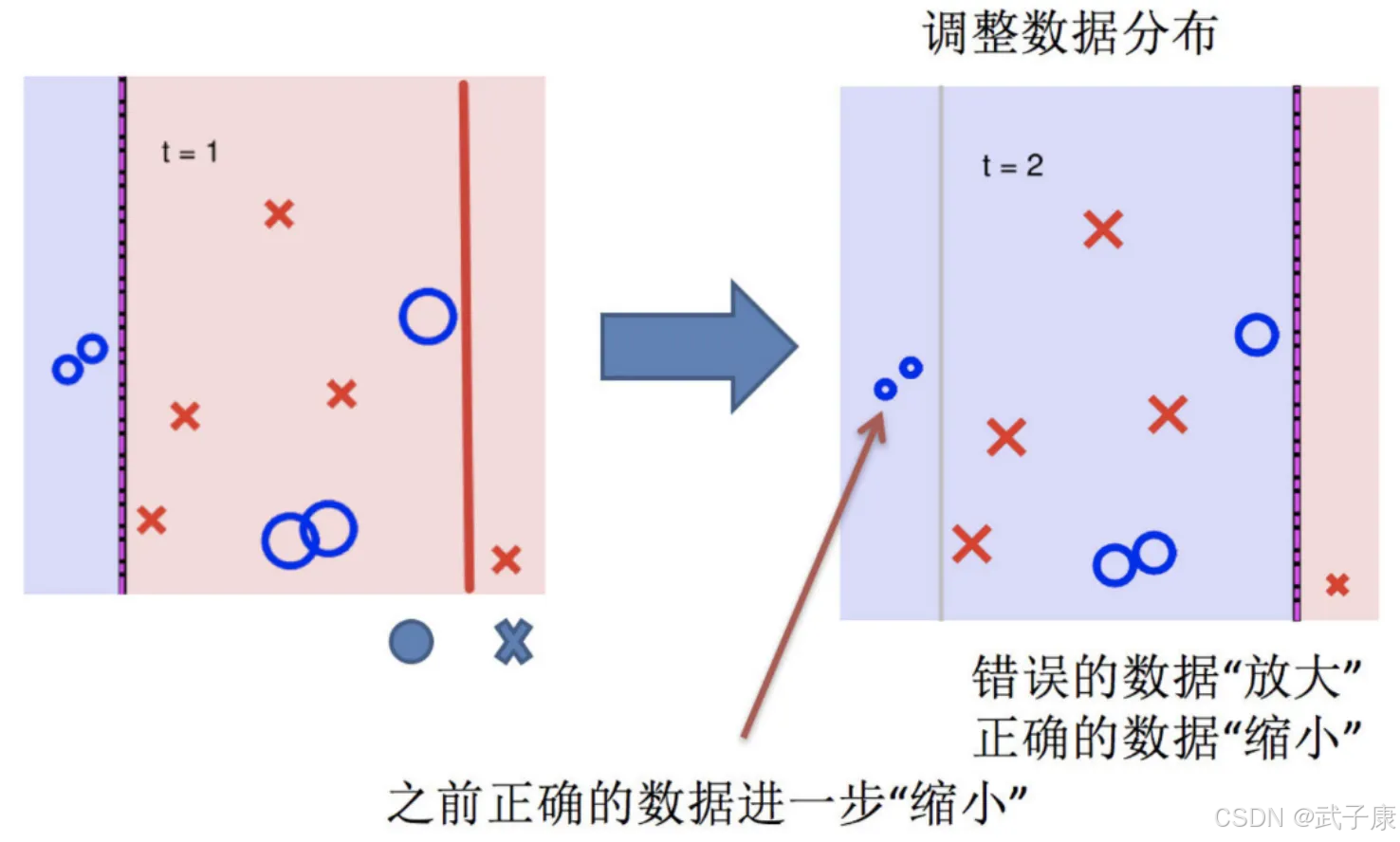
学习器训练及数据分布调整
