低多边形网站广西网站seo
Redis中的set底层实现:从数据结构到性能优化
今天我们来深入探讨Redis中set数据类型的底层实现。就像我们日常生活中使用的收纳盒一样,Redis的set就是一个高效存储无序、唯一元素的"容器"。想象一下,当你需要快速判断某个物品是否在收纳盒中,或者需要找出多个收纳盒中共有的物品时,Redis的set就能大显身手了。
在实际开发中,我们经常使用set来实现用户标签系统、共同好友计算、UV统计等功能。但你是否好奇过,为什么Redis的set能如此高效地完成这些操作?今天,我们就一起来揭开它的神秘面纱,了解其底层实现原理。
一、Redis set的基本特性
理解了set的应用场景后,我们来看看它的基本特性。Redis的set是一个无序的字符串集合,它保证了元素的唯一性,即同一个set中不会出现重复的元素。这与数学中的集合概念非常相似。
set支持多种高效操作,包括添加、删除元素,判断元素是否存在,以及集合间的并集、交集、差集运算等。这些操作的时间复杂度通常都是O(1)或O(N),其中N是参与运算的集合元素数量。
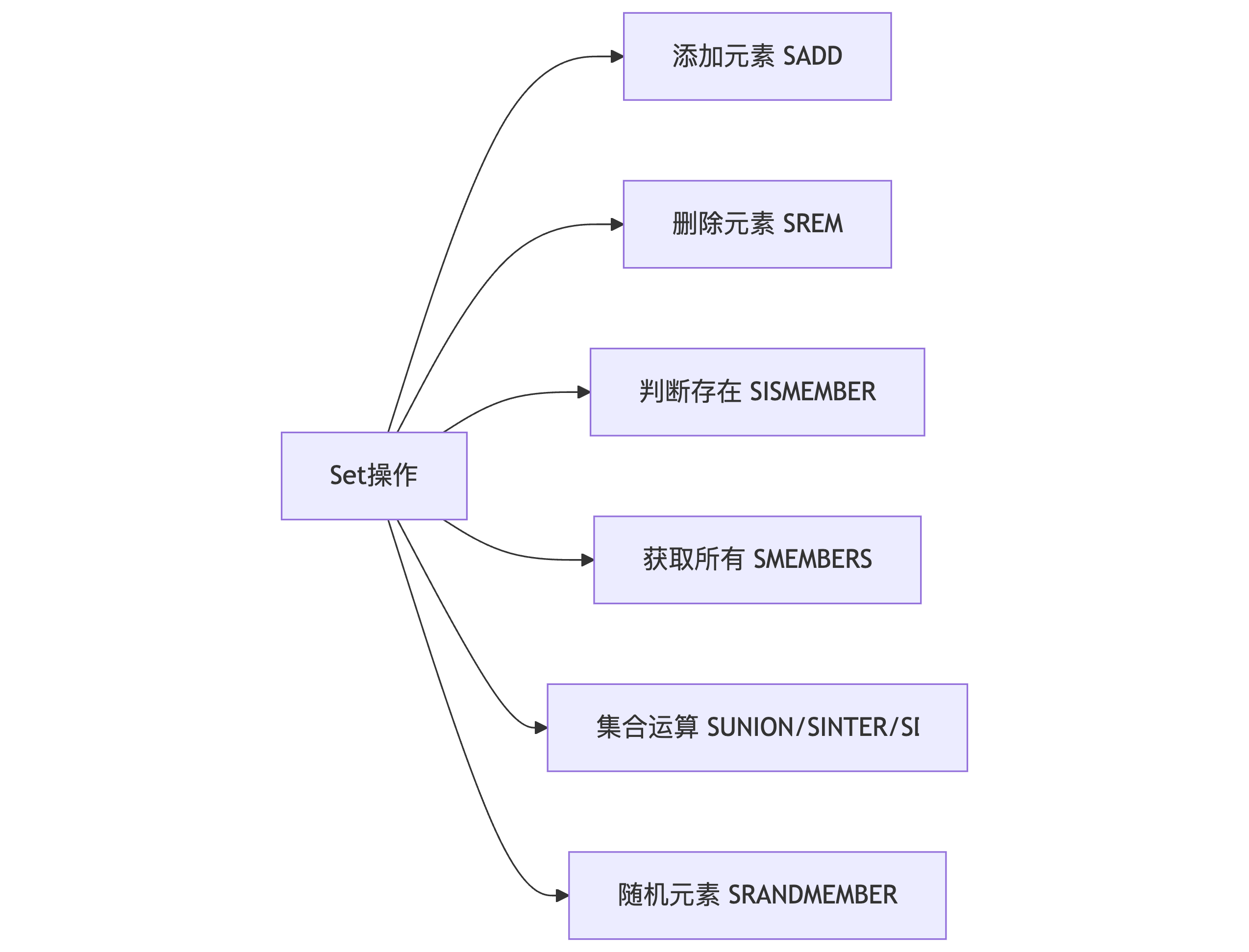
以上流程图说明了Redis set支持的主要操作类型,包括元素操作和集合运算两大类。值得注意的是,Redis set还提供了获取随机元素的功能,这在实现抽奖等场景时非常有用。
二、set的底层数据结构
了解了set的基本操作后,我们深入探讨它的底层实现。Redis的set并不是使用单一数据结构实现的,而是根据元素数量和元素大小动态选择最合适的存储结构。这种智能的选择机制正是Redis高效的关键所在。
1. intset(整数集合)
当set中所有元素都是整数且元素数量较少时,Redis会使用intset来存储。intset是专门为存储整数设计的一种紧凑数据结构,它有以下特点:
- 元素按从小到大顺序存储,便于二分查找
- 不会出现重复元素
- 根据元素大小自动选择16位、32位或64位存储
- 内存占用小,访问效率高
typedef struct intset {uint32_t encoding; // 编码方式:INTSET_ENC_INT16/32/64uint32_t length; // 元素个数int8_t contents[]; // 元素数组
} intset;
