境外网站服务器舆情信息网
摘要:近期,大型视觉-语言模型(LVLMs)在具身任务规划方面展现出了巨大潜力,但仍面临着依赖约束和效率等基本挑战。现有方法要么仅优化动作选择,要么在推理过程中利用世界模型,却忽视了学习世界建模作为增强规划能力的一种途径所带来的好处。我们提出了双偏好优化(D2PO的方法显著优于现有方法和GPT-4o,实现了更高的任务成功率,且执行路径更为高效。Huggingface链接:Paper page,论文链接:2503.10480
研究背景和目的
研究背景
随着人工智能技术的不断进步,尤其是大型视觉-语言模型(LVLMs)的兴起,为具身任务规划(Embodied Task Planning)领域带来了新的可能性。具身任务规划是指AI系统能够在物理环境中执行实际任务,这要求AI不仅具备正确执行动作的能力,还需具备对环境的动态变化进行理解和预测的能力。然而,尽管LVLMs在理解和生成自然语言方面取得了显著进展,但它们在具身任务规划中仍面临诸多挑战。
传统的具身任务规划方法往往依赖于环境元数据或外部对象检测模型,这些方法在实际应用中的灵活性和鲁棒性有限。此外,这些方法大多只关注从状态到动作的直接映射,而没有充分考虑动作执行后的后果,这导致了它们在处理复杂依赖关系和执行效率方面的不足。
另一方面,虽然一些方法尝试将LVLMs直接用作世界模型来指导搜索路径,但这些方法要么在训练过程中没有融入世界建模目标,要么在推理过程中引入了额外的计算开销,从而限制了其性能。因此,如何有效地将世界建模融入LVLMs的训练过程中,以提高其具身任务规划能力,成为了一个亟待解决的问题。
研究目的
针对上述挑战,本研究旨在提出一种新颖的学习框架——双偏好优化(Dual Preference Optimization, D²PO),通过同时优化状态预测和动作选择,使LVLMs能够更好地理解环境动态,从而提高其在具身任务规划中的表现。具体而言,本研究的目的包括:
- 提出D²PO框架:通过偏好学习同时优化状态预测和动作选择,使LVLMs能够在训练过程中学习到环境动态,从而增强其在具身任务规划中的能力。
- 自动收集训练数据:设计一种树搜索机制,通过试错法自动收集轨迹和逐步偏好数据,以消除对人工标注的依赖。
- 验证方法有效性:在具身任务规划基准测试集VoTa-Bench上进行实验,验证D²PO框架在多个评价指标上的表现,包括任务成功率和执行路径效率。
研究方法
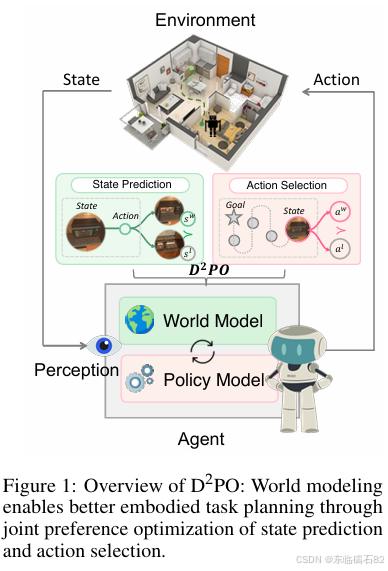
D²PO框架
D²PO框架的核心思想是通过偏好学习同时优化状态预测和动作选择。具体而言,该框架包括两个主要部分:
- 状态预测:给定当前状态和动作,模型预测执行该动作后的下一个状态,从而学习到动作对环境状态的影响。
- 动作选择:基于目标、历史状态和观察,模型选择最合适的动作,以实现任务目标。
通过同时优化这两个方面,D²PO框架使LVLMs能够在训练过程中逐渐形成对环境动态的理解,从而在具身任务规划中做出更明智的决策。
数据收集
为了训练D²PO框架,需要收集大量的轨迹和逐步偏好数据。然而,传统的人工标注方法不仅耗时费力,而且难以保证数据的多样性和质量。因此,本研究提出了一种树搜索机制,通过试错法自动收集这些数据。
具体而言,该机制首先通过混合评分机制对潜在动作进行采样和评估,然后根据评估结果迭代地扩展搜索树。一旦达到目标状态,就通过回溯轨迹来构造用于双优化的动作选择和状态预测的偏好对。
模型训练
在收集到足够的训练数据后,使用这些数据对LVLMs进行训练。训练过程中,采用偏好学习的方法同时优化状态预测和动作选择。通过不断迭代训练,模型逐渐学习到环境动态,并能够在新的任务场景中做出更准确的规划和决策。
研究结果
实验设置
本研究在具身任务规划基准测试集VoTa-Bench上进行了实验。VoTa-Bench是基于AI2-THOR模拟环境构建的,包含多种具身任务类型,如检查与照明、拾取与放置、堆叠与放置等。为了验证D²PO框架的有效性,本研究选择了三种不同的LVLMs作为实验对象:Qwen2-VL(7B)、LLaV A-1.6(7B)和LLaMA-3.2(11B)。
实验结果
实验结果表明,D²PO框架在多个评价指标上均显著优于现有方法和GPT-4o。具体而言:
- 任务成功率:D²PO框架在多个任务类型上均实现了更高的任务成功率,表明其能够更好地理解和处理复杂的任务场景。
- 执行路径效率:D²PO框架在执行路径效率方面也表现出色,能够在更短的时间内完成任务,从而提高了整体性能。
- 泛化能力:在未见过的场景中进行测试时,D²PO框架仍然能够保持较高的任务成功率和执行路径效率,表明其具有良好的泛化能力。
此外,本研究还通过消融实验验证了D²PO框架中各个组件的有效性,并进一步分析了不同因素对模型性能的影响。
研究局限
尽管D²PO框架在具身任务规划中取得了显著进展,但仍存在一些局限性:
- 模拟到现实的差距:目前的研究主要在模拟环境中进行训练和测试,而现实世界中的环境动态和复杂性往往更高。因此,如何将D²PO框架应用于现实世界中的具身任务规划仍是一个挑战。
- 数据收集效率:虽然本研究提出了一种自动收集训练数据的方法,但数据收集过程仍然需要消耗大量的计算资源。如何提高数据收集效率是未来的一个研究方向。
- 模型可解释性:D²PO框架通过偏好学习同时优化状态预测和动作选择,这使得模型在一定程度上缺乏可解释性。如何提高模型的可解释性以便更好地理解和优化其性能是另一个值得研究的问题。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面展开:
- 模拟到现实的迁移:探索将D²PO框架从模拟环境迁移到现实世界中的方法,如通过增强现实(AR)或虚拟现实(VR)技术进行训练数据的收集和模型的验证。
- 高效数据收集方法:研究更高效的数据收集方法,如通过强化学习或自我监督学习来减少数据收集过程中的计算资源消耗。
- 模型可解释性增强:开发新的技术来提高D²PO框架的可解释性,如通过可视化技术来展示模型在状态预测和动作选择过程中的决策过程。
此外,还可以进一步研究如何将D²PO框架与其他先进技术相结合,如多模态融合、知识图谱等,以进一步提升其在具身任务规划中的性能和应用前景。