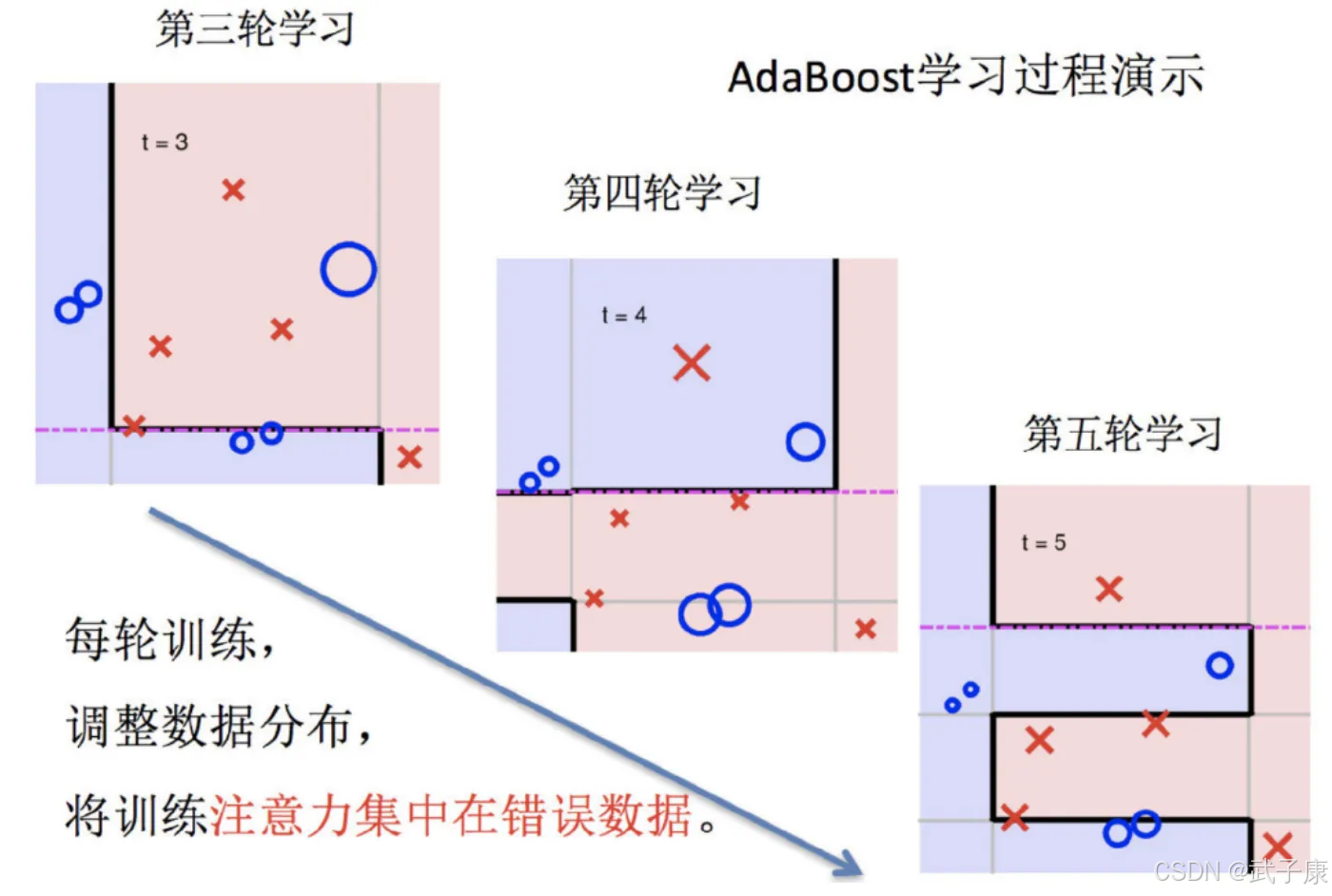
整体过程