上述代码展示了intset的结构定义,它通过encoding字段动态调整存储每个整数所需的字节数,从而节省内存空间。例如,当所有元素都小于32767时,使用INTSET_ENC_INT16编码,每个元素只需2字节。
2. hashtable(哈希表)
当set中的元素不满足intset条件时(比如包含非整数元素或元素数量超过阈值),Redis会自动将底层实现转换为hashtable。Redis的hashtable实现有以下特点:
- 使用链地址法解决哈希冲突
- 渐进式rehash机制保证性能
- 自动扩容和缩容
- 支持任意类型的元素
hashtable的结构大致如下:
typedef struct dict {dictType *type; // 类型特定函数void *privdata; // 私有数据dictht ht[2]; // 两个哈希表,用于rehashlong rehashidx; // rehash进度,-1表示未进行unsigned long iterators; // 当前正在运行的迭代器数量
} dict;
上述代码是Redis字典结构的定义,set在底层就是使用这种结构实现的。注意到它包含两个哈希表(ht[2]),这是为了实现渐进式rehash而设计的。当进行rehash时,数据会逐步从ht[0]迁移到ht[1],避免一次性迁移导致性能下降。
三、set的自动转换机制
了解了两种底层结构后,我们来看看Redis如何在这两者之间做出选择。Redis的设计非常智能,它会根据实际情况自动选择最合适的存储结构。
set的转换规则如下:
-
当满足以下所有条件时,使用intset:
- 所有元素都是整数
- 元素数量小于
set-max-intset-entries配置值(默认512) - 所有元素的大小不超过当前intset的编码范围
-
当不满足上述任一条件时,转换为hashtable
配置建议: set-max-intset-entries的默认值是512,如果你的应用场景中整数集合元素数量通常较大,可以适当调大这个值以获得更好的内存效率。但要注意,过大的intset在查找性能上会有所下降。可以通过以下命令查看和设置:
# 查看当前配置
CONFIG GET set-max-intset-entries# 设置新值
CONFIG SET set-max-intset-entries 1024
四、set操作的实现原理
现在我们已经知道set的底层结构,接下来看看常见操作在这些结构上是如何实现的。
