保养车哪个网站做的好南通百度网站快速优化

♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨ 个人主页✨✨✨✨✨✨
上一篇博客我们提到了二叉搜索树的概念以及实现,这一篇博客我们来看看二叉搜索树(Binary Search Tree, BST)在两种不同使用场景下的应用~准备好了吗~我们发车去探索C++的奥秘啦~🚗🚗🚗🚗🚗🚗
目录
key搜索场景
key搜索场景应用示例:图书馆图书管理系统
代码实现
key/value搜索场景
key/value搜索场景应用示例:简单中英互译字典
代码实现
测试
计数问题
二叉搜索树(Binary Search Tree, BST)有两种不同使用场景下的应用:一种是仅使用关键码(key)的搜索场景,另一种是使用关键码和值(key/value)的搜索场景。
key搜索场景
- 特点:在这种场景中,二叉搜索树中只存储关键码(key),每个关键码代表需要搜索到的值。这种结构主要用于判断某个key是否存在于树中。
- 操作:支持增加、删除和查找操作。然而,这种结构不支持直接修改key,因为修改key可能会破坏二叉搜索树的性质(即左子树所有节点的值小于根节点,右子树所有节点的值大于根节点)。
- 限制:虽然每个key都有一个与之对应的值(value),但在这种结构中并不存储value,只关注key的存在性。
key搜索场景应用示例:图书馆图书管理系统
图书馆图书管理系统需要高效地管理大量的图书信息,包括图书的编号(ISBN)、书名、作者、出版信息等。在这个系统中,我们可以使用二叉搜索树(BST)来存储图书的编号(作为key),而不直接存储其他详细信息(这些信息可以存储在数据库或其他数据结构中,并通过编号进行关联)。这里,我们主要关注图书编号的快速查找功能。
代码实现
这个场景代码事实上,在上一篇博客就已经实现了,我们这里把它拿过来~为了更好地与后面的场景进行区分,我们这里使用命名空间~
namespace Tree_key
{template<class T>struct BSTreeNode//定义一个树结点{T _key;BSTreeNode<T>* _left;BSTreeNode<T>* _right;BSTreeNode(const T& key)//构造:_key(key),_left(nullptr),_right(nullptr){}};//二叉搜索树的实现template<class T>class BSTree{typedef BSTreeNode<T> Node;private://根节点Node* _root = nullptr;public://析构函数~BSTree(){Destory(_root);_root = nullptr;}void Destory(Node* root){if (root == nullptr){return;}else{Destory(root->_left);Destory(root->_right);delete root;}}bool insert(const T& key){//判断树是否为空if (_root == nullptr){_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;//遍历树找到应该插入的位置while (cur){if (key < cur->_key)//如果比当前节点数小,说明在当前节点的左子树{parent = cur;cur = cur->_left;}else if (key > cur->_key)//如果比当前节点数大,说明在当前节点的右子树{parent = cur;cur = cur->_right;}else//如果相等就不进行插入{return false;}}//cur 已经走到为空cur = new Node(key);//与自己的父节点进行比较if (key > parent->_key){parent->_right = cur;}else if (key < parent->_key){parent->_left = cur;}return true;}void InPrint(){_InPrint(_root);cout << endl;}void _InPrint(Node* root){if (root == nullptr){return;}_InPrint(root->_left);cout << root->_key << " ";_InPrint(root->_right);}Node* Find(const T& x){if (_root == nullptr){return nullptr;}Node* cur = _root;//遍历查找while (cur){if (x < cur->_key)//如果比当前节点数小,说明在当前节点的左子树{cur = cur->_left;}else if (x > cur->_key)//如果比当前节点数大,说明在当前节点的右子树{cur = cur->_right;}else//如果相等就找到了{return cur;}}//走到空也没有找到return nullptr;}bool erase(const T& key){//处理根节点就为空的情况if (_root == nullptr){return false;}//遍历查找元素Node* cur = _root;Node* parent = _root;while (cur){if (key < cur->_key){parent = cur;cur = cur->_left;}else if (key > cur->_key){parent = cur;cur = cur->_right;}else{//while循环里面进行删除//1、节点cur有右子节点但没有左子节点if (cur->_left == nullptr){if (cur == _root){_root = cur->_right;}else if (cur == parent->_left){parent->_left = cur->_right;}else if (cur == parent->_right){parent->_right = cur->_right;}delete cur;}//2、节点cur有左子节点但没有右子节点else if (cur->_right == nullptr){if (cur == _root){_root = cur->_left;}else if (cur == parent->_left){parent->_left = cur->_left;}else if (cur == parent->_right){parent->_right = cur->_left;}delete cur;}//3.节点cur有左右子节点else{//这里我们找找右边节点的最小值进行替换Node* replaceParent = cur;Node* Rmin = cur->_right;//找右边节点的最小值while (Rmin->_left){replaceParent = Rmin;Rmin = Rmin->_left;}swap(Rmin->_key, cur->_key);if (replaceParent->_left == Rmin)//Rmin结点就是最小的,所以当前结点肯定没有左结点//需要处理Rmin节点的右结点{replaceParent->_left = Rmin->_right;}else if (replaceParent->_right == Rmin){replaceParent->_right = Rmin->_right;}delete Rmin; }return true;}}//如果找到空都没有找到进行返回,说明没有相应结点return false;}};
}key/value搜索场景
- 特点:在这种场景中,二叉搜索树的每个节点不仅存储关键码(key),还存储与之对应的值(value)。这种结构允许通过key快速找到对应的value。
- 操作:同样支持增加、删除和查找操作,且可以通过key快速定位到对应的value。此外,这种结构还支持修改value,因为修改value不会破坏二叉搜索树的性质。
- 限制:虽然支持修改value,但不允许修改key。修改key同样会破坏二叉搜索树的性质,导致树的结构不再满足搜索条件。
key/value搜索场景应用示例:简单中英互译字典
- 描述:在这个例子中,二叉搜索树的每个节点存储一个英文单词(作为key)和对应的中文翻译(作为value)。
- 操作:当用户输入一个英文单词时,可以通过在二叉搜索树中查找该单词(key),快速找到对应的中文翻译(value)。
- 优势:利用二叉搜索树的性质,可以高效地实现字典的查找、增加和删除操作,提高程序的运行效率。
代码实现
key场景和key/value场景都是通过二叉搜索树进行实现的,事实上,这里的代码与前面的差不多~部分地方需要进行修改~比如模板参数应该是两个了~
namespace Tree_key_value
{template<class T,class V>//两个模板参数struct BSTreeNode//定义一个树结点{T _key;V _value;BSTreeNode<T, V>* _left;BSTreeNode<T, V>* _right;BSTreeNode(const T& key, const V& value)//构造:_key(key),_value(value),_left(nullptr),_right(nullptr){}};//二叉搜索树的实现——key/value场景template<class T,class V>class BSTree{typedef BSTreeNode<T, V> Node;private://根节点Node* _root = nullptr;public://析构函数~BSTree(){Destory(_root);_root = nullptr;}void Destory(Node* root){if (root == nullptr){return;}else{Destory(root->_left);Destory(root->_right);delete root;}}bool insert(const T& key,const V& value){//判断树是否为空if (_root == nullptr){_root = new Node(key, value);return true;}Node* parent = nullptr;Node* cur = _root;//遍历树找到应该插入的位置while (cur){if (key < cur->_key)//如果比当前节点数小,说明在当前节点的左子树{parent = cur;cur = cur->_left;}else if (key > cur->_key)//如果比当前节点数大,说明在当前节点的右子树{parent = cur;cur = cur->_right;}else//如果相等就不进行插入{return