1. 添加元素(SADD)
添加元素时,Redis会根据当前底层结构执行不同操作:
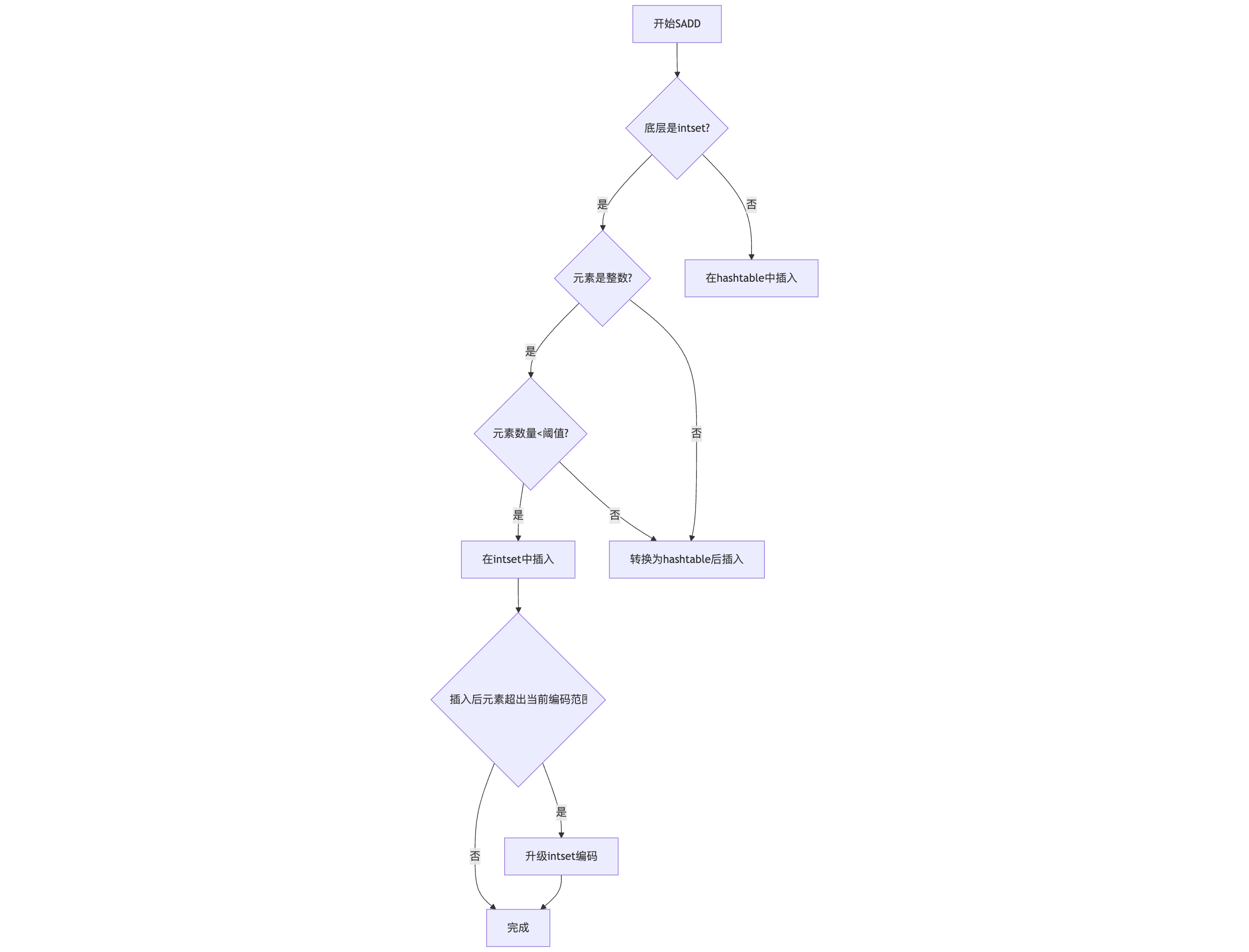
以上流程图详细说明了SADD命令的执行流程。值得注意的是,intset在插入元素时可能会触发编码升级,例如从16位升级到32位,这个过程会重新分配内存并迁移所有元素。
2. 查找元素(SISMEMBER)
查找元素是否存在时,两种结构的处理方式不同:
-
intset:使用二分查找,时间复杂度O(logN)
- 首先检查元素类型是否匹配
- 然后进行二分查找
-
hashtable:计算哈希值直接定位,平均时间复杂度O(1)
- 计算key的哈希值
- 定位到哈希桶
- 遍历链表查找匹配元素
3. 集合运算(SINTER/SUNION/SDIFF)
集合运算的实现相对复杂,Redis采用了以下策略:
- 对于小集合,使用简单的嵌套循环实现
- 对于大集合,使用更高效的算法优化
- 交集运算会先对较小的集合进行遍历
- 并集和差集运算则需要遍历所有相关集合
- 结果集的大小会被预先估算以优化内存分配
性能注意: 集合运算的时间复杂度通常是O(N*M),其中N和M是参与运算的集合大小。对于大型集合,这些操作可能会阻塞Redis较长时间,在生产环境中应谨慎使用。建议:
- 对大集合的运算放在从库执行
- 考虑使用SCAN命令分批处理
- 在客户端实现部分集合运算逻辑
五、set的应用场景与优化建议
了解了set的内部实现后,我们来看看如何在实际应用中更好地利用它。
1. 典型应用场景
- 标签系统:为用户打标签,方便分类和检索
# 为用户添加标签 SADD user:1000:tags technology programming redis# 查找有特定标签的用户 SINTER tag:technology:users tag:redis:users - 共同好友/兴趣:通过SINTER计算两个用户的共同好友
- 唯一性保证:利用set自动去重的特性,如记录用户IP
- 随机元素:使用SRANDMEMBER实现抽奖等随机选择功能
- 数据过滤:快速判断元素是否存在,如敏感词过滤
2. 优化建议
根据set的实现原理,我们可以采取以下优化措施:
- 合理使用整数元素:在可能的情况下,使用整数而非字符串作为元素,以便利用intset节省内存