false;}}//cur 已经走到为空cur = new Node(key, value);//与自己的父节点进行比较if (key > parent->_key){parent->_right = cur;}else if (key < parent->_key){parent->_left = cur;}return true;}void InPrint(){_InPrint(_root);cout << endl;}void _InPrint(Node* root){if (root == nullptr){return;}_InPrint(root->_left);cout << root->_key << "——" << root->_value << endl;_InPrint(root->_right);}Node* Find(const T& x){if (_root == nullptr){return nullptr;}Node* cur = _root;//遍历查找while (cur){if (x < cur->_key)//如果比当前节点数小,说明在当前节点的左子树{cur = cur->_left;}else if (x > cur->_key)//如果比当前节点数大,说明在当前节点的右子树{cur = cur->_right;}else//如果相等就找到了{return cur;}}//走到空也没有找到return nullptr;}bool erase(const T& key){//处理根节点就为空的情况if (_root == nullptr){return false;}//遍历查找元素Node* cur = _root;Node* parent = _root;while (cur){if (key < cur->_key){parent = cur;cur = cur->_left;}else if (key > cur->_key){parent = cur;cur = cur->_right;}else{//while循环里面进行删除//1、节点cur有右子节点但没有左子节点if (cur->_left == nullptr){if (cur == _root){_root = cur->_right;}else if (cur == parent->_left){parent->_left = cur->_right;}else if (cur == parent->_right){parent->_right = cur->_right;}delete cur;}//2、节点cur有左子节点但没有右子节点else if (cur->_right == nullptr){if (cur == _root){_root = cur->_left;}else if (cur == parent->_left){parent->_left = cur->_left;}else if (cur == parent->_right){parent->_right = cur->_left;}delete cur;}//3.节点cur有左右子节点else{//这里我们找找右边节点的最小值进行替换Node* replaceParent = cur;Node* Rmin = cur->_right;//找右边节点的最小值while (Rmin->_left){replaceParent = Rmin;Rmin = Rmin->_left;}swap(Rmin->_key, cur->_key);if (replaceParent->_left == Rmin)//Rmin结点就是最小的,所以当前结点肯定没有左结点//需要处理Rmin节点的右结点{replaceParent->_left = Rmin->_right;}else if (replaceParent->_right == Rmin){replaceParent->_right = Rmin->_right;}delete Rmin;}return true;}}//如果找到空都没有找到进行返回,说明没有相应结点return false;}};
}测试
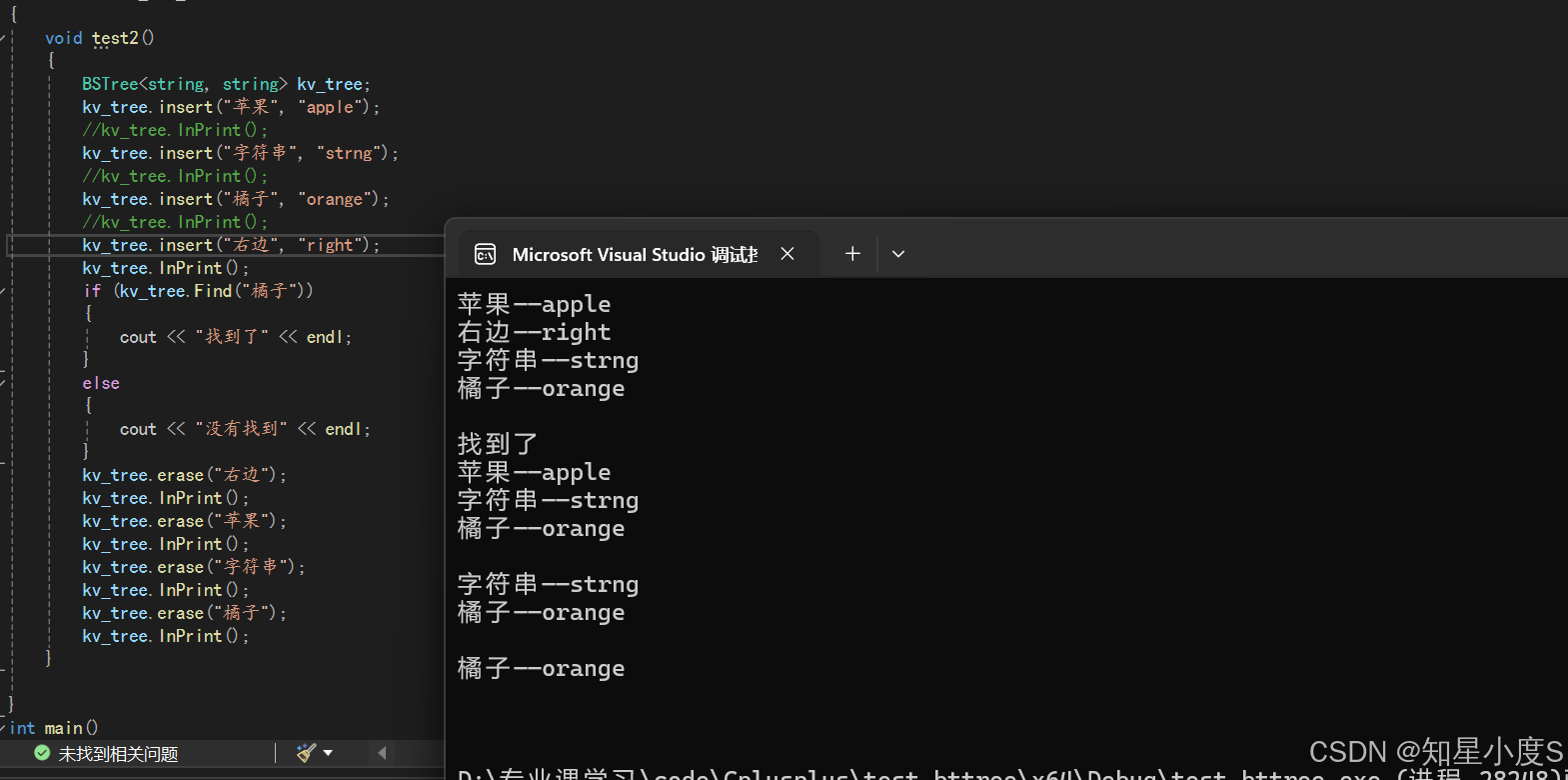
void test2()
{BSTree<string, string> kv_tree;kv_tree.insert("苹果", "apple");//kv_tree.InPrint();kv_tree.insert("字符串", "strng");//kv_tree.InPrint();kv_tree.insert("橘子", "orange");//kv_tree.InPrint();kv_tree.insert("右边", "right");kv_tree.InPrint();if (kv_tree.Find("橘子")){cout << "找到了" << endl;}else{cout << "没有找到" << endl;}kv_tree.erase("右边");kv_tree.InPrint();kv_tree.erase("苹果");kv_tree.InPrint();kv_tree.erase("字符串");kv_tree.InPrint();kv_tree.erase("橘子");kv_tree.InPrint();
}
计数问题
接下来我们来看看使用二叉搜索树处理计数问题~
思路
我们要使用二叉搜索树(BSTree)对字符串数组中的元素进行计数。首先,遍历数组中的每个元素,对于每个元素,先在二叉搜索树中查找是否存在。若不存在,则在树中插入该元素,并设置其计数为1;若已存在,则将该元素的计数加1。遍历完成后,所有元素的计数都被正确记录在二叉搜索树中。最后,通过调用
InPrint方法,以中序遍历的方式打印出树中的元素及其计数,展示了数组中每个字符串出现的次数~
代码实现
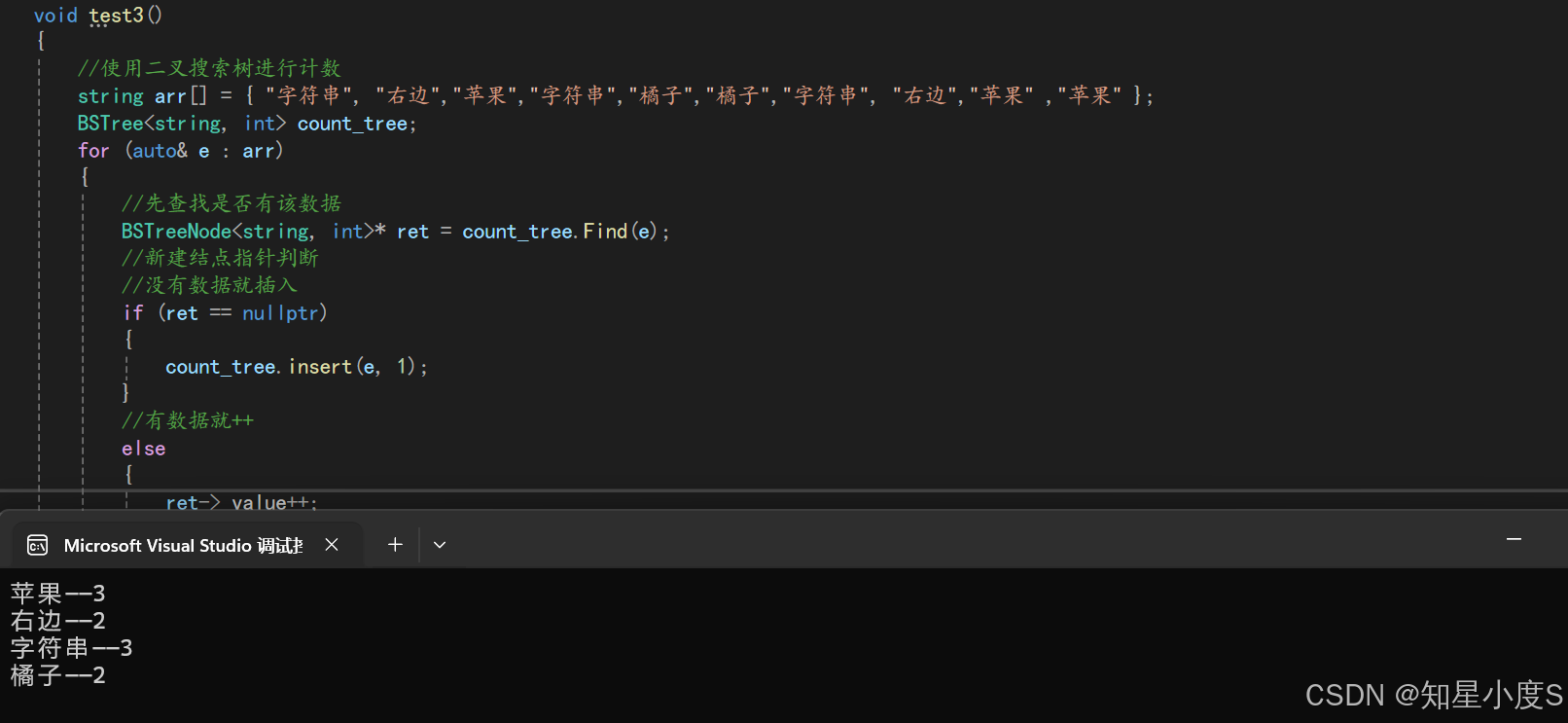
//使用二叉搜索树进行计数
string arr[] = { "字符串", "右边","苹果","字符串","橘子","橘子","字符串", "右边","苹果" ,"苹果" };
BSTree<string, int> count_tree;
for (auto& e : arr)
{//先查找是否有该数据BSTreeNode<string, int>* ret = count_tree.Find(e);//新建结点指针判断//没有数据就插入if (ret == nullptr){count_tree.insert(e, 1);}//有数据就++else{ret->_value++;}
}
count_tree.InPrint();运行结果
这让我们深刻体会到了二叉搜索树的魅力~
二叉搜索树(BST)这样一种高效的数据结构,支持快速的查找、插入和删除操作。其结构特性确保每个节点的左子树值均小于该节点,而右子树值均大于该节点,从而实现了对数级别O(log n)的时间复杂度。BST不仅能有效管理数据,还能通过中序遍历直接生成有序序列,省去了额外的排序步骤。凭借其卓越的性能和灵活性,BST在数据库索引、文件系统及编译器符号表等领域发挥着关键作用,极大地提升了数据处理效率和准确性。
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