# 使用数字ID而非字符串 SADD article:100:likes 1234 5678 9012 # 好 SADD article:100:likes "user:1234" "user:5678" # 差 - 控制集合大小:避免单个set过大,可以考虑分片存储
# 分片存储大集合 SADD users:part1 user1 user2 ... user1000 SADD users:part2 user1001 user1002 ... user2000 - 慎用集合运算:对于大型集合的交并差运算,考虑在客户端实现或使用专门的搜索系统
- 监控内存使用:定期检查set的内存占用,防止内存泄漏
- 合理设置配置:根据实际情况调整
set-max-intset-entries等参数
# 监控set内存使用示例
# 查找大key
redis-cli --bigkeys# 查看特定key的内存使用
redis-cli memory usage user:1000:tags# 查看key的编码类型
redis-cli object encoding user:1000:tags
上述代码是监控Redis内存使用的实用命令,object encoding命令特别有用,可以查看一个set当前使用的是intset还是hashtable编码。
六、总结
通过今天的探讨,我们深入了解了Redis set的底层实现机制。以下是本文的主要内容回顾:
- 基本特性:Redis set是无序、唯一元素的集合,支持高效的元素操作和集合运算
- 底层结构:根据元素类型和数量,自动选择intset或hashtable作为存储结构
- 转换机制:当元素不再满足intset条件时,自动转换为hashtable
- 操作实现:不同操作在不同结构上有不同的实现方式和时间复杂度
- 应用优化:根据实现原理,合理设计数据结构和操作方式
Redis的set之所以高效,正是因为它能够根据实际情况智能选择最优的存储结构。作为开发者,理解这些底层机制有助于我们更好地使用Redis,设计出更高效的应用系统。
关键收获:
- intset适合存储小规模的整数集合,内存效率高
- hashtable支持任意元素类型和大规模集合
- 集合运算要谨慎使用,特别是对大集合
- 监控和调优是保证Redis性能的关键
希望今天的分享能帮助大家更深入地理解Redis set的工作原理。如果你在实际使用中遇到任何问题,或者有更好的优化建议,欢迎随时交流讨论。让我们共同进步,不断探索Redis的更多可能性!